
发布日期: 2025-04-03 18:50:41
在数字音乐流媒体时代,用户的听歌数据成为分析个人偏好的重要依据。Last.fm作为全球...

发布日期: 2025-07-08 19:18:01
夏夜十点的写字楼里,程序员李明第三次忘记关闭渲染视频的工作站。直到清晨保洁阿...

发布日期: 2025-06-05 16:06:02
三年前想要自定义键盘背光时,人们还需要拆解键帽焊接灯珠。如今通过专业光效控制...

发布日期: 2025-04-29 19:11:26
纸质书时代,人们习惯用书签标注阅读进度。而在数字阅读时代,用户却常被格式壁垒...
发布日期: 2025-04-27 09:40:34
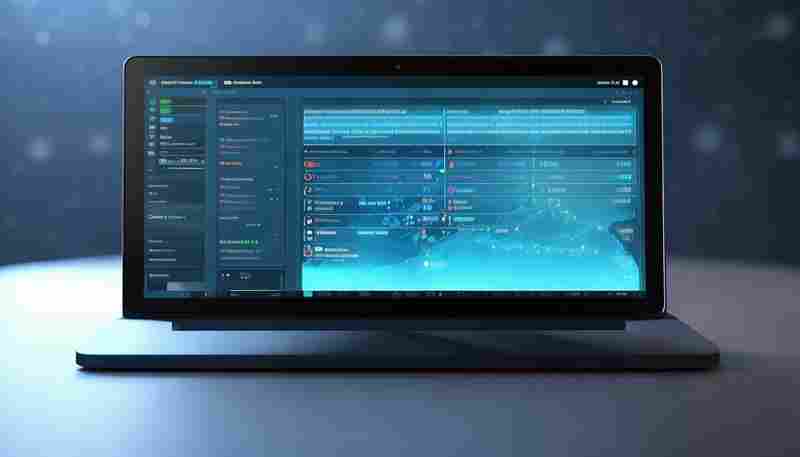
许多用户都曾有过类似困扰:电脑开机速度莫名变慢,后台程序消耗大量内存,却难以...

发布日期: 2025-04-19 19:14:38
许多用户都经历过电脑越用越卡的情况,C盘突然爆满的红色警告更是令人头疼。系统运...
发布日期: 2025-07-24 14:54:01
企业IT运维部门每月需处理数百份入职表单,教务系统每学期导入上万名学生信息,这...

发布日期: 2025-05-29 09:54:02
深色房间内唯一的光源来自屏幕,像素画师正在反复调整十六进制色块的位置。食指悬...
发布日期: 2025-07-30 15:48:02
纸质书时代随手写批注的习惯,在数字阅读时代变成了对电子书元数据的精细化管理需...

发布日期: 2025-03-21 14:19:47
在短视频内容生态高度繁荣的当下,抖音平台日均产生超过10亿条互动数据。针对品牌...

发布日期: 2025-05-28 09:22:12
互联网平台账号被盗事件频发,用户登录记录查询功能逐渐成为各大平台的标配。这个...

发布日期: 2025-04-06 11:55:18
在数字阅读逐渐取代纸质书籍的当下,电子书格式的兼容性问题成为困扰读者的主要障...

发布日期: 2025-05-08 18:05:45
在数字设备几乎成为人类感官延伸的今天,一块屏幕的视觉呈现早已超越基础功能需求...

发布日期: 2025-06-09 14:06:01
某互联网公司后台系统曾因未覆盖单元测试,上线后出现接口连环崩溃。当团队引入自...

发布日期: 2025-04-16 16:17:55
在数字化阅读时代,电子书创作者常面临内容结构梳理的痛点。传统手动编写目录不仅...

发布日期: 2025-04-10 19:48:02
纸质书的折角褶皱常被视作阅读印记,电子书的乱码错页却令人抓狂。当EPUB文档出现章...

发布日期: 2025-04-11 14:10:49
当电子设备逐渐成为生活的一部分,开机音效早已超越功能提示的范畴。对于追求个性...

发布日期: 2025-05-03 14:53:10
在数字阅读场景中,EPUB因其图文混排、自适应排版等特性成为主流电子书格式。但对于...

发布日期: 2025-04-21 17:32:20
在数字阅读逐渐普及的当下,电子书资源的规模呈指数级增长。面对海量且分散的元数...
发布日期: 2025-08-20 12:54:01
日常办公中,经常需要从大量文档中快速抓取核心信息。某款支持自定义词库的文本处...

发布日期: 2025-04-28 15:27:54
随着数字阅读普及,电子书资源呈现分散化趋势。小说爱好者常面临资源格式混乱、平...

