
发布日期: 2025-04-10 12:02:13
整理办公文档目录曾是多数职场人避不开的枯燥流程。某科技公司市场部的张敏对此深...
发布日期: 2025-05-07 10:35:34
对于习惯用Markdown写作的用户来说,一款简洁高效的本地编辑器往往比在线工具更实用...

发布日期: 2025-04-15 13:48:19
在数字化办公场景中,PDF文档因其跨平台特性成为主流文件格式。面对动辄数百页的行...

发布日期: 2025-04-03 17:10:56
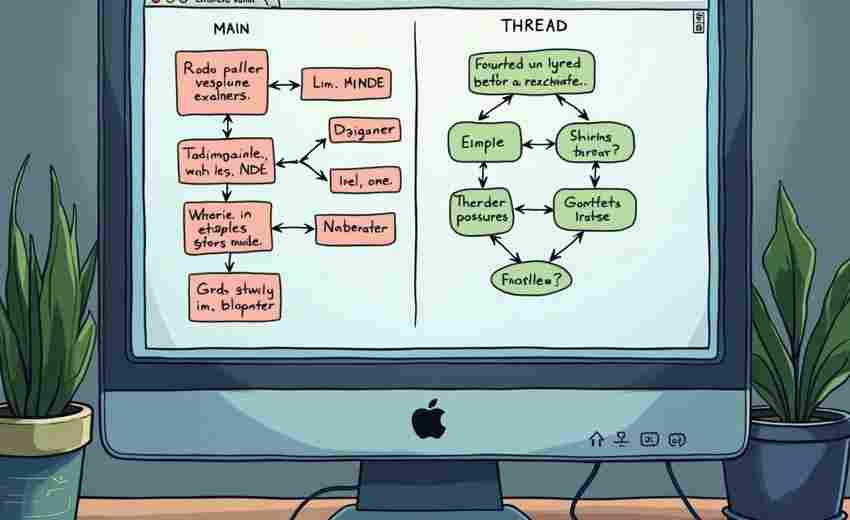
在海量数据时代,信息管理成为每个职场人必须面对的挑战。某科技公司研发的文档分...

发布日期: 2025-04-07 12:15:03
数字办公场景中,Office文档作为信息交互的核心载体,常面临数据泄露与恶意攻击的双...
发布日期: 2025-06-03 19:18:02
在日常办公中,文件命名混乱的问题几乎困扰过所有人。项目文档版本混杂、会议记录...

发布日期: 2025-06-01 16:36:01
企业日常运营中常面临文档散乱、版本混乱的痛点,某科技团队基于Flask框架开发的本...

发布日期: 2025-05-23 16:39:31
在敏捷开发成为主流的当下,API文档与实现代码的同步率直接影响着项目推进效率。某...

发布日期: 2025-05-19 19:20:25
数字化办公场景中,PDF与DOCX格式文件的管理效率直接影响工作质量。专业文档处理工具...

发布日期: 2025-05-09 16:53:04
在日常的数据处理、文档编写或技术博客创作中,CSV文件和Markdown表格是两类高频使用...
发布日期: 2025-06-04 11:12:01
在数字化办公场景中,PDF文档的跨设备管理与及时同步成为高频需求。针对这一痛点,...

发布日期: 2025-04-17 16:21:47
纸质文档的电子化需求从未消退。从合同档案到学术论文,大量信息仍以实体形式存在...

发布日期: 2025-06-10 18:30:02
现代办公场景中,各类文档格式的兼容性问题时常困扰着职场人士。当市场调研报告需...
发布日期: 2025-05-03 09:12:01
在日常办公场景中,文档格式的兼容性问题长期困扰着团队协作。从PDF到Word、Excel到...

发布日期: 2025-05-01 17:39:22
在数字化办公场景中,敏感信息泄露的风险始终存在。某金融科技公司曾因员工误将包...

发布日期: 2025-04-10 17:59:44
职场人对周报的态度向来微妙——既无法摆脱,又难掩抵触。重复性的文档整理、格式...

发布日期: 2025-04-02 15:25:06
纸质文件电子化进程中,PDF格式以其跨平台稳定性成为办公场景的标配。面对堆积如山...

发布日期: 2025-04-26 10:00:02
日常办公场景中,常会遇到需要批量修改多个Word文档的情况。传统手工操作需要逐页查...

发布日期: 2025-04-05 10:14:47
在信息处理效率至上的数字化环境中,企业常面临大量重复性文档的编写需求。传统的...

发布日期: 2025-05-14 12:13:43
在日常办公场景中,PDF文档的空白页问题常困扰着许多职场人士。某位财务人员在合并...

发布日期: 2025-05-31 09:42:02
密码生成器命令行工具在开发者社区正掀起使用热潮。这款支持多平台的开源工具通过...

发布日期: 2025-05-22 13:11:19
智能文档分类系统正逐步改变传统文件管理模式。这种工具通过核心算法自动识别文本...

发布日期: 2025-05-12 14:13:47
在跨国团队合作的法律协议修订现场,法务总监Emily正面对三十余份不同版本的DOCX文档...

发布日期: 2025-03-25 16:35:16
PDF文档作为现代办公场景中的高频使用格式,日常处理常会遇到拆分与合并的需求。基...

发布日期: 2025-04-29 19:47:06
在日常办公场景中,Word文档的批量处理需求频繁出现。无论是批量替换文本、调整格式...

