
发布日期: 2025-04-01 11:25:45
在信息迭代速度以分钟计算的互联网时代,如何完整保存网页的即时状态成为企业法务...

发布日期: 2025-05-09 17:10:54
在信息爆炸的互联网时代,某科技团队研发的ContentCleaner工具正在改变内容处理的工作...

发布日期: 2025-05-07 15:29:09
加密货币市场的高波动性让实时数据成为决策核心。各类行情工具应运而生,帮助投资...
发布日期: 2025-04-17 09:13:30
在充斥着数据洪流的现代网络环境中,某互联网公司的运维团队在黑色星期五当天遭遇...

发布日期: 2025-04-19 17:31:16
在无线网络覆盖日益复杂的场景下,WiFi信号强度监测仪逐渐成为家庭用户、企业IT管理...

发布日期: 2025-05-04 12:17:24
网页数据采集作为信息获取的重要方式,正在被越来越多的开发者关注。基于Python Re...
发布日期: 2025-06-09 19:30:02
股票数据工具:实时抓取与可视化实践 金融市场的波动性与信息时效性密切相关。一款...

发布日期: 2025-04-13 15:28:14
在数据驱动的技术场景中,高效获取网页内容成为开发者必备技能。Python生态中的Req...

发布日期: 2025-04-04 12:26:45
在网页开发实践中,HTML头部标记的规范性直接影响着搜索引擎优化效果与用户体验。针...
发布日期: 2025-06-06 09:18:02
金融市场瞬息万变,价格波动往往以秒为单位。一套高效的实时股票价格监控工具,正...

发布日期: 2025-05-27 16:03:37
日常工作中堆积如山的文件常让人手足无措——合同文档混杂着会议纪要,设计图纸里...

发布日期: 2025-05-12 15:00:38
在数字设计领域,效率工具往往能带来肉眼可见的生产力提升。当设计师对着PS界面反...
发布日期: 2025-04-24 19:18:24
在信息爆炸的时代,企业或个人想要精准页内容的动态变化,如同大海捞针。一款以关...

发布日期: 2025-05-17 18:18:01
网络数据抓取是当前企业获取公开信息的重要技术手段,但在实际应用中常遇到IP封禁...
发布日期: 2025-06-02 17:27:02
黄金作为全球流通的硬通货,其价格波动直接影响投资决策与跨国交易效率。无论是个...

发布日期: 2025-03-24 09:19:15
互联网信息爆炸时代,如何快速获取网站结构化数据成为技术人员的刚需。基于递归抓...

发布日期: 2025-05-22 09:52:43
网页抓取新助手:零代码爬虫模板生成器 在数据驱动的互联网时代,网页数据抓取已成...

发布日期: 2025-05-16 12:39:36
当电商平台凌晨弹出"猜你喜欢"的精准推荐,当社交媒体首页总显示相关广告,这背后...
发布日期: 2025-05-20 10:27:01
面对浏览器收藏夹里上千条未分类的链接,你是否经历过重装系统时的手忙脚乱?当更...

发布日期: 2025-04-16 13:32:36
信息爆炸时代,企业每天需要处理超过10亿个网页内容更新。某跨国零售企业曾因未能...

发布日期: 2025-04-19 16:37:43
在信息爆炸的办公场景中,邮件作为主流沟通工具,每天承载着大量关键信息。如何从...

发布日期: 2025-04-08 12:05:07
互联网时代的热搜数据如同流动的黄金矿脉,蕴含着大众关注焦点与趋势密码。某款新...

发布日期: 2025-06-08 09:18:01
在信息爆炸的互联网时代,快速获取目标数据成为企业和研究者的刚需。静态网页作为...

发布日期: 2025-05-08 13:51:59
在本地开发或团队协作场景中,经常需要快速共享项目文件。传统的FTP或云盘方案配置...

发布日期: 2025-05-31 17:21:02
面对服务器每天产生的GB级日志数据,运维人员常陷入"大海捞针"的困境。某科技团队研...

发布日期: 2025-06-05 19:06:02
随着在线视频内容的爆发式增长,用户对高效保存与重复利用资源的需求日益迫切。传...

发布日期: 2025-04-27 09:33:25
在设计领域,精确捕捉色彩如同画家挑选颜料般重要。当设计师面对数十种相近的蓝色...

发布日期: 2025-04-25 12:18:33
在Windows 11任务管理器后台常驻造成视觉干扰的日常困扰中,一款名为MemFlow的桌面悬浮...
发布日期: 2025-05-17 13:20:46
现代办公场景中,文件格式的多样化常常成为信息检索的阻碍。某款新型文档检索工具...
发布日期: 2025-04-23 09:00:01
命令行系统监控工具实战指南 在服务器运维与开发场景中,实时监控系统资源消耗是排...

