发布日期: 2025-05-09 13:14:52
机器学习数据集版本管理已成为算法开发流程中不可或缺的环节。当数据科学家面对频...

发布日期: 2025-05-19 18:11:37
在现代编程学习中,图形界面开发始终是激发兴趣的重要环节。Python标准库自带的Tki...

发布日期: 2025-07-08 18:30:02
碎片化学习时代,编程新手常陷入"学了就忘"的困境,中级开发者容易遭遇"技能瓶颈...

发布日期: 2025-04-23 14:24:02
在中文学习和教学领域,汉字拼音转换工具已成为不可或缺的实用助手。这类工具通过...

发布日期: 2025-04-23 14:59:50
键盘声夹杂着咖啡机的嗡鸣,凌晨三点的书房里,一位开发者正反复调试着网页动画参...

发布日期: 2025-06-07 09:30:01
在数字化服务场景中,关键词回复式聊天机器人逐渐成为企业与用户沟通的高效工具。...

发布日期: 2025-03-27 10:33:23
语言学习者常被生词记忆困扰。纸质笔记本记录效率低,电子文档整理耗时耗力。针对...

发布日期: 2025-04-12 15:24:02
办公桌或学习区域堆积的便签纸,常因信息混杂导致效率下降。颜色分类管理法通过视...

发布日期: 2025-04-01 14:35:11
在语言学习过程中,拼写错误如同顽固的"拦路虎",反复消耗学习者的时间与耐心。一...

发布日期: 2025-05-19 11:55:00
在语言学习过程中,词汇积累是绕不开的基础环节。传统纸质单词本虽能记录生词,但...

发布日期: 2025-05-27 18:51:42
日志数据作为系统运行状态的"黑匣子",在故障诊断、性能优化等领域具有不可替代的...
发布日期: 2025-07-06 17:36:02
Scikit-learn作为Python生态中应用最广的机器学习工具库,自2007年发布以来持续推动着数据...

发布日期: 2025-04-30 15:40:11
在日常办公场景中,文件管理是许多人避不开的“痛点”。面对海量文档、图片、音视...

发布日期: 2025-04-12 13:15:41
在在线教育快速发展的背景下,学习路径推荐算法逐渐成为提升用户学习效率的核心技...

发布日期: 2025-04-22 16:14:11
运维团队最怕深夜被电话惊醒,但服务器宕机从不挑时间。传统邮件、短信报警存在延...
发布日期: 2025-07-15 10:18:02
语言学习过程中,例句积累是绕不开的环节。传统的学习方法依赖教材或固定课程,但...

发布日期: 2025-03-30 15:07:24
在日常工作与学习中,电子设备中堆积的文件常常让人陷入混乱。文档、图片、视频、...

发布日期: 2025-06-19 14:24:01
在信息爆炸的社交媒体时代,微博作为国内最大的舆论场之一,每天产生着数以亿计的...

发布日期: 2025-04-03 15:27:40
清晨地铁里,指尖划动手机屏幕的年轻人正在复习昨日标注的三十个生词;午休时间,...
发布日期: 2025-07-02 13:48:01
在语言学习中,跟读练习是提高发音、语调和流利度的核心方法之一。传统跟读缺乏即...

发布日期: 2025-04-28 12:50:29
在快节奏的工作与学习中,人们常常需要短暂的精神激励来保持专注与动力。一款轻巧...

发布日期: 2025-05-20 12:03:49
日志文件作为系统运行状态的真实记录载体,每天产生海量数据。某互联网公司运维部...

发布日期: 2025-06-19 16:48:01
清晨的公园里,几位植物爱好者正举着手机对准灌木丛中的野花。随着"滴"的提示音,...
发布日期: 2025-05-17 18:21:41
桌面英语卡片工具近年逐渐成为语言学习者的新宠。这类软件将传统单词本数字化,结...
发布日期: 2025-07-22 11:36:01
调试机器人系统就像在迷宫中寻找光源。面对分布式架构下多节点协同工作的ROS平台,...

发布日期: 2025-03-25 14:02:00
数据预处理环节的tf.data模块显著提升了数据管道构建效率。通过Dataset对象的链式操作...

发布日期: 2025-05-06 19:58:09
纸质单词本在书包里泛着柔和的米黄色,电子闪卡在手机屏幕闪烁冷光,两种工具承载...

发布日期: 2025-05-26 11:47:18
现代人的电脑桌面上总躺着形形的文件——工作文档、临时截图、下载的压缩包……时...

发布日期: 2025-05-19 11:58:52
在信息爆炸的社交平台时代,如何精准抓取高价值内容成为用户痛点。一款基于Reddit...

发布日期: 2025-06-11 13:27:01
潮湿的梅雨季总让人犯困,办公桌上的手机频繁震动——客户咨询、朋友闲聊、群消息...
发布日期: 2025-07-07 14:06:02
深夜两点,某电商物流中心的中控室突然响起蜂鸣声,值班工程师的手机同步收到视频...

发布日期: 2025-05-16 17:25:09
拼音声调标注作为汉语学习的基础环节,常因机械重复的练习方式让学习者感到枯燥。...
发布日期: 2025-03-22 11:05:21
日常办公与学习中,一款操作流畅、界面简洁的计算器应用能够显著提升效率。基于...

发布日期: 2025-05-27 15:34:13
语言学习领域近年涌现出一批智能记忆工具,其中支持中英互译的卡片软件逐渐成为学...