发布日期: 2025-03-22 12:17:43
现代人每天面对海量文件、冗余缓存、过期信息,手动清理耗时费力。一款能够根据用...
发布日期: 2025-06-26 14:12:02
在数字资产管理领域,专业摄影师张磊最近遇到了棘手难题。他耗时三个月拍摄的纪录...
发布日期: 2025-08-04 16:54:02
近年来,随着电子书市场的持续升温,支持EPUB格式的阅读工具逐渐成为用户刚需。作为...

发布日期: 2025-04-11 17:10:05
纸质书与电子书共存的年代,阅读场景变得愈发多元。地铁通勤时用手机看小说,咖啡...
发布日期: 2025-07-15 18:48:02
办公桌前的程序员盯着屏幕皱起眉头——代码注释区需要醒目的提示文字,千篇一律的...

发布日期: 2025-03-31 16:58:04
当用户从网盘下载一份重要工程图纸时,传输过程中可能因网络波动导致文件损坏。某...

发布日期: 2025-05-24 15:07:57
在数据驱动的商业环境中,数据库权限管理是保障企业信息安全的基石。随着业务复杂...

发布日期: 2025-05-23 11:37:12
在数字化协作场景中,多用户环境下的资源配置效率一直是技术落地的难点。随着企业...
发布日期: 2025-07-02 17:36:01
现代生活中,时间管理工具早已成为刚需。对于追求效率的人来说,倒计时器不仅是简...
发布日期: 2025-05-23 12:13:14
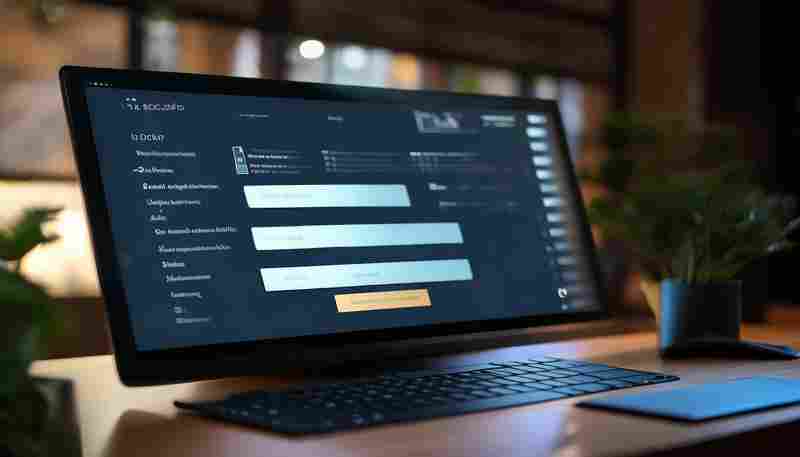
用户登录认证是Web应用的基础功能,Flask框架通过轻量级扩展为开发者提供了灵活的实...
发布日期: 2025-07-31 09:12:01
企业级业务系统中,超过68%的安全事件始于异常登录行为。某互联网公司近期上线的登...
发布日期: 2025-08-06 12:24:01
在信息爆炸的社交媒体时代,一个独特的用户名不仅是个人品牌的起点,更是吸引关注...

发布日期: 2025-05-05 12:37:17
纸质书的厚重感逐渐被电子墨水屏替代,碎片化阅读习惯却带来新困扰:通勤路上用手...
发布日期: 2025-07-25 11:06:01
现代人的电子桌面总是塞满文件与图标,偶尔瞥见角落跳出一行文字:"焦虑的反面是具...