发布日期: 2025-05-13 16:56:24
凌晨三点,屏幕蓝光映在程序员张宇的脸上。他正在调试一段总出Bug的代码,手指在机...

发布日期: 2025-04-24 18:17:42
打开电商平台商品页时,用户看到的实时折扣可能由后台脚本动态生成;新闻资讯网站...

发布日期: 2025-03-27 18:59:11
互联网时代,网页加载速度每延迟1秒,用户跳出率就会上升7%。某金融科技公司曾因服...
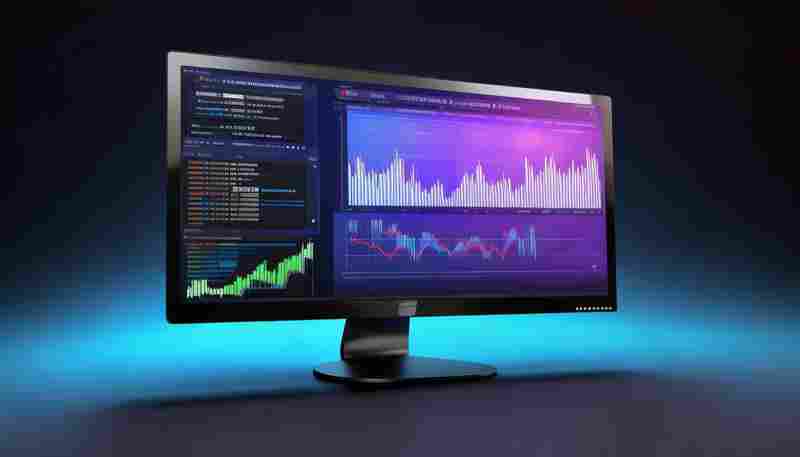
发布日期: 2025-05-18 15:29:46
打开电脑工作半小时后,浏览器标签页数量突破20个,开发工具的内存占用曲线悄然爬...

发布日期: 2025-04-02 12:44:36
在大数据时代,获取网络信息的效率直接影响着决策质量。一款支持关键词过滤的简易...

发布日期: 2025-03-31 14:39:23
全球疫情监测已进入常态化阶段,一款专业可靠的疫情数据追踪工具成为公众日常刚需...

发布日期: 2025-03-31 10:47:49
在信息爆炸的时代,企业或个人对特定网页内容的动态监控需求日益增长。无论是追踪...

发布日期: 2025-04-14 12:15:28
在信息可视化需求激增的数字化时代,完整页内容成为产品、运营、开发人员的刚需。...
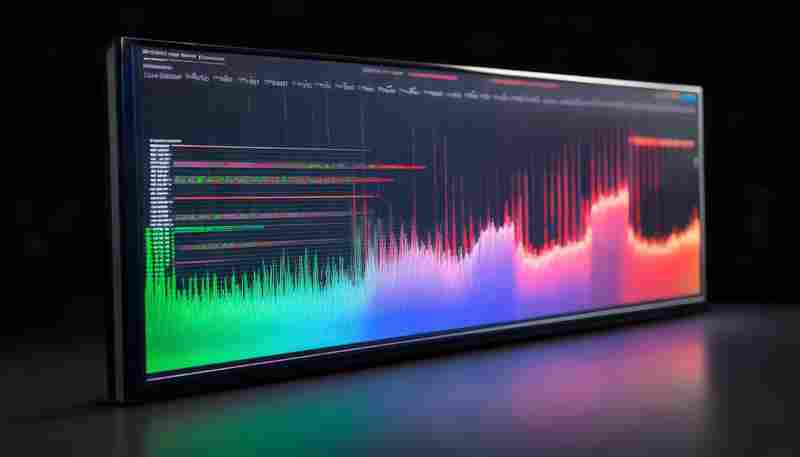
发布日期: 2025-06-12 13:18:01
在网络运维与安全监控领域,流量可视化工具的实用价值日益凸显。面对复杂的网络环...

发布日期: 2025-04-19 18:14:08
在信息爆炸的时代,网页数据的高效获取与存储成为企业及个人用户的核心需求。一款...

发布日期: 2025-06-01 19:48:02
在数字设计、网页开发或图像处理领域,快速获取屏幕任意位置的颜色值是一项高频需...

发布日期: 2025-05-16 19:05:10
城市图书馆的数字化项目组最近遇到棘手难题:在构建本地文献数据库时,第三方网站...

