
发布日期: 2025-07-16 18:24:02
当代计算机设备的性能愈发强大,硬件参数监控逐渐从极客专属走向大众刚需。面对市...
发布日期: 2025-06-13 09:54:01
在医学教育领域,解剖学作为基石学科始终面临教学效率与深度平衡的难题。传统教学...
发布日期: 2025-03-28 16:54:43
运行在Windows系统上的PyQt资源监控工具,凭借其简洁的仪表盘界面,实时追踪着计算机...

发布日期: 2025-06-03 10:12:02
数字化系统迭代过程中,协议版本的差异常常成为隐藏的""。某金融科技公司在2023年的...

发布日期: 2025-06-18 17:24:01
网络应用开发测试过程中,开发者常会遇到网络波动带来的异常状况。某次用户反馈某...

发布日期: 2025-06-23 11:00:01
在信息化办公场景中,工单流转效率直接影响着企业服务质量。某科技公司曾因未及时...

发布日期: 2025-04-26 18:20:16
在数据中心或云平台中,系统服务的稳定性直接影响业务连续性。某次凌晨三点,某电...
发布日期: 2025-04-17 11:33:22
办公电脑突然蓝屏的瞬间,设计师张明手心沁出了冷汗——项目方案文档刚完成最后修...

发布日期: 2025-04-04 14:52:36
考场内,考生点击"提交"按钮的瞬间,答卷数据已沿着光纤抵达云端服务器。这个看似...
发布日期: 2025-07-31 13:30:01
在日常工作中,许多人遇到过这样的场景:从网络下载文件后,系统无法正确识别格式...

发布日期: 2025-05-12 17:28:08
在信息爆炸的数字化时代,医疗健康领域每天产生海量数据。某三甲医院的市场部门曾...

发布日期: 2025-05-20 15:54:23
在计算机系统资源管理领域,熟练掌握进程控制工具是每位技术人员的必修课。当应用...
发布日期: 2025-05-09 15:13:08
电脑运行大型程序时,风扇呼啸声常让人担心硬件是否在"超负荷工作"。事实上,CPU温...
发布日期: 2025-07-17 12:12:01
金融市场每秒钟都在产生海量数据,股票价格波动往往以毫秒为单位。传统人工盯盘模...

发布日期: 2025-03-27 14:03:34
现代仓储管理中,库存数据的准确性直接影响企业运营效率。传统人工盘点模式存在耗...

发布日期: 2025-04-06 18:25:32
当某高校学生会主席发现年度"十佳社团"评选票数一夜暴涨三倍时,传统投票系统的脆...
发布日期: 2025-07-18 16:54:01
Windows系统更新后,C盘莫名少了几个G的存储空间;macOS升级时,磁盘空间总提示不足。...

发布日期: 2025-03-25 17:57:02
在分布式系统与物联网设备大规模部署的当下,毫秒级的时间误差可能导致数据不一致...

发布日期: 2025-04-02 14:17:29
在游戏行业,玩家评论是衡量产品口碑的重要指标,但海量评论的实时监测与情感分析...

发布日期: 2025-05-21 18:32:34
在日常使用计算机的过程中,系统内存占用过高导致的卡顿、程序崩溃等问题时常困扰...
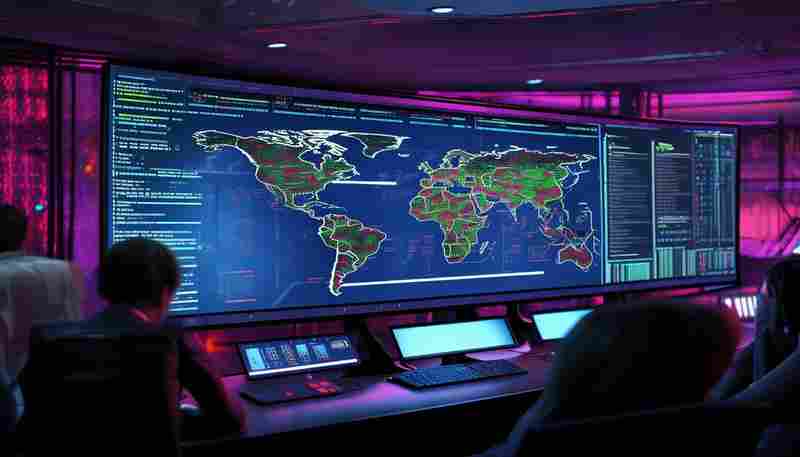
发布日期: 2025-05-06 14:18:41
网站稳定性如何保障?对于运维团队而言,每分钟的宕机都可能带来直接经济损失。某...

