
发布日期: 2025-06-03 16:36:01
在信息爆炸的当下,碎片化阅读逐渐成为主流。人们既渴望快速获取知识,又希望内容...
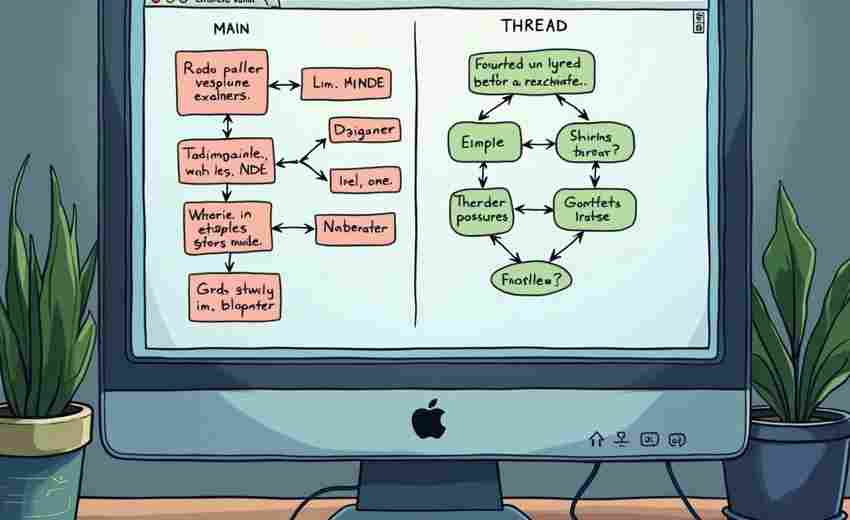
发布日期: 2025-04-03 12:28:58
电子书制作领域近日出现了一款名为EPUB Navigator的专业工具,其独特的XHTML文件关系图谱...

发布日期: 2025-05-21 11:18:26
在数字化信息交互场景中,二维码已成为连接线上线下的重要工具。无论是产品包装、...

发布日期: 2025-06-07 11:12:01
在数字内容创作日益普及的今天,音视频素材的二次加工需求激增。不少用户发现,手...

发布日期: 2025-03-23 14:02:25
互联网时代每天产生的视频内容数以亿计。面对堆积如山的视频文件,快速获取关键参...

发布日期: 2025-04-28 09:30:40
碎片化传播时代,动态图片因其体积小、易传播的特性成为社交平台宠儿。针对视频素...

发布日期: 2025-05-23 15:08:58
在信息爆炸的社交时代,品牌、自媒体和个体用户面临一个共同难题:如何在有限时间...

发布日期: 2025-04-19 16:41:18
在政务大厅的备案窗口前,某文化公司负责人手持新刻的电子印章,红色印迹在合同落...

发布日期: 2025-04-17 19:40:27
在企业经营分析中,销售数据的可视化呈现直接影响决策效率。传统制表工具存在操作...

发布日期: 2025-05-16 17:14:42
在软件项目的生命周期中,目录结构如同城市的地下管网,看似不起眼却维系着整个系...

发布日期: 2025-04-01 14:42:32
在信息爆炸的时代,论坛、贴吧等社区平台每天产生海量讨论内容。如何从繁杂的文本...

发布日期: 2025-04-18 11:29:00
在好莱坞特效大片的幕后花絮中,我们常能看到演员们在绿色幕布前表演的场景。这种...

发布日期: 2025-06-02 14:24:01
在数字内容创作领域,动画文件的应用场景越来越广泛,但传统GIF格式的局限性也逐渐...

发布日期: 2025-04-14 12:22:46
在企业日常运营中,Excel报表的重复性制作常让员工陷入低效的手动操作。一款基于S...

发布日期: 2025-04-15 10:41:36
随着全球视频创作者数量突破5000万,YouTube平台日均新增评论量超过20亿条。面对海量的...

发布日期: 2025-04-08 13:20:01
在视觉设计领域,文字从来都不只是信息的载体。当静态排版遇上动态烟雾效果,文字...

发布日期: 2025-05-14 12:24:29
短视频时代,动图已经成为社交语言的重要组成部分。无论是微信聊天里的表情包,还...

发布日期: 2025-04-08 11:50:46
打开电脑里的数据表格,密密麻麻的数字让人头晕目眩。这可能是每个职场人做分析报...

发布日期: 2025-04-10 16:36:36
剪辑视频时最头疼的瞬间,莫过于发现精心设计的台词与人物口型差了半拍。传统手动...

发布日期: 2025-05-03 13:52:27
双击一个视频文件时,人们往往只关心画面能否正常播放。但对于需要处理大量视频素...