发布日期: 2025-04-02 13:16:49
在信息爆炸时代,网页存档已成刚需。某咨询公司调查显示,75%的互联网用户每周至少...
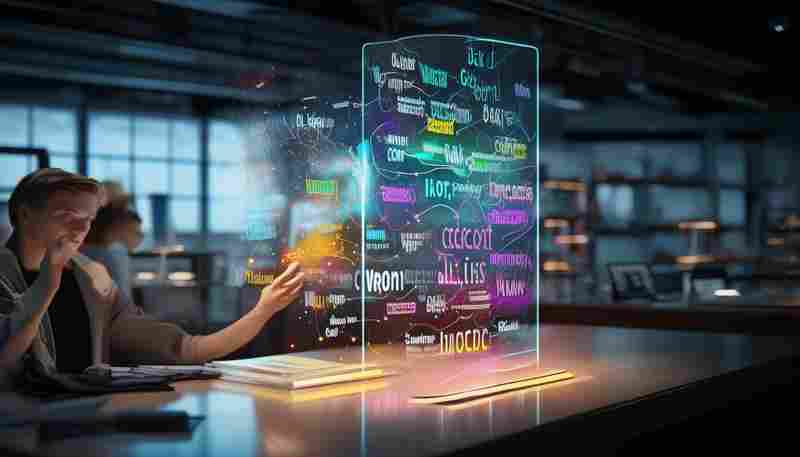
发布日期: 2025-05-06 10:08:37
课程问答区关键词提取与关联图谱工具是当前教育技术领域的热门应用方向。该工具通...
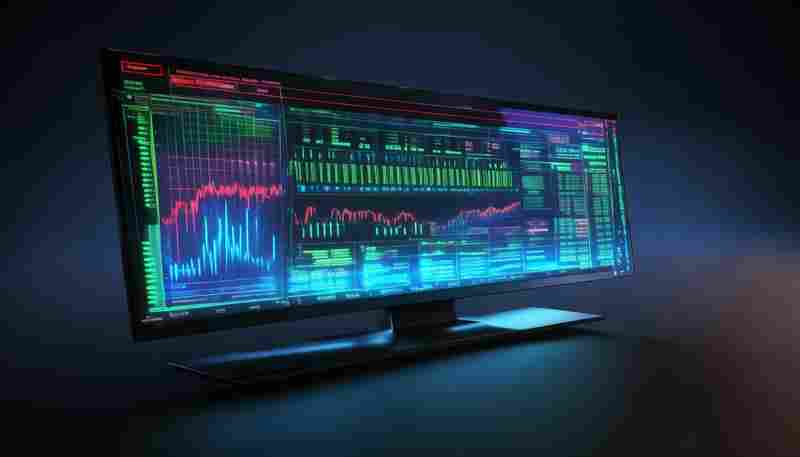
发布日期: 2025-05-05 15:08:13
系统进程监控器是计算机管理中不可或缺的实用工具。这款软件通过实时追踪CPU、内存...

发布日期: 2025-05-02 18:42:45
在互联网产品快速迭代的今天,实时通信已成为用户对应用体验的核心诉求之一。从在...

发布日期: 2025-03-29 17:26:24
窗外的雨点敲击玻璃时,桌面右下角的小云朵同步凝出水珠;晨光穿透窗帘的瞬间,像...

发布日期: 2025-04-03 16:31:46
互联网时代的数据抓取需求持续增长,基于CSS选择器的数据提取工具逐渐成为开发者和...

发布日期: 2025-05-25 18:38:58
网络图片资源获取已成为设计师、自媒体从业者及普通用户的日常需求。面对海量图片...

发布日期: 2025-03-29 14:56:57
互联网信息的实时性让许多行业面临动态数据追踪需求。当商品价格在凌晨突然调整,...
发布日期: 2025-04-17 09:49:35
凌晨三点,某电商平台的订单处理系统突然出现交易流水号重复生成,分布在三个服务...

发布日期: 2025-03-31 11:23:21
打开文档时,光标总会在某个词句前停顿。市场部的张磊对着电脑屏幕苦笑——这份需...

发布日期: 2025-03-23 14:00:02
在数字化办公场景中,敏感信息泄露如同一颗定时。一份合同中的身份证号、一份报表...

发布日期: 2025-05-29 13:30:01
在信息爆炸的股票投资领域,碎片化信息筛选成为投资者的核心痛点。雪球平台每日产...

发布日期: 2025-03-23 10:23:18
在数字设计领域,色彩搭配是决定作品成败的关键因素之一。从海量素材中精准提取主...

发布日期: 2025-05-27 12:35:28
在交通管理领域,实时掌握车辆通行数据直接影响着城市道路规划效率。一款基于图像...
发布日期: 2025-04-24 13:46:27
互联网每天产生数十亿张图片,高效获取目标素材成为刚需。本文介绍的批量图片抓取...

发布日期: 2025-03-26 12:29:14
窗外的雨水敲打着玻璃,王工习惯性地按下Ctrl+Alt+Del,看着任务管理器里跳动的CPU曲线...
发布日期: 2025-06-12 11:06:03
在信息高速流动的金融市场,投资者对于股票价格的实时变动尤为敏感。一款高效的股...

发布日期: 2025-04-30 16:33:36
在网页设计中,渐变色彩的运用既能提升视觉层次感,也可能成为翻车现场。当设计师...
