
发布日期: 2025-07-03 10:30:02
在信息爆炸的互联网时代,快速获取目标数据已成为许多从业者的刚需。无论是市场调...

发布日期: 2025-04-08 18:30:42
局域网消息广播工具凭借其实时性高、操作简单的特点,逐渐成为团队协作、临时通知...

发布日期: 2025-05-13 09:04:04
窗外的雨滴敲打着玻璃,天气预报却总在手机里沉睡。当工作文档铺满屏幕时,突然弹...
发布日期: 2025-06-24 19:00:02
窗外的蝉鸣声断断续续传来,显示屏前的手指在键盘上敲出残影。当程序员小张试图复...

发布日期: 2025-03-27 11:55:18
对于频繁接触电子文档的办公族和学生群体来说,PDF文件的合并拆分需求几乎每天都在...

发布日期: 2025-04-13 09:29:40
网络安全工程师李明在检测某政务系统时,发现其响应头缺失关键安全配置,攻击者仅...

发布日期: 2025-06-12 12:24:02
网络质量监测领域正面临新的挑战:如何在多终端并发场景下直观呈现不同设备的测速...

发布日期: 2025-05-28 10:37:48
在远程协作与线下会议并行的数字化办公场景中,屏幕画笔工具正逐渐成为提升沟通效...
发布日期: 2025-07-02 14:12:01
协议栈的阴影中总潜伏着网络工程师的困惑。当tcpdump抓取的海量数据令人目眩,Wires...

发布日期: 2025-05-12 13:12:39
科研与工程领域的数据分析常面临多维数据可视化难题。传统二维图表难以展现变量间...

发布日期: 2025-03-24 10:56:01
市面上绘图软件种类繁多,但对于只需要处理基础图形的用户而言,功能复杂的大型软...

发布日期: 2025-04-10 12:51:51
传统聚会游戏在数字时代焕发新生。一款基于局域网联机的画图猜词工具,正成为办公...
发布日期: 2025-06-26 19:42:01
在Windows系统中,任务栏右侧的系统托盘区域常因图标堆积显得杂乱。第三方软件自启动...
发布日期: 2025-07-04 15:42:02
矩阵运算在密码学领域有着天然的应用优势——通过数学变换实现数据混淆。本文将介...

发布日期: 2025-04-28 09:00:02
在日常学习、工程建模或数据分析场景中,复杂运算往往需要依赖专业工具。对于普通...
发布日期: 2025-07-09 13:54:02
数独作为经典的逻辑游戏,长期占据益智类活动的热门榜单。手动设计数独题目不仅耗...

发布日期: 2025-06-02 16:15:02
在企业数字化转型的浪潮中,服务网络的稳定性直接影响业务运转效率。传统人工排查...

发布日期: 2025-05-28 15:57:01
在程序开发领域,效率工具的选择往往直接影响工作流质量。近期某开发者社区出现了...

发布日期: 2025-04-05 12:26:27
互联网时代的数据采集需求呈现出碎片化与即时化特征。针对中小型业务场景的快速数...

发布日期: 2025-04-17 10:18:17
在服务器运维和网络调试场景中,图形化测速工具往往力不从心。当工程师需要通过...

发布日期: 2025-05-02 11:30:01
互联网数据采集过程中,数据存储环节直接影响后续分析的效率与可靠性。SQLite与CSV作...

发布日期: 2025-05-02 13:31:35
蛇形像素在屏幕上灵活游走,吞下食物后身体逐渐变长——贪吃蛇的玩法看似简单,却...
发布日期: 2025-06-19 09:48:01
现代办公场景中,任务管理效率直接影响工作质量。近期发现一款名为TimeBox的桌面弹窗...

发布日期: 2025-05-28 09:11:17
网络请求处理能力直接影响着现代应用的响应速度。传统同步阻塞模型在应对高并发场...
发布日期: 2025-06-26 13:54:02
在Python技术生态中,Flask框架因其轻量灵活的特性,常被开发者用于快速搭建各类Web应...
发布日期: 2025-07-15 11:06:01
定时网络测速工具的数据存储系统正成为网络运维领域的热门研究方向。该系统通过自...

发布日期: 2025-03-22 09:58:53
窗边透进的阳光在屏幕上投下光斑,指尖敲击键盘的声音戛然而止——历时三周迭代的...

发布日期: 2025-05-18 17:42:33
在电脑屏幕右下角,总有个半透明窗口顽固地驻守着,无论切换多少程序界面,始终展...

发布日期: 2025-04-13 17:12:01
网络安全领域,漏洞扫描是基础设施防护的第一道防线。一款基于Nmap开发的轻量化漏洞...

发布日期: 2025-05-24 12:12:00
凌晨三点的办公室,显示器蓝光映着程序员小张的黑眼圈。他正在调试的支付接口突然...
发布日期: 2025-06-27 18:36:01
在企业数字化转型的背景下,共享文件夹已成为团队协作的核心工具。由于文件权限混...
发布日期: 2025-05-15 10:56:43
随着企业网络规模的指数级增长,传统日志分析工具已难以满足实时监控需求。某科技...

发布日期: 2025-04-26 11:22:23
在数字化办公与内容创作成为主流的当下,屏幕录制需求呈现爆发式增长。某款国产录...

发布日期: 2025-05-13 12:06:03
——简易时钟屏保使用手札 当电脑屏幕逐渐暗下的瞬间,数字忽然从黑暗深处浮现。这...

