
发布日期: 2025-03-28 09:26:32
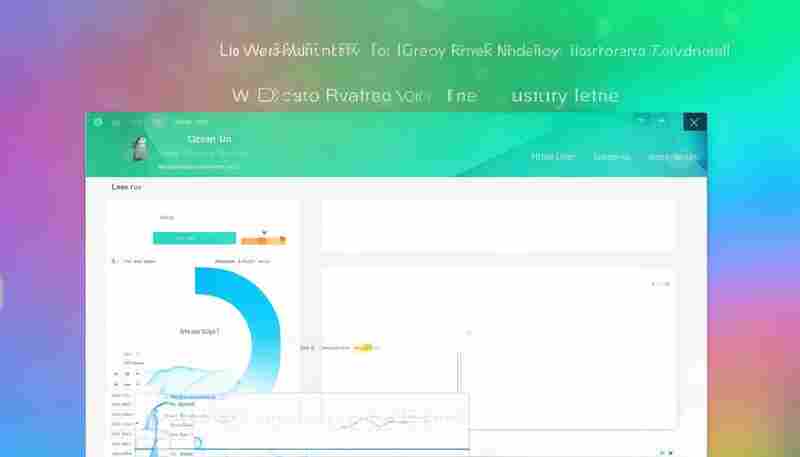
实验室仪器使用登记管理系统作为现代科研场景的标配工具,正在改变传统人工台账的...
发布日期: 2025-06-03 15:30:01
日常使用Windows电脑时,通知中心像一位尽职的助手,不断弹出软件更新、邮件提醒或会...

发布日期: 2025-04-14 11:54:01
窗外的雨点敲打着玻璃,忽然想起上个月用Python写了个本地天气查询工具。那台老式笔...
发布日期: 2025-05-09 09:29:44
日常工作中,频繁面对海量文本文件的编辑需求时,手动逐行查找替换不仅耗时,还容...

发布日期: 2025-05-12 18:52:16
在数字时代,文件管理成为许多人的日常痛点。无论是杂乱的照片库、堆积的文档,还...
发布日期: 2025-03-30 18:02:13
办公桌上堆叠的Excel表格与CSV文件,构成了企业数据流转的典型场景。某跨国物流公司...

发布日期: 2025-07-19 15:42:01
在数字化办公环境中,网络管理员经常面临这样的困扰:某天突然出现网页加载迟缓,...

发布日期: 2025-06-18 15:36:02
跨设备数据流转的痛点与解决方案 每次换新设备时,人们总会面临一个尴尬的问题:旧...

发布日期: 2025-06-12 12:54:02
在缺乏互联网支持或注重隐私保护的场景中,一款基于Socket技术实现的局域网聊天工具...

发布日期: 2025-04-05 11:54:25
随着企业数字化进程加速,日志分析逐渐成为运维工作的核心环节。面对每天产生的海...
发布日期: 2025-06-06 15:54:01
许多人在使用电脑时都遇到过类似困扰:剪辑视频时软件突然卡死,游戏激战时画面莫...
发布日期: 2025-07-05 18:36:01
在数字信息爆炸的时代,文本处理效率直接影响着程序员、编辑、科研人员等群体的工...

发布日期: 2025-05-01 13:15:02
在数据清洗领域,技术人员常面临批量处理海量文本的需求。某开源社区近期迭代的...

发布日期: 2025-06-23 10:24:01
现代办公环境中,USB设备作为数据传输的重要媒介,既是效率工具,也可能成为安全隐...

发布日期: 2025-05-24 14:06:48
翻开某论坛技术版块,总能撞见几个技术宅抱团取暖的帖子:"下载的TXT小说不分段怎么...

发布日期: 2025-05-09 19:09:52
对于键盘使用者而言,连击响应能力直接影响输入效率与操作体验——无论是游戏中的...

发布日期: 2025-05-02 14:39:21
在跨语言信息处理场景中,内容过滤常面临特殊符号干扰、术语混杂等痛点。某技术团...
发布日期: 2025-04-21 14:51:25
正则表达式作为文本处理的利器,长期活跃在开发者和数据分析师的工作场景中。但对...

发布日期: 2025-06-17 19:54:01
屏幕上的蓝色箭头缓缓向右移动,拖出一道红色轨迹。随着代码行数增加,这只名为...
发布日期: 2025-06-26 16:30:01
在数字音频处理领域,Wave库作为Python标准库中的一员,常被开发者用于处理WAV格式文件...
发布日期: 2025-07-03 10:36:01
现代人日均点亮手机屏幕超过150次,平均使用时长突破6小时。这个数据背后藏着无数个...

发布日期: 2025-04-12 15:17:06
在司法实务场景中,法律文书的格式合规性直接影响司法效率与文书效力。传统人工校...

发布日期: 2025-05-21 18:46:57
在电脑外设逐渐成为效率核心工具的今天,用户对于设备使用状态的追踪需求正快速上...
发布日期: 2025-07-01 18:36:01
日常工作中,频繁按下的Ctrl+C/V组合键背后,隐藏着大量被覆盖的宝贵数据。传统剪贴...

发布日期: 2025-04-02 12:59:08
在数字信息爆炸的时代,一台普通办公电脑存储着超过10万份文件早已不是新鲜事。面...
发布日期: 2025-06-05 14:00:02
在数据爆炸的时代,CSV文件因其通用性成为跨平台数据交换的标配格式。基于Python生态...
发布日期: 2025-05-16 13:37:06
在学术研究场景中,参考文献格式的准确性直接影响论文的专业性与可信度。APA、MLA、...