发布日期: 2025-06-22 19:18:01
厨房里盯着菜谱发愣的主妇、实验室核对数据的科研人员、机场兑换外币的旅行者……...

发布日期: 2025-05-21 10:10:22
语言学习中,词汇积累常被视作最枯燥的环节。传统纸质单词本功能单一,仅靠机械抄...

发布日期: 2025-06-13 14:30:01
记忆卡片作为语言学习的经典工具,在移动互联网时代焕发出全新生命力。某款专注英...

发布日期: 2025-06-19 17:12:02
在信息爆炸的社交媒体时代,一款能够实现自动点赞转发的工具正悄然改变着运营者的...

发布日期: 2025-04-09 10:19:23
工业机器人关节磨损趋势预测工具近年来成为智能制造领域的热门技术方向。作为工业...

发布日期: 2025-03-27 13:42:01
在日常办公或学习中,PDF文件因其兼容性强、格式稳定的特点,成为文档传输的主流格...
发布日期: 2025-05-31 16:21:02
在语言学习和语音研究领域,拼音声调的准确标注常成为工作流程中的瓶颈。传统的手...

发布日期: 2025-06-17 16:54:02
近年来,基于Python的itchat库在开发者社区持续走热。这款基于微信个人账号的API工具包...
发布日期: 2025-04-25 15:16:46
在编程学习过程中,将抽象数学概念转化为直观图形是一种有效的方法。Python自带的...

发布日期: 2025-06-21 17:42:01
在人工智能技术深度落地的今天,数字识别模型的安全问题正成为行业关注焦点。某实...
发布日期: 2025-06-16 14:30:02
键盘敲击声在安静的房间里此起彼伏,屏幕上滚动的代码突然被一个陌生单词打断。开...

发布日期: 2025-04-10 14:56:38
在工业产品设计领域,三维模型版本迭代频繁,工程师常面临文件命名混乱、历史版本...

发布日期: 2025-04-14 17:50:44
在语言学习过程中,词汇积累是绕不开的基础环节。一款名为 Tkinter背单词测验程序 的...
发布日期: 2025-04-13 10:15:55
机器学习模型的训练过程常被形容为"黑箱",开发者往往需要反复调试代码、核对日志...

发布日期: 2025-05-22 16:10:55
凌晨三点的办公室键盘声此起彼伏,技术部小王刚调试完他的第15个微信机器人原型。...
发布日期: 2025-05-27 12:56:47
在机器学习与自然语言处理领域,数据预处理是模型训练的关键环节。针对文本分类任...
发布日期: 2025-04-14 16:12:56
碎片化时代,专注力成为稀缺资源。一款名为 StudyTrack Pro 的仪表盘工具,正试图通过「...

发布日期: 2025-05-11 11:09:34
在代码编辑器的角落敲击键盘时,开发者的目光常常在某行正则表达式上凝固。那些由...
发布日期: 2025-07-01 17:36:01
在中文学习与跨语言交流中,拼音作为汉字发音的标准标注系统,承担着桥梁作用。面...
发布日期: 2025-06-25 10:42:01
在微博平台上,抽奖活动因其高互动性和低门槛属性,成为品牌方与用户建立联系的重...
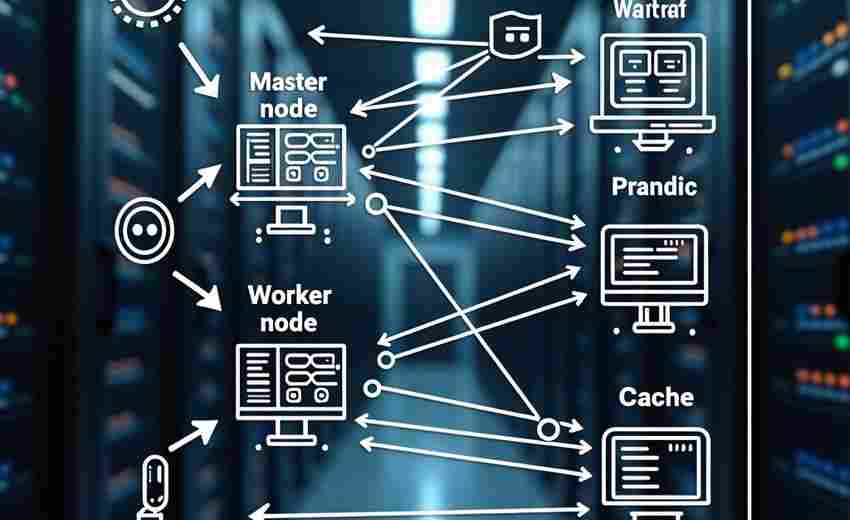
发布日期: 2025-04-14 16:49:00
在深度学习领域,工具框架的选择往往决定着研究者的思维路径。当研究人员在2017年前...

发布日期: 2025-05-17 12:44:45
在语言学习过程中,背单词始终是绕不开的基础环节。对于偏好极简操作或习惯命令行...
发布日期: 2025-07-04 09:06:03
墙面挂着半人高的磁性白板,彩色便签纸错落分布,红色标签在左上角格外显眼。这是...

发布日期: 2025-05-03 10:57:02
在信息爆炸的数字化时代,一款名为「智聆」的智能语音工具正悄然改变着学习者的知...

发布日期: 2025-04-01 09:46:03
在日常办公与学习场景中,PDF文档的灵活处理已成为高频需求。面对动辄数百页的合同...

发布日期: 2025-05-15 17:36:57
在数字化时代,数据丢失或误操作带来的风险往往让人焦虑。无论是个人用户还是企业...