
发布日期: 2025-07-22 18:54:01
在技术写作与文档管理领域,Markdown因其简洁语法持续占据主流地位。当需要将.md文件...

发布日期: 2025-05-24 12:08:13
互联网世界每天都在产生数以万计的失效链接。某电商平台曾因促销活动页面出现商品...

发布日期: 2025-04-04 15:53:15
密码管理领域近年迎来新突破:基于动态算法与本地化存储的密码提示工具逐渐成为主...
发布日期: 2025-07-02 19:06:02
打开手机浏览器刷新第五次时,张明突然意识到自己患上了"更新焦虑症"。作为资深网...
发布日期: 2025-07-24 09:36:01
当你在电商网站浏览商品后,社交平台立即推送相关广告;当你在不同网站看到同一款...
发布日期: 2025-07-08 10:42:01
Windows系统自带的文件夹树状图导出功能隐藏颇深,每次都需要通过命令行操作。对于项...

发布日期: 2025-04-28 19:45:01
![] 在数字化协作成为主流的今天,开发者、产品经理和内容创作者们正在寻找更高效的...
发布日期: 2025-04-26 12:12:19
一键生成数据统计报告:智能工具如何释放数据分析潜力 在数据驱动的决策环境中,快...

发布日期: 2025-06-22 10:42:01
互联网应用中,网站可用性直接影响用户体验与业务稳定性。当页面出现访问异常时,...
发布日期: 2025-04-28 18:22:49
在信息爆炸的互联网场景中,分页功能是网站处理海量数据的核心模块。无论是电商平...

发布日期: 2025-03-27 19:24:01
在信息爆炸的时代,Markdown凭借其轻量化、易读易写的特性,成为程序员、内容创作者...

发布日期: 2025-04-21 14:22:51
互联网时代,网站作为企业与用户之间的核心纽带,其稳定性直接影响业务运转效率。...
发布日期: 2025-05-20 15:07:53
在数字化办公场景中,Excel作为数据处理的核心工具,承载着企业运营、财务核算、市...

发布日期: 2025-04-07 10:45:51
互联网时代,SSL证书如同网站的“身份证”,承担着加密数据传输、验证服务器身份的...

发布日期: 2025-05-12 17:50:05
在数字化办公场景中,周报撰写常被视为机械重复的负担。某互联网公司研发部门近期...

发布日期: 2025-04-28 18:15:43
在数字影像爆炸的时代,整理照片并高效展示成为许多人的痛点。传统方法依赖手动编...
发布日期: 2025-05-26 12:19:43
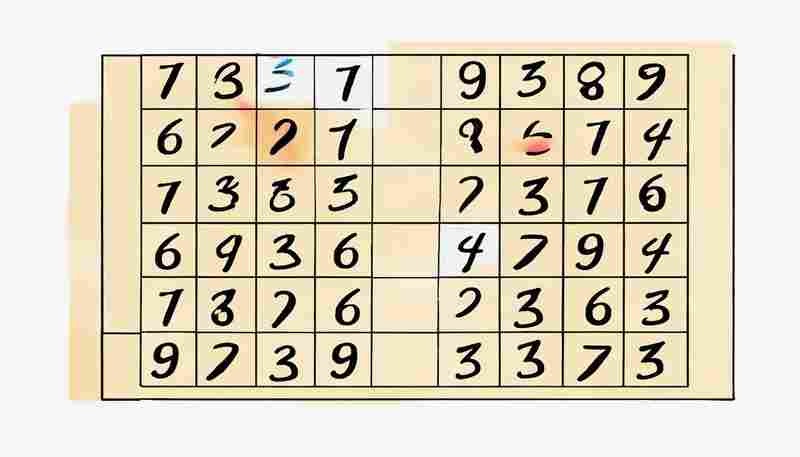
数独作为经典的逻辑游戏,其数字排列的数学规律与规则设计值得深入探讨。本文将以...
发布日期: 2025-07-20 09:42:01
求职市场信息过载的时代,某款自主研发的招聘信息采集系统正在人力资源领域掀起波...

发布日期: 2025-04-09 11:13:43
某次网站架构升级时,我在服务器日志里发现上百个失效链接。传统文本编辑器处理多...
发布日期: 2025-04-30 09:09:01
开发者在创建新项目时,常常需要反复确认目录结构的完整性。某次团队协作中,因为...
发布日期: 2025-06-24 15:12:01
每周五下午,办公室里总会响起此起彼伏的键盘敲击声——写周报几乎是每个职场人的...

发布日期: 2025-05-31 18:09:02
在电商平台的用户行为分析场景中,某数据团队曾因字段命名歧义导致分析方向错误—...

发布日期: 2025-04-09 12:21:24
在快节奏的现代生活中,许多人渴望通过文字寻找片刻的宁静或灵感,却常因创作门槛...

发布日期: 2025-05-03 11:36:25
清晨八点的办公室键盘声此起彼伏,行政人员正在手动调整合同条款,财务专员重复着...

发布日期: 2025-03-30 19:31:22
屏幕上的迷宫路径如同生长中的植物根系,在随机与规则的平衡中蜿蜒伸展。借助Pyt...

发布日期: 2025-04-16 09:50:46
实验室场景中的数据处理与报告撰写常被视为科研链条中耗时最长的环节。某高校课题...