发布日期: 2025-05-29 13:54:01
在数字化办公场景中,纸质文档的电子化需求日益增长。一款基于API接口的简易OCR(光...

发布日期: 2025-03-23 10:29:34
某科技公司安全团队在2022年的内网渗透测试中,意外发现攻击者使用新型分布式端口扫...

发布日期: 2025-04-12 11:03:22
当代人获取信息的场景日益碎片化,文字转语音工具逐渐成为提升效率的刚需。对于注...
发布日期: 2025-05-12 09:11:27
许多人都有过类似体验:新电脑开机仅需10秒,使用半年后开机时间翻倍;系统运行中...

发布日期: 2025-03-23 09:04:01
跨国旅行时盯着天气预报发愁,网购海外商品对重量单位一头雾水,菜谱里的烤箱温度...
发布日期: 2025-07-04 12:18:01
将电脑键盘转化为钢琴键盘的创意工具,正成为音乐爱好者探索旋律的新宠。这类钢琴...

发布日期: 2025-04-17 11:37:01
电脑屏幕前堆叠着五颜六色的便签,手机里装了三款任务管理APP,记事本上歪歪扭扭的...

发布日期: 2025-03-29 15:53:51
办公族和设计师的电脑桌面上,总会出现各种截图工具的身影。在众多同类软件中,区...

发布日期: 2025-06-13 17:00:01
在数字内容创作与远程协作日益普及的背景下,屏幕录制工具逐渐成为职场、教育等场...

发布日期: 2025-04-06 18:46:52
在局域网协作或远程服务器管理中,文件传输效率直接影响工作进度。传统U盘拷贝、社...
发布日期: 2025-06-15 14:06:02
信息爆炸时代,每天面对数百条未读资讯的焦虑困扰着每个互联网用户。当主流社交平...

发布日期: 2025-04-23 16:04:06
清晨的阳光斜照进书房,台式机屏幕右下角跳动着规整的电子数字。07:32:18,光标在文...

发布日期: 2025-04-22 19:55:05
机顶盒蓝光电影加载到一半卡住,视频会议中途画面突然模糊,在线游戏人物动作莫名...

发布日期: 2025-06-03 13:42:02
当光标在文档里第八次闪烁时,小王突然发现咖啡厅邻座的陌生人正盯着他的屏幕。作...
发布日期: 2025-04-25 15:23:52
面对现代软件开发中高频的接口调试需求,传统测试工具常因环境配置复杂、学习成本...
发布日期: 2025-05-04 18:25:03
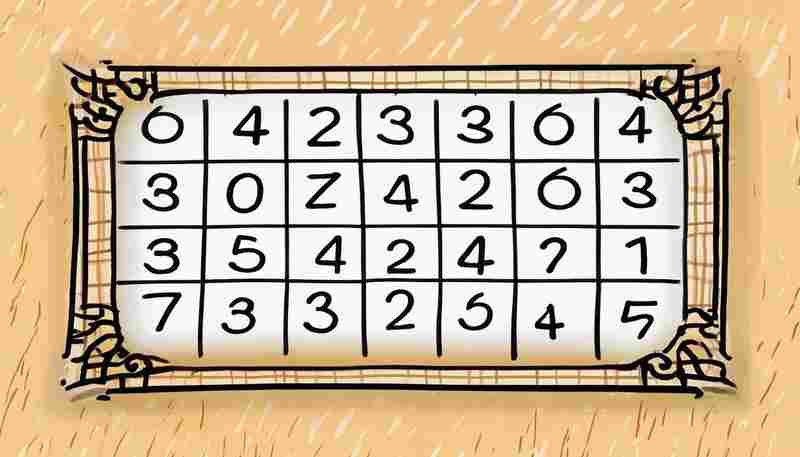
1. 界面简洁,门槛低 打开工具的初始界面,用户会直接看到三个难度选项按钮:初级、...
发布日期: 2025-06-06 15:42:02
在数据处理场景中,SQLite因其无需服务器、零配置的特性,成为中小型项目的热门选择...
发布日期: 2025-07-02 15:30:02
南京理工大学计算机学院团队于2023年春季学期启动的"易转"项目,在校园信息化建设浪...

发布日期: 2025-05-12 09:58:16
地铁通勤族老张最近迷上了科技博客,但每次掏出手机总会遭遇隧道里的信号盲区。直...

发布日期: 2025-04-25 14:23:17
系统运维工程师常会遇到服务异常终止的情况。去年某次线上事故促使我动手开发了一...
发布日期: 2025-04-03 14:16:29
阳光透过办公室玻璃斜射在桌面,财务专员张蕊第三次核对报表数据时,发现某栏数字...

发布日期: 2025-04-11 11:29:48
现代职场中,人脉资源管理的重要性日益凸显。面对频繁变动的和同事联络方式,传统...

发布日期: 2025-05-03 11:32:49
纽约街头的温度计显示华氏75度,巴黎商场的手表标注38毫米表盘,东京超市的牛排标价...

发布日期: 2025-05-06 17:49:43
机箱风扇嗡嗡作响的机房角落,两位程序员正盯着屏幕上的代码。左侧显示器跳动着...

发布日期: 2025-05-26 19:45:33
打开电脑准备整理文档时,常会遇到需要快速抓取关键词的情况。传统的手工记录方式...

发布日期: 2025-05-24 09:58:48
互联网图片资源的批量获取常面临效率瓶颈。针对数据采集、素材归档等场景,开发人...