
发布日期: 2025-04-08 10:32:25
窗外的雨滴敲打着玻璃,手边的数位板突然有了温度——最近偶然发现一款名为「Can...

发布日期: 2025-04-10 17:48:59
在众多休闲益智游戏中,数字猜谜因其规则简单却充满挑战性,始终保持着独特魅力。...

发布日期: 2025-04-01 11:22:11
音乐播放器早已突破单一播放功能,在本地文件管理与个性化体验领域不断进化。近期...

发布日期: 2025-03-25 13:37:09
走廊的智能灯突然熄灭,车间传感器数据延迟,农业大棚温控系统显示离线——物联网...

发布日期: 2025-04-14 18:25:38
在网站运维过程中,断链、死链的存在不仅影响用户体验,还会导致搜索引擎排名下滑...
发布日期: 2025-04-14 11:46:48
金融市场瞬息万变,股票价格波动往往在几分钟内决定盈亏。对于无法全天候盯盘的投...

发布日期: 2025-04-18 15:30:36
在信息碎片化时代,越来越多创作者开始寻求自主内容平台。基于Python的Flask框架搭建...

发布日期: 2025-03-24 12:21:50
在Windows系统自带的进程管理器之外,第三方进程管理工具始终保持着稳定的用户需求。...

发布日期: 2025-04-07 18:44:10
清晨八点的地铁车厢里,上班族小陈习惯性掏出手机。不同于周围刷短视频的人群,他...

发布日期: 2025-04-20 15:09:11
企业会议室的白板上还留着上午头脑风暴的油墨痕迹,市场部需要立即收集用户对新产...

发布日期: 2025-04-09 10:37:10
随着数据采集需求的指数级增长,网络爬虫在业务场景中的重要性日益凸显。面对分布...

发布日期: 2025-03-22 11:15:11
远程协作成为常态的今天,线上会议的信息留存常让职场人头疼。某科技团队近期推出...

发布日期: 2025-04-13 16:00:25
在信息爆炸的时代,每天产生的新闻文本以亿计量级增长。如何快速识别核心内容的情...

发布日期: 2025-04-16 09:54:20
互联网数据采集领域持续上演攻防战。某第三方统计平台显示,2023年全球网站部署反爬...

发布日期: 2025-04-11 19:11:49
在办公场所或家庭环境中,设备间的文件传输需求时常困扰着使用者。当U盘不在手边、...

发布日期: 2025-04-02 13:38:16
书桌前散落着未拆封的咖啡包,电脑屏幕上开着三个文档窗口,手机在裤袋里每隔两分...

发布日期: 2025-04-20 11:06:23
在信息过载的互联网环境中,快速整理和调用常用网页链接成为刚需。一款基于Python...

发布日期: 2025-03-23 10:53:32
折腾过汇率换算的朋友都知道,浏览器查汇率总有广告弹窗干扰,手机APP又常要求注册...
发布日期: 2025-04-11 12:02:10
在项目管理领域,效率与责任划分直接影响最终成果。某款以看板模式为核心的协作工...

发布日期: 2025-04-18 17:24:36
俄罗斯方块作为经典益智游戏,其规则简单却充满挑战性。利用PyGame框架开发该游戏,...

发布日期: 2025-04-14 12:33:33
随着Linux服务器数量激增,传统命令行工具已无法满足运维需求。某开源社区近期发布...

发布日期: 2025-04-19 12:28:32
在互联网信息交互场景中,论坛系统始终扮演着重要角色。一款轻量级且功能完备的论...
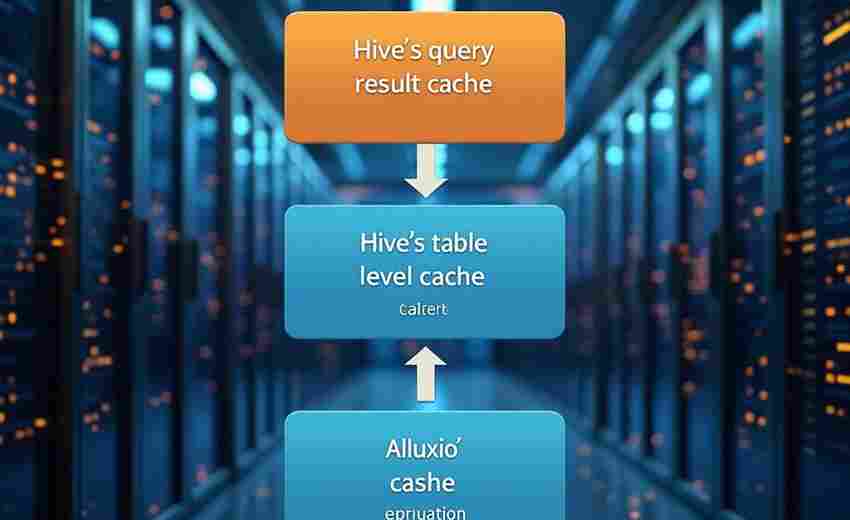
发布日期: 2025-04-07 13:26:14
网络通信开发领域存在一个经典练手项目:基于Socket和多线程的TCP聊天室。这个不足...

发布日期: 2025-03-22 11:20:39
在互联网世界中,域名系统(DNS)如同现实生活中的导航地图。用户输入一个网址后,...

发布日期: 2025-04-05 11:29:27
棋盘界面加载完毕的瞬间,黑白两色的圆形光标在木质纹理背景上微微闪烁。这款仅...

