
发布日期: 2025-05-02 16:54:58
数字时代催生了海量文件存储需求,压缩工具成为提升效率的关键装备。ZIP、7Z、TAR作...

发布日期: 2025-05-23 15:19:27
在数字信息爆炸的时代,设计师、电商运营、自媒体编辑等群体经常面临图片素材收集...

发布日期: 2025-05-05 09:31:32
现代人习惯在手机、平板碎片化阅读,但刺眼的屏幕光线与频繁的信息干扰让深度阅读...

发布日期: 2025-04-11 17:45:26
当代办公环境中,ZIP和7z格式的压缩文件已成为跨平台传输的标准载体。面对动辄上百...

发布日期: 2025-04-11 13:02:46
在互联网数据爆炸式增长的今天,如何快速准确抓取目标URL链接成为许多开发者和数据...

发布日期: 2025-03-24 09:21:44
无论是出差旅行、探亲访友,还是单纯关注全球气候变化,天气预报始终是日常生活的...

发布日期: 2025-05-22 11:22:44
阳光斜照进书房时,桌面上那款蓝白配色的计算器应用总让人忍不住想戳两下。作为程...

发布日期: 2025-03-24 12:29:16
现代家庭对应急管理的需求日益提升,一款支持CSV格式的家庭应急联系人管理工具,正...

发布日期: 2025-04-17 15:46:05
在数据安全防护领域,敏感信息泄露如同潜伏的暗礁,稍有不慎便会导致企业声誉受损...

发布日期: 2025-03-21 09:13:15
在网络数据采集领域,高效获取YouTube平台视频信息始终是开发者关注的焦点。一款支持...

发布日期: 2025-05-18 17:46:16
在Python生态中,Tkinter作为标准GUI工具包,常被开发者用来构建简单的桌面应用。下面展...

发布日期: 2025-03-24 09:27:55
正则表达式在数据处理领域的应用由来已久,其精准匹配特性使其成为日期格式处理的...
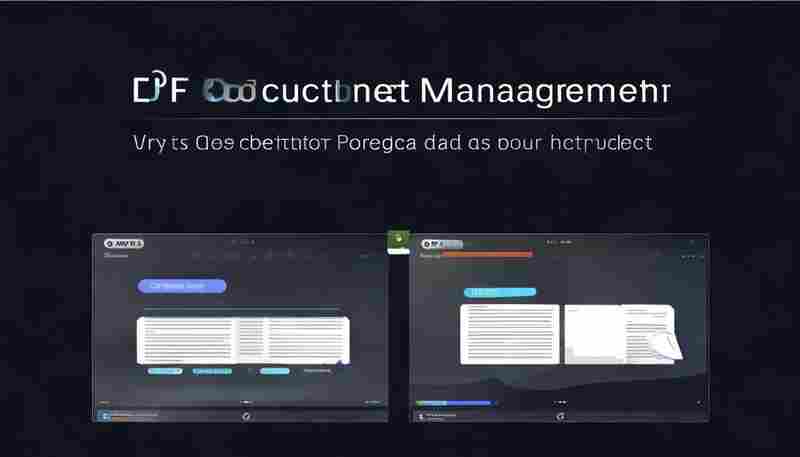
发布日期: 2025-05-01 13:40:10
日常办公场景中,PDF文档的灵活处理始终是职场人士的痛点。当需要提取合同关键条款...

发布日期: 2025-05-12 09:47:28
在数字化办公与景中,频繁的鼠标点击操作往往成为效率瓶颈。无论是批量处理文件、...
发布日期: 2025-03-24 09:40:54
当互联网下载成为日常习惯,如何验证文件的完整性与安全性成为刚需。某款名为Has...

发布日期: 2025-04-29 16:33:21
日常文件传输中,大体积文件常会遇到存储介质容量限制或网络传输瓶颈。传统压缩软...

发布日期: 2025-05-02 12:30:22
在信息爆炸的办公场景中,凌乱的纸质便签逐渐被数字化工具取代。桌面便签贴纸应用...
发布日期: 2025-05-10 19:41:21
在信息碎片化的时代,结构化思维成为刚需。一款名为 QuickFlow 的流程图工具,凭借极...

发布日期: 2025-04-13 13:00:40
压缩文件已成为数字生活中不可或缺的存储形式。面对各类ZIP格式文档,一款得心应手...

发布日期: 2025-03-26 16:52:40
在信息过载的时代,人们每天需要处理的任务往往横跨工作、生活、学习等多个维度。...
发布日期: 2025-05-13 12:13:16
办公室电脑存储着三万份文档的设计师小王,曾因找不到半年前的投标方案险些错过项...

发布日期: 2025-04-06 11:26:18
当设计师反复调整配色方案时,当开发者调试CSS样式时,当摄影爱好者处理后期调色时...

发布日期: 2025-03-30 10:04:35
【深度解析】支持SSML的TSS脚本编辑器:语音交互开发者的新利器 在语音交互技术快速...

发布日期: 2025-05-27 12:06:48
在互联网账户安全管理中,密码强度检测器已成为各类平台的标配工具。某科技公司研...

发布日期: 2025-05-12 14:06:34
市面上一款名为"QuickCanvas"的绘图工具近期吸引了设计新手的注意。这款支持Windows/Mac双...

发布日期: 2025-03-26 10:28:14
几何图形与色彩的结合,构成了现代视觉设计的底层逻辑。Adobe Illustrator、CorelDRAW等专...