发布日期: 2025-05-09 12:14:14
在个人信息频繁泄露的互联网时代,密码如同家门钥匙,一旦被破解,隐私与资产可能...

发布日期: 2025-04-17 11:11:34
在信息爆炸的时代,用户反馈中往往隐藏着海量的价值信息。如何快速提炼核心内容,...

发布日期: 2025-05-04 12:20:59
日常工作中,文件管理常因版本迭代出现混乱。某互联网公司开发部曾因设计稿版本混...

发布日期: 2025-04-08 17:19:26
在数字化办公逐渐普及的今天,重复性的屏幕操作成为许多人效率的绊脚石。从繁琐的...

发布日期: 2025-04-11 11:58:36
对于硬件工程师、极客爱好者或是需要频繁整理设备清单的运维人员来说,手工记录主...

发布日期: 2025-04-30 18:49:12
在社交媒体运营领域,创作者常面临一个悖论:既要保证内容高频输出,又要维持创意...

发布日期: 2025-05-15 12:15:22
盛夏午后,艺术家小林盯着空白画布发愣。他尝试用AI绘画工具创作科幻插画,但输入...

发布日期: 2025-04-15 17:58:52
现代生活中,密码泄露引发的安全隐患日益频繁。无论是个人账户还是企业系统,静态...

发布日期: 2025-04-13 12:07:03
在代码与终端交织的世界里,一群开发者默默打磨着一款开源工具——Sudoku-CLI。这款命...
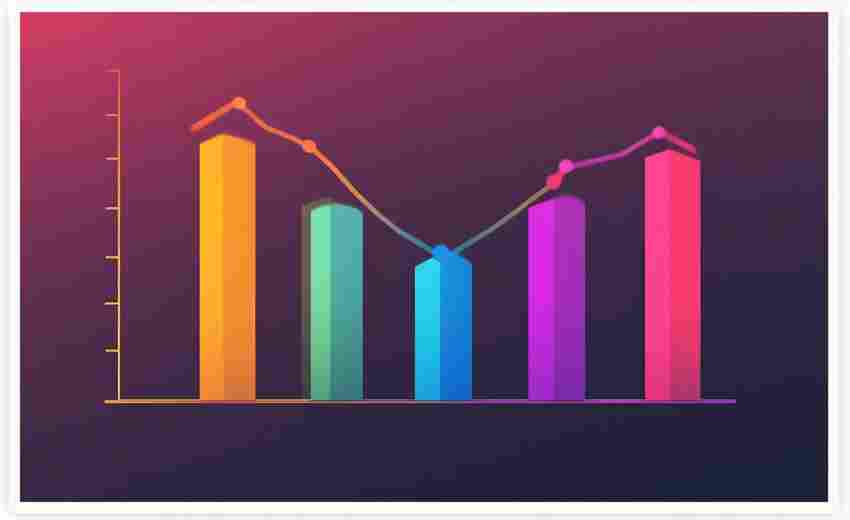
发布日期: 2025-04-14 09:00:06
学生成绩数据可视化柱状图生成器是一款专注于教育场景的数据处理工具。该工具通过...

发布日期: 2025-03-30 13:20:45
在全球化的商业场景中,货币代码的准确性直接影响交易效率和数据处理能力。为满足...

发布日期: 2025-03-30 17:26:35
在数字艺术领域,一款名为"混沌画布"的图形随机生成器正悄然成为设计师与艺术爱好...

发布日期: 2025-04-29 11:33:32
在儿童教育或益智游戏开发领域,几何图形拼图一直扮演着重要角色。它不仅锻炼空间...
发布日期: 2025-04-16 19:07:10
对于需要快速记录屏幕操作的用户而言,传统录屏软件往往存在体积臃肿、操作复杂等...

发布日期: 2025-04-18 13:02:17
从事视频处理工作的人常会遇到这类场景:收到上百条客户提供的视频素材,需要快速...

发布日期: 2025-05-07 15:11:19
视频元数据解析工具正成为影视从业者和数字内容创作者的必备利器。面对海量的MP4、...

发布日期: 2025-05-10 10:26:44
许多视频处理场景中需要将动态影像转化为静态画面,视频帧提取工具应运而生。这款...

发布日期: 2025-04-06 15:29:58
在数据驱动的业务场景中,快速获取并分析数据是企业决策的关键。传统数据库查询往...

发布日期: 2025-04-10 15:17:59
在数字信息快速流转的当下,二维码逐渐成为连接线下与线上场景的桥梁。对于开发者...

