
发布日期: 2025-04-12 15:20:26
在日常数据处理工作中,频繁面对CSV文件与数据库之间的转换需求是许多开发者、数据...

发布日期: 2025-04-22 13:12:42
在数据处理领域,执行效率往往决定着业务系统的成败。某互联网企业的运维团队曾因...
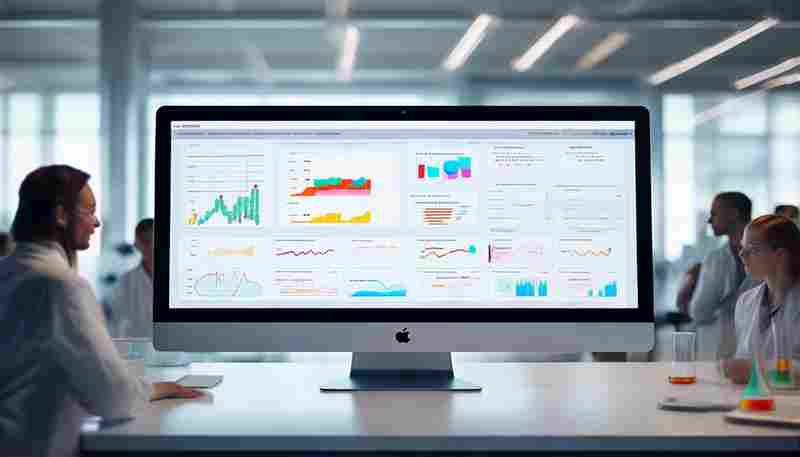
发布日期: 2025-05-13 18:18:47
实验室科研活动产生的数据量近年呈现指数级增长。某材料科学实验室曾因项目进度跟...

发布日期: 2025-03-27 09:21:24
办公区键盘敲击声此起彼伏,开发工程师李明盯着屏幕上成片的SQL查询结果,第3次尝试...

发布日期: 2025-03-30 14:17:44
日常工作中,经常需要快速查看或导出SQLite数据库中的信息。对于非专业开发者而言,...

发布日期: 2025-03-21 12:14:57
在数据管理领域,数据库类型的多样化常导致跨平台协作的复杂性。对于同时依赖轻量...

发布日期: 2025-05-09 17:53:48
在数字身份管理日益重要的今天,密码安全已成为个人与企业无法回避的挑战。据统计...
发布日期: 2025-04-24 17:16:59
数据库查询结果的呈现方式直接影响数据分析效率。MySQL命令行默认的表格输出在遇到...

发布日期: 2025-04-04 12:19:36
随着智能化管理需求增长,二维码门禁系统逐渐取代传统钥匙与IC卡。某科技团队近期...

发布日期: 2025-05-14 09:57:31
在企业级数据管理场景中,SQLite因其嵌入式特性与轻量化优势,成为众多中小型项目的...
发布日期: 2025-03-21 09:25:30
凌晨三点的服务器警报声划破寂静,运维小张盯着屏幕上"数据库异常"的红色提示,后...

发布日期: 2025-05-02 10:00:55
全球化业务拓展过程中,企业常面临多语言数据库的管理难题。不同地区的产品说明、...

发布日期: 2025-04-10 11:44:19
凌晨三点的办公室,屏幕上闪烁的SQL报错信息让张明揉了揉发酸的眼睛。这是他本周第...

发布日期: 2025-03-30 17:23:01
在数据吞吐量激增的互联网时代,缓存技术如同高速公路的应急车道,关键时刻决定着...
发布日期: 2025-04-23 13:52:00
SQLite数据库可视化查询工具近年来逐渐成为开发者与数据分析师的新宠。这类工具通过...

发布日期: 2025-05-09 19:02:42
数据管理领域正经历从单一维度到多维协作的转型。当企业需要同时处理客户档案、产...

发布日期: 2025-05-08 11:39:42
在分布式架构与高并发场景下,数据库连接池的稳定性直接影响系统性能。传统运维中...

发布日期: 2025-04-01 17:44:09
在众多数据库管理工具中,SQLite以其轻量化和零配置的特点脱颖而出。对于开发者和运...

发布日期: 2025-04-25 19:29:58
夏日的宠物医院候诊室里,一位女士正翻阅着泛黄的笔记本,上面密密麻麻记录着爱犬...

发布日期: 2025-04-06 15:29:58
在数据驱动的业务场景中,快速获取并分析数据是企业决策的关键。传统数据库查询往...

发布日期: 2025-03-26 16:49:06
在数据库密集型应用场景中,查询性能直接影响着系统响应速度和用户体验。基于PyO...
发布日期: 2025-05-13 09:00:01
在数据驱动的软件开发领域,SQLite以其轻量化特性成为移动端和嵌入式系统的首选数据...

发布日期: 2025-04-12 15:17:06
在司法实务场景中,法律文书的格式合规性直接影响司法效率与文书效力。传统人工校...

发布日期: 2025-04-05 12:12:01
在传统法律文书处理流程中,法律从业者常需耗费大量时间重复录入基础信息。某律师...

发布日期: 2025-03-30 16:22:29
地铁上突然想到的会议发言框架,超市里需要补货的日用品清单,凌晨三点失眠时冒出...

发布日期: 2025-03-27 17:58:35
在数据库运维领域,索引优化向来是DBA们头疼的难题。传统的人工排查方式如同大海捞...