发布日期: 2025-04-14 12:19:16
开发团队在日常工作中,常常需要验证接口是否符合预期。传统的手动测试方式效率低...

发布日期: 2025-04-20 12:50:00
清晨七点的地铁车厢里,指尖在磨砂金属表面划过,实体按键的触感透过指腹传来。这...

发布日期: 2025-04-06 18:46:52
在局域网协作或远程服务器管理中,文件传输效率直接影响工作进度。传统U盘拷贝、社...

发布日期: 2025-04-13 16:32:36
办公桌面的数字文件散落成堆,灵感碎片在聊天窗口与邮件间流浪——信息爆炸时代,...

发布日期: 2025-04-01 14:42:32
在信息爆炸的时代,论坛、贴吧等社区平台每天产生海量讨论内容。如何从繁杂的文本...

发布日期: 2025-03-24 13:47:12
在计算机网络调试与安全分析领域,解析原始网络数据包始终是技术人员的核心需求。...

发布日期: 2025-04-16 18:12:35
在Web开发或日常办公场景中,开发人员经常需要快速启动临时HTTP服务器。相较于配置复...

发布日期: 2025-04-05 18:47:42
窗台上斜放的咖啡杯冒着热气,工程师老张的草稿纸已写满三页算式。他习惯性摸出手...

发布日期: 2025-04-07 13:47:39
在信息爆炸的互联网环境中,企业及个人用户对特定领域数据的追踪需求持续增长。网...

发布日期: 2025-04-12 14:55:38
色块与线条的碰撞总能激发创作灵感,一款得心应手的画板工具能让灵感跃然"板"上。...

发布日期: 2025-04-04 11:15:30
网络管理员和安全研究人员常常需要快速掌握目标主机的端口开放情况。基于命令行的...

发布日期: 2025-03-21 12:32:17
每到发薪日,财务部门总要面对同一类难题:如何在保障员工隐私的前提下,快速完成...

发布日期: 2025-03-28 09:03:28
金融从业者李明第一次接触区块链时,面对"哈希值"、"时间戳"这些专业术语感到困惑。...

发布日期: 2025-04-01 13:52:43
当数字绘画门槛日渐降低,一款轻量级绘图工具依然在设计师群体中保持着不可替代的...

发布日期: 2025-03-22 10:16:01
窗外的天气从晴转阴,电脑屏幕上的壁纸却依然停留在三个月前下载的雪景图。这种场...

发布日期: 2025-04-14 09:45:31
最近在整理个人信息流工具时,发现市面上的RSS阅读器普遍存在功能冗余的问题。尝试...

发布日期: 2025-04-18 10:58:24
在Python生态系统中,屏幕截图功能的实现有多种技术路径。Pillow作为图像处理领域的主...

发布日期: 2025-04-14 09:04:34
一款功能丰富的贪吃蛇游戏工具近期在开发者社区引发关注。这款基于Python开发的开源...

发布日期: 2025-04-03 16:27:46
手机屏幕亮起,国际航班订单显示着245欧元的价格,朋友圈里日本代购的新款手表标价...

发布日期: 2025-03-23 10:36:02
在短视频创作、播客剪辑或音乐混音中,音频过渡的生硬感常让作品质感大打折扣。针...

发布日期: 2025-04-19 09:58:53
现代人手机里总躺着十几个效率工具,真正能坚持使用的却寥寥无几。最近在办公圈小...

发布日期: 2025-03-26 15:48:30
在程序员日常协作中,代码片段的即时共享始终是刚需。最近在技术社区频繁出现的...

发布日期: 2025-03-24 10:56:01
市面上绘图软件种类繁多,但对于只需要处理基础图形的用户而言,功能复杂的大型软...

发布日期: 2025-04-03 19:26:16
在计算机日常运维中,系统进程监控工具与任务管理器如同技术人员的"听诊器"。这类...

发布日期: 2025-04-09 12:57:01
在数字生活逐渐渗透日常的当下,密码管理成为许多人绕不开的难题。频繁的账户注册...

发布日期: 2025-04-02 12:44:36
在大数据时代,获取网络信息的效率直接影响着决策质量。一款支持关键词过滤的简易...

发布日期: 2025-03-31 10:33:28
在网站运维过程中,无效链接如同潜伏的"数字陷阱",不仅损害用户体验,更直接影响...

发布日期: 2025-04-16 15:34:46
互联网匿名访问已成为刚需,但并非所有场景都适合使用代理服务器。不少企业网络明...

发布日期: 2025-03-22 09:31:33
日常工作中最让人头疼的场景莫过于处理多台设备间的文件同步问题。同事小李上周就...

发布日期: 2025-03-24 13:21:14
在局域网环境下实现即时通讯,许多团队仍面临工具适配难题。公共社交平台存在信息...

发布日期: 2025-04-03 17:32:17
电脑屏幕上跳动着十几张旅游风景照,用户将图片批量拖入软件界面,调整好每帧停留...

发布日期: 2025-04-02 09:04:14
在数据处理需求爆炸式增长的当下,网络爬虫已成为获取信息的必备工具。基于Python开...

发布日期: 2025-04-15 17:41:03
电商平台离不开购物车的价格计算逻辑。一套精准的运算系统直接影响用户结算体验,...

发布日期: 2025-03-25 11:09:23
办公桌上堆满的便利贴逐渐被电子工具取代时,一款基于JSON架构的待办清单管理器正在...

发布日期: 2025-04-14 19:21:30
在网络运维或安全检测场景中,端口监听状态排查是高频需求。一款轻量级端口检测工...
")