发布日期: 2025-03-27 18:59:11
互联网时代,网页加载速度每延迟1秒,用户跳出率就会上升7%。某金融科技公司曾因服...

发布日期: 2025-05-22 17:01:13
在数字时代,文件管理是每个职场人绕不开的痛点。设计师的PSD源文件与JPG预览图混作...

发布日期: 2025-05-29 19:24:01
课程表自动生成器作为现代教育管理场景中的实用工具,正在逐步改变传统人工排课的...

发布日期: 2025-05-12 12:40:09
在某个深夜的编程场景里,开发者正面对三个月前写的复杂算法模块抓耳挠腮。这个场...

发布日期: 2025-04-08 16:04:42
在Web开发与安全维护中,Cookie作为用户身份验证的关键载体,直接影响网站功能的稳定...

发布日期: 2025-05-19 14:07:41
短视频时代,封面图点击率直接决定内容生死。某平台数据显示,优质封面的作品播放...

发布日期: 2025-06-03 19:24:01
凌晨三点的办公室,技术负责人李明盯着屏幕上的用户流失数据陷入沉思。两周前公司...
发布日期: 2025-07-27 13:54:01
权限管理作为企业信息化建设的重要环节,直接影响着数据安全与团队协作效率。传统...

发布日期: 2025-06-09 12:54:02
二维码作为信息传递的重要载体,已渗透至零售、物流、医疗等各个领域。但二维码本...

发布日期: 2025-03-28 11:13:30
清晨打开电脑,桌面右下角跳动的数字让人心头一暖——距离春节还有38天。这个突然...

发布日期: 2025-04-05 09:10:43
在信息爆炸的数字化时代,各类组织机构每天需要处理的文档量级呈几何倍数增长。传...
发布日期: 2025-07-06 13:48:01
当用户点击页面跳转到404报错界面时,超过83%的访问者会选择直接离开网站。这个数据...

发布日期: 2025-03-31 12:59:41
职场人的简历焦虑从未消失。纸质简历堆在HR桌上平均停留7秒的残酷现实,与求职网站...

发布日期: 2025-06-11 11:45:01
在互联网技术快速迭代的今天,Cookie作为网站与用户交互的核心媒介,直接影响用户体...

发布日期: 2025-05-08 11:57:32
在Python生态中,基于Tkinter开发的数独游戏生成器悄然走红。这款不足千行代码的工具,...
发布日期: 2025-06-24 16:06:01
互联网时代,获取有效信息成为刚需。针对特定网站的标题与链接抓取,市面上已有多...

发布日期: 2025-06-03 19:12:01
互联网时代,个人博客依然是展示专业能力的核心阵地。面对五花八门的建站工具,技...
发布日期: 2025-07-13 17:30:02
在商业活动中,账单邮件的处理是财务流程中不可忽视的一环。传统人工操作不仅耗时...

发布日期: 2025-05-05 11:11:43
在软件开发和数据管理领域,数据库表关系图的绘制往往成为技术团队效率提升的关键...

发布日期: 2025-04-24 14:47:13
传统试卷制作流程中,教师常需耗费数小时筛选题目、调整难度、排版格式。某款基于...

发布日期: 2025-04-25 11:42:57
打开电脑准备设计官网时,面对空白的画布和零散的灵感,设计师总会在配色环节陷入...
发布日期: 2025-07-05 15:18:01
在知识产权领域,专利复审请求的撰写质量直接影响案件审查进度与最终结果。传统人...

发布日期: 2025-04-08 17:01:43
当代社交场景中,表情包早已超越单纯的娱乐工具,成为年轻人表达情绪、化解尴尬的...

发布日期: 2025-04-07 15:30:46
在企业数字化转型浪潮中,市场分析、运营复盘等场景对动态报告的需求激增。某互联...
发布日期: 2025-06-26 11:42:01
企业日常运营中常面临数据处理效率低、图表制作耗时长的问题。手动整理海量Excel表...
发布日期: 2025-07-04 16:48:01
在电商平台突增百万流量导致服务器崩溃的案例中,某技术团队依靠自主研发的监测系...
发布日期: 2025-06-29 12:06:01
打开招聘网站,三成求职者因简历格式混乱被淘汰;投递五十份简历,仅有五份获得回...

发布日期: 2025-05-27 19:41:48
在科研论文的撰写过程中,致谢部分常被视为“形式化环节”,但其重要性不容忽视。...
发布日期: 2025-05-18 10:46:26
项目管理领域正面临数据整合与效率提升的双重挑战。某科技公司市场部曾因手工整理...

发布日期: 2025-04-07 18:40:35
对于语言学习者而言,记忆词汇始终是道必须跨越的门槛。市面上常见的背词软件往往...

发布日期: 2025-04-18 09:55:19
午市高峰时段,某连锁餐饮品牌的店长正被三拨客人同时询问WiFi密码。新入职的服务生...

发布日期: 2025-04-16 11:02:01
在信息爆炸的互联网时代,知乎平台每天产出数万条优质回答,其中高赞内容往往凝聚...

发布日期: 2025-04-16 09:29:15
打开手机刷了三次小说页面,最新章节依然停留在昨天的内容。这种抓狂的体验,每个...

发布日期: 2025-03-24 13:19:34
在数据驱动的现代工作场景中,自动化生成标准化报告的需求持续增长。基于Python生态...