发布日期: 2025-06-05 11:48:02
在分布式架构主导的现代IT环境中,日志文件以每秒数万条的速度生成,传统的人工巡...

发布日期: 2025-05-01 13:33:01
在Linux服务器运维领域,文件系统的Inode管理常被称为"隐形杀手"。某中型电商平台曾因...

发布日期: 2025-05-07 10:25:03
在数字化进程加速的当下,企业核心数据与系统的安全性面临严峻挑战。内部人员操作...

发布日期: 2025-05-17 18:11:03
清晨六点的咖啡后厨,烘焙师发现手冲单品豆库存仅剩三天用量,而供应商备货周期需...

发布日期: 2025-06-02 19:27:02
纸质实验报告堆积成山的场景正在从高校实验室消失。某生物实验室助教张老师打开电...
发布日期: 2025-07-30 16:30:02
在工业自动化与物联网应用场景中,海量的设备运行数据如同血液般在系统内流动。某...

发布日期: 2025-04-26 09:04:24
移动应用开发流程中,资源文件管理是容易引发生产事故的隐蔽雷区。某头部社交App曾...
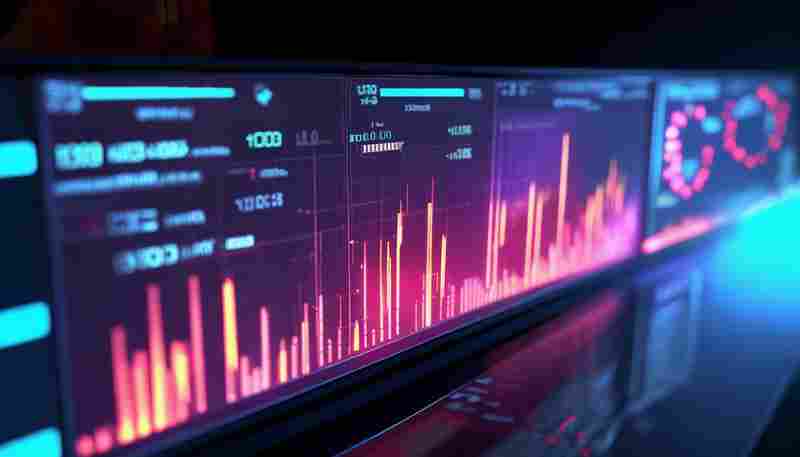
发布日期: 2025-05-11 11:49:10
系统温度监控与告警通知工具在数据中心运维、工业设备管理等领域已成为刚需。随着...

发布日期: 2025-03-22 12:16:01
志愿者活动的组织常面临人力协调复杂、时间冲突频发、信息同步滞后等问题。传统的...

发布日期: 2025-04-01 16:25:46
在数字设备深度融入日常的当下,系统通知中心逐渐成为用户与设备交互的核心入口。...

发布日期: 2025-03-30 11:16:02
在数字化场景中,进程管理直接影响着系统稳定性与资源利用率。开发者和运维人员每...

发布日期: 2025-05-06 11:20:10
Windows任务管理器按下Ctrl+Shift+Esc的瞬间,总有人盯着满屏陌生进程发懵。系统进程快速...
发布日期: 2025-05-05 17:49:25
对于刚接触Web开发的新手而言,Flask框架就像工具箱里的瑞士军刀。这个采用Python语言...
发布日期: 2025-07-08 12:18:01
对于需要快速搭建在线交流平台的开发者而言,Django框架提供的工具链堪称效率加速器...