发布日期: 2025-04-28 13:26:14
许多用户发现,Windows系统运行多年后总会积累各种"历史包袱"。当尝试通过系统自带的...
发布日期: 2025-04-24 12:09:46
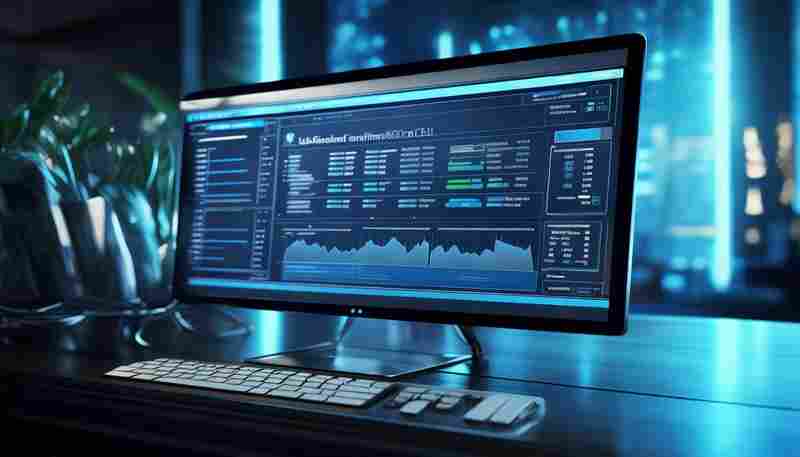
日志管理对于系统安全的重要性不言而喻。在Windows环境中,用户账户控制(UAC)日志记...
发布日期: 2025-07-06 17:42:02
在数字时代,用户密码泄露事件频发,如何安全存储敏感信息成为开发者必须面对的挑...
发布日期: 2025-06-24 09:36:01
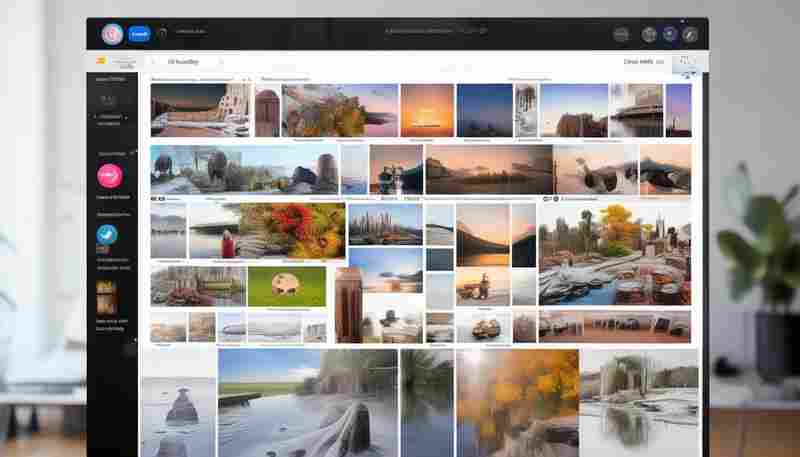
这张产品图上传总提示尺寸过大,能不能压缩到500KB以下?"电商美工小林盯着后台反复...
发布日期: 2025-06-10 13:42:01
在数字图像处理领域,批量处理工具往往能带来肉眼可见的效率提升。本文探讨的这款...

发布日期: 2025-04-11 11:01:21
午后三点半的办公室,显示器右下角突然浮现卡通企鹅的弹窗:"该起来活动颈椎啦!...

发布日期: 2025-04-02 11:58:43
现代工作场景中,时间管理能力直接影响个人效率与团队协作质量。用户活动时间统计...

发布日期: 2025-05-23 15:08:58
在信息爆炸的社交时代,品牌、自媒体和个体用户面临一个共同难题:如何在有限时间...
发布日期: 2025-08-12 18:51:01
许多用户在卸载商业软件时容易忽略一个隐患——许可证激活过程中生成的临时文件。...
发布日期: 2025-08-05 11:06:01
在数字出版行业,电子书格式转换效率直接影响着知识传播速度。某开发团队推出的...

发布日期: 2025-04-03 13:33:26
在数字化办公场景中,网络带宽的动态分配与监控直接影响团队协作效率。针对企业或...

发布日期: 2025-04-20 19:57:35
为社交媒体账号取一个独特且易记的用户名,常让人抓耳挠腮。注册时反复提示“用户...

发布日期: 2025-05-12 15:32:57
纸质书爱好者常面临一个困扰:如何高效整理扫描版书籍的目录?传统手动输入既费时...

发布日期: 2025-05-03 14:31:41
打开视频网站被120秒广告轰炸,滑动新闻资讯被伪装成文章的推广打断,当代网民对网...

发布日期: 2025-06-13 10:12:03
电子书阅读器近年来逐渐摆脱单一功能定位,多格式兼容设备开始成为市场主流。这类...

发布日期: 2025-04-08 13:23:35
互联网时代,信息获取效率成为刚需。对于依赖RSS订阅追踪资讯的用户而言,传统阅读...

发布日期: 2025-03-24 09:06:13
在企业运维与系统管理中,日志文件如同系统的"健康档案",每天产生的海量数据中可...
发布日期: 2025-07-01 10:48:01
在数据处理领域,过滤系统的设计直接影响着业务需求的响应速度。传统硬编码模式常...
发布日期: 2025-06-30 10:24:02
在暗色调的终端窗口中,闪烁的光标突然跃出一枚旋转的磁芯图标,青蓝渐变的进度条...

发布日期: 2025-06-03 13:54:02
在快节奏的现代职场中,会议记录的整理往往成为效率洼地。传统人工记录方式不仅耗...

发布日期: 2025-05-16 12:18:27
在数字化业务快速发展的背景下,企业用户账号体系日益复杂,跨平台账号权限管理成...

发布日期: 2025-05-06 19:11:50
在数字阅读场景中,电子书格式兼容性与目录结构混乱常成为用户痛点。一款高效的工...

发布日期: 2025-04-10 17:20:28
通勤地铁里戴着耳机的上班族,深夜熄灯后辗转反侧的学生党,这些现代人习以为常的...

发布日期: 2025-03-30 13:20:45
在全球化的商业场景中,货币代码的准确性直接影响交易效率和数据处理能力。为满足...
发布日期: 2025-05-26 12:55:43
在数字资产管理领域,开发人员最近开始频繁使用一种被称为"二进制元数据编辑器"的...