发布日期: 2025-04-07 09:23:59
在当今软件系统的运行过程中,日志文件如同人体脉搏般持续记录着各类运行状态。面...

发布日期: 2025-04-10 18:28:56
在日常使用电脑的过程中,许多用户都曾遭遇过开机速度异常缓慢、莫名弹窗广告或程...
发布日期: 2025-05-26 13:24:35
服务器机房内,运维工程师的手机突然弹出红色警报提示。某台核心服务器的内存使用...

发布日期: 2025-05-23 19:49:42
日常工作中重复制作Excel报表耗费大量精力,数据工程师李明在某次加班时发现了Open...

发布日期: 2025-05-02 13:31:35
蛇形像素在屏幕上灵活游走,吞下食物后身体逐渐变长——贪吃蛇的玩法看似简单,却...

发布日期: 2025-04-19 09:40:59
在数字化办公场景中,纸质文档的电子化处理已成为基础需求。当用手机拍摄文档时,...
发布日期: 2025-07-20 18:48:01
——正则表达式在时间处理中的实战应用 当跨国团队协作成为常态,一封邮件中混杂着...
发布日期: 2025-07-26 11:30:01
系统通知功能在日常办公中扮演着重要角色。当用户需要自主控制通知触发机制时,开...

发布日期: 2025-05-05 14:10:07
在数据处理需求日益增长的今天,开发者们经常需要寻找既能快速上手又具备足够灵活...

发布日期: 2025-05-21 13:17:18
厨房工作台摆满食材时,打开手机里的食谱管理应用,三秒定位到上周收藏的"泰式冬阴...

发布日期: 2025-04-24 12:45:46
在数字化浪潮的裹挟下,手机、电脑逐渐成为现代人的"第二器官"。人们一边抱怨被屏...
发布日期: 2025-07-01 10:12:01
现代人平均每天点亮手机屏幕超过百次,社交、购物、娱乐在指尖滑动间悄然吞噬时间...

发布日期: 2025-03-26 13:33:01
工具定位 面对动辄数十GB的服务器日志,运维人员常被困在时间戳定位的泥潭里。某款...

发布日期: 2025-06-10 16:54:01
在计算机使用过程中,USB设备因其便捷性成为数据交互的重要载体,但频繁的插拔操作...

发布日期: 2025-07-05 15:42:01
现代数据处理离不开高效的矩阵运算。作为Python生态中最重要的数值计算库,NumPy的矩...
发布日期: 2025-06-21 17:30:02
对于频繁处理文档与代码的开发者或编辑人员来说,多窗口文件内容搜索替换工具正在...

发布日期: 2025-04-01 14:28:09
现代健身房常面临设备资源分配难题——热门器械高峰时段排队严重,冷门设备长期闲...

发布日期: 2025-05-15 15:13:56
在日常使用电脑的过程中,驱动程序的稳定性往往直接影响到硬件设备的运行效率。无...

发布日期: 2025-04-18 15:23:22
日常使用电脑时,总会出现程序卡死、后台异常这类恼人的状况。Windows系统自带的任务...

发布日期: 2025-03-27 10:04:47
互联网时代的数据采集离不开爬虫技术,而基于正则表达式的轻量化爬虫框架因其灵活...

发布日期: 2025-05-27 14:15:40
在数据科学领域,CSV格式文件始终占据重要地位。这种以逗号分隔的纯文本格式,因其...
发布日期: 2025-04-28 14:30:35
流量使用量多维度筛选查询工具:数据管理的效率革新 在数字化进程加速的今天,流量...

发布日期: 2025-04-01 17:01:28
互联网应用中,Cookie作为用户身份验证与状态管理的重要载体,其内容解析常让开发者...

发布日期: 2025-03-23 13:44:01
密钥文件管理常面临海量数据检索难题,尤其在分布式服务器集群或持续交付场景下,...
发布日期: 2025-07-03 10:42:02
数字时代,数据安全成为刚需。对于普通用户而言,专业级加密软件往往操作复杂、学...

发布日期: 2025-04-05 12:22:53
窗台上咖啡杯升起的热气还未消散,桌面便利贴已层层叠叠。当代人面对碎片化任务常...
发布日期: 2025-07-02 16:18:02
在日常办公场景中,大量文件名混乱的下载文件常令使用者头疼。某技术团队近期发布...

发布日期: 2025-03-22 09:02:01
在数字化场景中,密码策略的设计与落地一直是企业安全合规的痛点。传统模式下,安...

发布日期: 2025-03-23 12:08:54
在生物医药、化学分析等领域的实验室中,离心机是高频使用的核心设备之一。传统纸...

发布日期: 2025-03-23 13:40:01
电脑突然卡成PPT?软件闪退找不到原因?后台进程偷偷吃掉大半内存?一套轻量级系统...

发布日期: 2025-03-24 12:54:41
在邮件数据量激增的数字化办公场景中,如何高效提取和分析邮件内容成为企业级应用...

发布日期: 2025-04-26 09:49:19
电脑使用时间一长,总会遇到卡顿、存储空间不足的困扰。后台堆积的临时文件、冗余...
发布日期: 2025-07-18 12:00:02
在互联网安全攻防战中,服务器访问日志如同战场上的监控录像,记录着每一次网络请...