发布日期: 2025-04-10 11:12:01
在数据处理与系统集成的场景中,JSON与XML作为两种主流数据交换格式,常需要在不同场...

发布日期: 2025-04-18 11:09:40
运维工程师的电脑屏幕上,十台服务器指标曲线突然同时飙升。当他点开报警邮件时,...

发布日期: 2025-05-19 19:34:52
企业数据中心运维主管张工盯着屏幕上跳动的数据曲线,突然发现某台服务器的内存占...
发布日期: 2025-05-22 16:54:02
在各类线下沙龙、社区活动频繁举办的当下,活动组织者常面临报名信息收集的难题。...

发布日期: 2025-04-26 15:03:43
运维工程师的电脑屏幕突然弹出红色警告——服务器磁盘使用率突破95%。点开详情查看...

发布日期: 2025-06-18 13:24:01
当我们在Windows资源管理器双击打开ZIP文件时,很少有人会注意那些隐藏在属性窗口里的...
发布日期: 2025-07-19 15:36:01
在Windows系统的日常维护中,注册表启动项管理始终是绕不开的课题。对于普通用户来说...
发布日期: 2025-04-24 11:16:16
在分布式架构与混合云环境逐渐普及的当下,企业对于资源监控数据的实时处理需求呈...
发布日期: 2025-05-06 13:43:02
在数字化管理体系中,用户权限控制直接影响企业数据安全与运营效率。角色分配模块...

发布日期: 2025-04-24 17:34:48
农历节日承载着中华文化的深厚底蕴,从春节的爆竹声到中秋的明月夜,每个节点都凝...
发布日期: 2025-07-24 10:54:01
当开发者安装Python时明明配置了路径却提示"命令未找到",运维人员部署服务时端口号...

发布日期: 2025-05-19 15:26:19
现代软件开发体系中,自动化测试脚本分发系统正在成为质量保障体系的中枢神经。在...

发布日期: 2025-05-05 14:27:50
在教育测评、职业认证或企业内部培训场景中,如何高效生成试卷并确保题目分配的公...

发布日期: 2025-04-04 16:50:15
当电脑屏幕右下角的图标群开始闪烁时,多数人只会机械性地点击关闭弹窗。但在这个...

发布日期: 2025-03-23 13:40:01
电脑突然卡成PPT?软件闪退找不到原因?后台进程偷偷吃掉大半内存?一套轻量级系统...
发布日期: 2025-06-17 09:18:02
在电脑长时间运行或执行高负荷任务时,后台服务的资源占用问题常常成为卡顿、死机...

发布日期: 2025-04-16 11:16:14
互联网信息的动态更新特性催生了网页监控工具的普及。这类工具通过定时抓取目标页...
发布日期: 2025-07-22 10:54:02
在日常计算机使用中,系统卡顿、程序无响应等问题常源于进程对硬件资源的过度占用...

发布日期: 2025-05-05 19:41:05
某智慧园区运维团队曾经历过一起离奇事件:夜间两点,园区内路灯控制系统突然离线...

发布日期: 2025-04-20 10:55:50
在信息爆炸的数字化时代,专注力正成为稀缺资源。某款名为FocusGuard的桌面端效率管理...

发布日期: 2025-06-13 12:24:02
核心机制 游戏以生成1-100区间的随机整数为起点,玩家通过输入框提交猜测值。系统每...
发布日期: 2025-05-03 11:54:10
近年来,电影市场呈现爆发式增长,票房数据量级逐年攀升。传统的数据分析方式依赖...

发布日期: 2025-03-25 14:16:05
价格波动背后的市场密码 打开手机购物软件,消费者总能看到琳琅满目的促销标签。对...

发布日期: 2025-06-08 14:06:02
服务器机房里此起彼伏的蜂鸣声中,某电商平台的技术总监突然收到一条报警短信——...

发布日期: 2025-04-05 09:03:27
在Linux服务器运维实践中,工程师常需要面对数十个后台进程的监控需求。传统的手动...