发布日期: 2025-05-01 17:25:02
在代码编辑器的黑色窗口里敲击指令,看着.md文件瞬间蜕变成.html页面——这种极客范...

发布日期: 2025-03-29 12:20:21
现代办公场景中,文档处理效率直接影响工作进度。面对成堆的PDF技术报告、DOCX合同文...

发布日期: 2025-06-13 13:00:02
在数字化办公场景中,RTF(Rich Text Format)文档因其跨平台兼容性被广泛使用。不同系统...

发布日期: 2025-05-27 18:44:35
Office文档转PDF版本检测器:解决格式兼容性难题的实用工具 在日常办公场景中,将Wo...

发布日期: 2025-03-31 10:01:17
在数字化办公场景中,文档格式混乱、排版效率低下成为高频痛点。手动调整字体间距...

发布日期: 2025-03-25 09:04:43
日常工作中,大量堆积的Word文档与PPT文件常让人头疼。手动逐页复制、粘贴不仅耗时,...

发布日期: 2025-05-02 12:23:26
纸质文件堆积如山的场景早已成为历史,但数字文档的爆炸式增长带来了新困扰。某科...

发布日期: 2025-05-09 12:07:01
随着电子文档成为主流办公载体,PDF文件承载的隐私泄露风险日益凸显。身份证号码、...

发布日期: 2025-06-13 11:18:02
日常办公中,文档体积过大常带来诸多困扰:邮件附件发送失败、云端存储空间告急、...

发布日期: 2025-04-11 17:42:01
在数字化办公场景中,文档格式转换已成为高频需求。面对PDF、TXT、CSV等不同格式文件...
发布日期: 2025-05-13 19:01:47
日常办公中,重复性文档操作消耗着大量工作时间。某跨国企业市场部的统计显示,员...

发布日期: 2025-04-12 16:00:02
对于常和文档打交道的人来说,PPT制作像场持久战。模板格式反复调整、文本框对齐逼...

发布日期: 2025-04-20 13:29:15
创作者在知乎专栏积累了大量深度文章后,常常面临内容备份的困扰。网页端逐篇复制...

发布日期: 2025-03-28 09:33:44
在软件开发过程中,需求文档的频繁变更是团队面临的常态。据统计,约70%的项目延期...

发布日期: 2025-05-11 16:31:50
在数字化办公场景中,文档处理效率直接影响企业运营节奏。传统模式下,合同、通知...

发布日期: 2025-06-02 18:27:01
PDF文档在办公场景中的高频使用催生出大量实用工具。一款集合并、拆分、旋转功能于...

发布日期: 2025-04-15 11:03:02
纸质文献堆叠的书桌上,咖啡杯边缘残留着深褐色的渍迹。屏幕前的青年学者反复调整...

发布日期: 2025-05-20 10:05:38
清晨八点的阳光斜照在显示器边缘,程序员张明习惯性将咖啡杯旁的便利贴揉成纸团—...

发布日期: 2025-04-13 12:53:31
在企业协作与文档管理场景中,版本混乱始终是高频痛点。同一份合同历经十余次修订...

发布日期: 2025-03-31 17:58:59
在数字化办公场景中,文件管理效率直接影响工作质量。面对海量文档、邮件、表格与...

发布日期: 2025-05-25 19:18:29
在技术文档维护领域,某互联网公司的研发团队曾因文档格式转换问题导致版本更新延...

发布日期: 2025-03-24 12:28:01
在数据可视化领域,每周有超过60%的从业者需要重复处理表格格式转换。传统手工复制...

发布日期: 2025-05-22 12:20:25
如果你常与文字打交道,对「左边敲代码,右边看效果」的写作模式一定不陌生。近年...

发布日期: 2025-03-27 09:47:07
在信息爆炸的数字化时代,企业对文档内容安全的需求日益迫切。无论是内部文件审核...

发布日期: 2025-05-06 11:02:17
PDF文档因其稳定性与跨平台特性,成为办公场景的常用格式。面对动辄数百页的行业报...

发布日期: 2025-05-03 10:00:01
在全球化软件项目的推进过程中,技术文档的本地化效率直接影响产品落地速度。基于...
发布日期: 2025-04-24 13:10:46
科研工作者在提交论文前,往往需要通过查重系统检测文本原创性。多数查重报告仅以...

发布日期: 2025-05-05 18:14:24
在日常的文档编辑或代码开发中,Markdown因其简洁的语法和易读性被广泛使用。当需要...
发布日期: 2025-05-16 17:53:53
在信息爆炸的时代,阅读效率与场景适配成为刚需。当程序员盯着满屏的代码注释、产...

发布日期: 2025-03-26 17:57:38
在数字化办公场景中,PDF与Word文档的格式转换需求日益频繁。无论是合同修订、论文编...

发布日期: 2025-04-04 09:34:48
对于常使用Markdown格式的创作者和开发者而言,文档版权保护与信息溯源需求日益增加...
发布日期: 2025-05-04 14:18:56
电子文档传输过程中,文件内容突然变成乱码,几乎是每个职场人或学生都曾遭遇的困...
发布日期: 2025-05-23 09:23:41
在数字化办公场景中,敏感信息泄露已成为企业、机构及个人用户的核心风险。合同、...
发布日期: 2025-06-03 10:06:01
在数字文档处理场景中,快速获取文本基础参数是高频需求。针对行数与字数的精准统...

发布日期: 2025-03-25 16:03:02
在软件开发领域,API文档的编写常被视为"必要之恶"。据行业调查显示,超过60%的开发...
")