发布日期: 2025-05-16 12:43:28
检索结果的整理效率直接影响专利分析工作质量。专业人员在处理大规模专利数据时,...

发布日期: 2025-03-30 16:26:03
在团队协作中,任务分配与进度跟踪的复杂度常随着项目规模扩大而升级。一款基于...

发布日期: 2025-04-29 13:42:01
在数据处理工作中,SQLite因其轻量便捷的特性广受欢迎。但对于非技术人员而言,命令...

发布日期: 2025-04-05 18:40:33
在数据处理与软件开发中,SQLite以其轻量、嵌入式的特性成为本地数据库的热门选择。...
发布日期: 2025-04-26 15:43:04
在数据成为核心生产力的时代,许多职场人常面临这样的困境:市场部的Mary需要分析五...
发布日期: 2025-05-08 19:52:56
在数据驱动的业务场景中,快速导出数据库查询结果的需求几乎无处不在。无论是开发...
发布日期: 2025-03-22 11:23:06
当两个数据库环境中的用户表突然出现字段类型冲突,当预发布环境的索引数量与生产...

发布日期: 2025-04-20 12:57:01
凌晨三点的报警短信响起时,运维老张摸出床头柜的眼镜,盯着手机屏幕上突然飙升的...

发布日期: 2025-05-12 15:11:33
在数据库开发过程中,存储过程的调试长期困扰着开发者。传统的手动调试方式不仅效...

发布日期: 2025-03-27 11:58:39
对于数据分析师、开发者和科研人员而言,SQLite数据库文件的高效迁移需求普遍存在。...

发布日期: 2025-03-30 16:08:12
在数据管理需求日益增长的当下,一款名为SQLiteGUI的开源工具正在技术圈引发关注。这...
发布日期: 2025-03-29 16:18:51
数据库表结构同步在分布式系统开发、数据迁移或灾备场景中属于高频操作。传统人工...

发布日期: 2025-04-25 16:49:29
数据库工程师老张最近遇到个头疼的问题:公司业务扩张后,数据量激增导致单个MyS...

发布日期: 2025-03-26 12:54:02
本地开发场景中,SQLite因其零配置、单文件存储的特性广受欢迎。面对上百兆的数据库...

发布日期: 2025-04-05 11:11:29
在移动应用与Web服务开发中,实时天气数据的调用频率居高不下。频繁向第三方API发起...

发布日期: 2025-04-28 11:57:01
多数据库表关联合并工具在数据处理领域逐渐成为刚需。随着企业数据源的多样化,技...

发布日期: 2025-05-01 12:14:15
对于每天需要处理数百个备份文件的DBA来说,混乱的文件管理就像定时。某次凌晨三点...

发布日期: 2025-04-04 12:48:01
在代码托管平台普及的今天,工程师们早已习惯用Git管理文本文件。但面对设计稿、视...

发布日期: 2025-04-10 19:05:40
在司法实务与法律文书处理领域,文件命名标准化一直是困扰从业者的痛点。尤其是涉...

发布日期: 2025-04-30 18:03:01
在司法实践中,法律文书的条款编号体系犹如精密运转的齿轮系统,任何环节的错位都...

发布日期: 2025-05-01 19:59:11
当开发者尝试通过WAL(Write-Ahead Logging)模式提升SQLite并发性能时,常会遇到意料之外的...
发布日期: 2025-04-03 11:42:29
在数据驱动的应用开发中,数据库可视化工具的使用能显著提升开发效率。基于SQLite...

发布日期: 2025-04-10 14:45:55
南窗下斜斜漏进一缕阳光,指尖刚触碰到手机屏幕上的"随机选诗"按钮,李白的"花间一...

发布日期: 2025-04-21 10:34:40
在数据库管理领域,表结构信息的快速获取与归档是开发者和运维团队的高频需求。无...

发布日期: 2025-03-26 15:44:56
凌晨三点的机房监控屏突然闪烁红光,某电商平台运维人员发现数据库出现异常锁表现...

发布日期: 2025-04-14 14:30:48
在数字化浪潮中,一款名为"墨韵接龙"的本地化工具悄然流行。这个不足200MB的绿色软件...

发布日期: 2025-04-12 11:28:46
数据库连接池泄露检测报警系统近年来逐渐成为运维领域的热门工具。随着微服务架构...

发布日期: 2025-04-09 11:56:31
在数据处理需求日益增长的当下,一款操作门槛低、适配性强的数据库管理工具显得尤...

发布日期: 2025-04-20 19:04:13
当前运动领域数据管理存在碎片化痛点,健身房、运动队、可穿戴设备产生的多维数据...

发布日期: 2025-03-28 19:49:07
数据库连接池作为现代应用系统的关键组件,其稳定性直接影响业务连续性。某科技团...
发布日期: 2025-05-02 19:44:17
清晨的阳光斜照在程序员老张的电脑屏幕上,他正在调试客户端的本地缓存异常。SQL...
发布日期: 2025-04-28 13:58:23
法律文书作为司法实践的重要载体,其信息价值随着案件量的激增愈发凸显。面对海量...

发布日期: 2025-04-28 12:39:47
在日均处理百万级事务的电商系统中,某技术团队曾因未设置SQL执行时间阈值,导致促...

发布日期: 2025-04-16 18:05:26
2023年春季,某电商企业的市场分析团队在周例会上展示了令人惊讶的成果——原本需要...