发布日期: 2025-05-28 11:24:31
在信息爆炸的时代,如何快速从海量文本中定位关键内容成为刚需。一款名为 「简易文...

发布日期: 2025-04-28 09:16:23
地铁隧道墙壁掠过暖黄光斑时,手机相册自动弹出三个月前拍摄的樱花特写。这款名为...

发布日期: 2025-05-24 19:26:37
Hello World"在黑色终端界面弹出时,程序员们总习惯用星号围成醒目的边框。这种源自上...

发布日期: 2025-05-25 14:01:43
书桌上堆满技术书籍的角落,总少不了一台显示器。显示器旁除了常年温热的马克杯,...

发布日期: 2025-04-01 13:01:52
许多用户初次接触专业绘图软件时,常被复杂的操作界面和冗长的学习曲线劝退。市面...

发布日期: 2025-04-13 13:32:59
在信息爆炸的互联网时代,高效获取结构化数据成为许多行业的核心需求。网页爬虫数...
发布日期: 2025-04-03 14:16:29
阳光透过办公室玻璃斜射在桌面,财务专员张蕊第三次核对报表数据时,发现某栏数字...

发布日期: 2025-04-12 15:09:58
现代人常被琐碎事务淹没,一款优秀的待办事项管理工具如同隐形助手,能帮助用户从...

发布日期: 2025-04-17 16:14:40
日常工作中常遇到这种情况:正与同事讨论项目思路,灵感突然闪现;屏幕右下角弹出...

发布日期: 2025-05-27 13:28:57
在信息爆炸的时代,用户常面临海量文件管理的痛点——重要数据分散在数百个文件夹...
发布日期: 2025-04-28 19:27:02
在跨国律师事务所的深夜会议室里,李律师团队正面临棘手难题:客户提供的合同终版...

发布日期: 2025-04-30 12:51:01
数据安全与存储效率的博弈始终是数字时代的核心命题。当普通用户面对重要合同、私...

发布日期: 2025-05-31 14:21:02
对于需要同时处理多项任务的办公族而言,桌面便签工具如同数字化的便利贴。基于...

发布日期: 2025-05-27 09:50:55
透明背景的九宫格图片切割工具正在成为设计师和内容创作者的新宠。这款工具的核心...

发布日期: 2025-04-02 15:35:50
午后的阳光斜照在咖啡杯边缘,行政助理小林第3次修改会议安排时,电脑突然弹出提醒...

发布日期: 2025-05-23 19:13:42
市面上各类单词记忆工具层出不穷,真正实现灵活数据管理的产品却不多见。近期测试...

发布日期: 2025-05-21 18:50:31
在数字化信息频繁流转的今天,文件传输中的篡改风险始终存在。一款能够快速计算...

发布日期: 2025-05-09 09:18:58
纸质词典泛黄的扉页上,总残留着翻页时留下的折痕。当数字化浪潮席卷语言学习领域...
发布日期: 2025-05-10 11:31:11
办公桌面的混乱文档、摄影师的数千张原始照片、程序员版本迭代的代码文件——这些...
发布日期: 2025-05-25 09:53:49
在数字化办公场景中,多设备协同工作的需求日益增长。面对会议室里频繁切换的手机...

发布日期: 2025-03-27 15:36:02
现代人生活节奏快,待办事项繁杂,如何避免遗漏重要安排?一款支持定时提醒与自定...

发布日期: 2025-05-03 14:35:16
在日常工作中,设计师、产品经理或开发人员常遇到一个痛点:整理海量产品截图时,...

发布日期: 2025-05-24 14:06:48
翻开某论坛技术版块,总能撞见几个技术宅抱团取暖的帖子:"下载的TXT小说不分段怎么...
发布日期: 2025-05-05 11:04:31
对于需要频繁处理文档格式的创作者或开发者来说,纯文本编辑工具Markdown凭借其简洁...
发布日期: 2025-05-27 11:56:04
工作电脑里散落着237份会议纪要时,当设计师要在16GB素材库中定位某个PSD源文件,多数...

发布日期: 2025-04-25 19:58:30
打开设计软件的瞬间,屏幕前的你是否总被那些千篇一律的渐变模板困住手脚?在Dri...
发布日期: 2025-04-24 11:48:30
清晨的咖啡冒起白雾,厨房温度计显示85℃。烘焙师老王盯着屏幕上的法式面包教程,...

发布日期: 2025-04-02 16:43:33
工作室内,摄影师小林正面对上千张拍摄素材发愁——横构图与竖拍作品混杂,部分照...

发布日期: 2025-05-05 18:43:46
许多人初次接触编程时,常会疑惑如何将抽象代码转化为直观成果。Python内置的Turtle模...

发布日期: 2025-04-16 14:33:34
在数字化运维领域,海量日志数据的处理始终是个棘手问题。某企业曾因系统故障排查...
发布日期: 2025-05-02 19:58:32
在信息全球化的今天,跨语言阅读已成为现代人的日常需求。当用户在浏览俄语技术文...

发布日期: 2025-05-06 12:38:47
日志文件如同服务器系统的"病历本",存储着运行状态、异常信息等关键数据。面对动...

发布日期: 2025-05-23 17:44:01
操作界面的左侧是文件导入区,支持拖拽五十余种常见视频格式。当用户将婚礼跟拍素...

发布日期: 2025-04-09 16:32:03
现代计算器早已突破传统数学工具的局限,成为日常生活不可或缺的助手。具备四则运...