发布日期: 2025-05-12 18:15:02
在信息爆炸的时代,企业会议频率激增,人工整理会议纪要的效率逐渐成为痛点。传统...
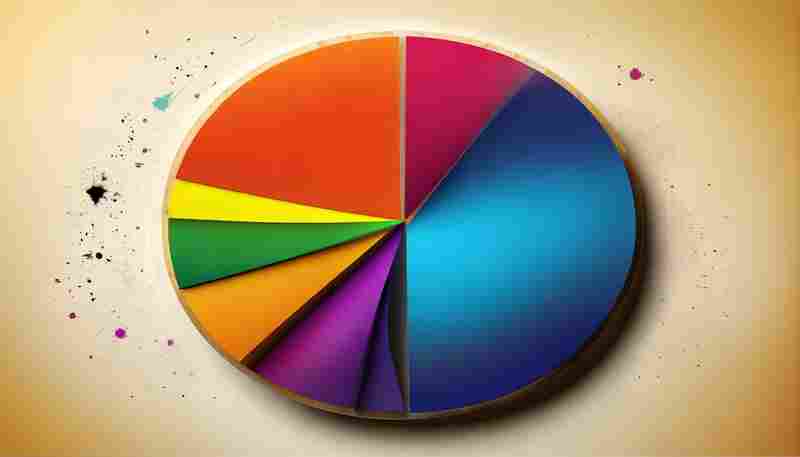
发布日期: 2025-04-23 16:46:52
图书评论情感词分布饼图生成器是一款基于自然语言处理技术开发的数据可视化工具。...

发布日期: 2025-05-21 11:14:51
随着社交媒体内容的价值被持续挖掘,知乎作为中文领域高质量问答社区,成为数据分...

发布日期: 2025-05-12 13:48:38
在数据处理与分析领域,快速生成可视化图表的需求日益迫切。Excel作为办公场景中最...
发布日期: 2025-04-16 09:18:01
在教育场景中,考试成绩的分布分析是评估教学效果的重要环节。传统的数据分析工具...
发布日期: 2025-04-29 17:16:12
股票分析领域的数据可视化需求持续攀升,投资者对于高效获取历史行情并快速生成分...
发布日期: 2025-05-08 10:46:04
在持续集成与敏捷开发的行业背景下,测试团队每天需要处理上百条用例的执行结果。...

发布日期: 2025-05-01 16:42:01
影视从业者常遇到这样的困境:一段4K素材需要精准拆分镜头,但传统剪辑软件导出的...

发布日期: 2025-04-09 14:11:48
在短视频创作与影视素材处理领域,精确到秒的片段截取能力已成为刚需。市面主流剪...

发布日期: 2025-06-06 09:42:02
互联网应用中验证码系统承担着人机识别的重要功能。一款基于Python开发的轻量化验证...

发布日期: 2025-04-19 19:03:51
对于摄影爱好者和普通用户而言,整理数字照片始终是个麻烦事。手动排版网页相册需...
发布日期: 2025-03-28 17:33:53
数字化进程中,历史文件的编码问题常成为数据迁移的隐形障碍。不同时期、不同系统...

发布日期: 2025-04-21 12:07:22
在短视频创作与社交媒体传播盛行的当下,GIF动图因兼容性强、体积小巧的特点,成为...

发布日期: 2025-04-17 13:08:11
一段精彩的视频片段浓缩成GIF动图,正在成为社交分享的主流方式。但直接导出的动图...

发布日期: 2025-04-18 09:19:05
音视频元数据编辑工具:ID3标签修改指南 在数字媒体时代,音乐和音频文件的管理逐渐...

发布日期: 2025-03-27 17:15:40
当教师在办公室整理期末考试成绩时,面对上千条,手动绘制成绩分布图的场景早已成...

发布日期: 2025-04-22 17:46:46
在数字媒体处理领域,一款名为MetaVision的视频元数据解析工具正悄然改变着从业者的工...

发布日期: 2025-05-09 11:52:47
短视频平台的流量争夺战中,封面截图的质量直接影响用户点击率。一款能适配抖音、...

发布日期: 2025-04-27 12:49:38
随着手机拍摄与短视频创作的普及,个人设备中堆积的MOV、MP4文件常达数百个。某次整...

发布日期: 2025-03-27 13:03:01
网络时代的海量视频资源常让人产生保存需求,视频链接批量下载器作为专业工具正在...

发布日期: 2025-03-28 12:17:41
在视频处理领域,帧率(FPS)与单帧时长(毫秒/帧)的换算常让从业者头疼。某个深夜...
")