
发布日期: 2025-04-13 13:00:40
压缩文件已成为数字生活中不可或缺的存储形式。面对各类ZIP格式文档,一款得心应手...
发布日期: 2025-05-08 11:04:01
数字化时代的信息爆炸让文本处理成为刚需。面对海量文档,如何快速识别内容关联性...

发布日期: 2025-04-12 17:33:28
汉字信息处理领域长期存在编码体系繁杂的痛点。为解决这一难题,某技术团队研发的...

发布日期: 2025-04-30 10:38:43
对于需要频繁处理图片素材的从业者而言,文件体积与画质间的平衡常成工作痛点。某...

发布日期: 2025-06-03 17:06:02
互联网每天新增200万篇博客内容,如何快速获取有效信息成为现代人的必修课。某款开...

发布日期: 2025-05-16 09:47:24
在医疗信息化快速发展的背景下,电子病历的标准化管理成为医院质控的关键环节。临...

发布日期: 2025-06-11 10:21:01
科研基金申报作为学术工作的重要环节,始终牵动着研究人员的精力。据《自然》杂志...

发布日期: 2025-04-15 14:09:54
运维监控领域正经历从被动响应到主动干预的转型期。某数据中心曾因突发的CPU占用激...
发布日期: 2025-06-07 15:18:02
在当今数据驱动的环境中,企业每天需处理海量表格数据,其中可能包含身份证号、手...

发布日期: 2025-04-22 13:30:32
打开任何电商平台,商品评价区都是真实用户反馈的聚集地。面对动辄上千条评价数据...

发布日期: 2025-03-30 11:08:56
现代生活中,每个人的数字账户里都存放着从社交记录到金融资产的各类敏感信息。当...

发布日期: 2025-04-16 14:26:27
在数字化生活深度渗透的当下,个人用户与企业常面临多平台账号管理的难题。重复输...

发布日期: 2025-04-14 18:29:30
随着微信公众号生态的复杂化,企业或自媒体团队常面临多账号内容管理难题:数据分...

发布日期: 2025-05-10 13:58:02
在软件交付周期持续压缩的今天,某互联网企业的测试团队曾因测试脚本执行异常导致...

发布日期: 2025-04-24 16:16:27
在信息系统中,日志数据如同数字世界的脉搏,记录着系统运行、用户行为及潜在异常...

发布日期: 2025-04-01 13:52:43
当数字绘画门槛日渐降低,一款轻量级绘图工具依然在设计师群体中保持着不可替代的...

发布日期: 2025-03-21 10:30:02
在信息爆炸的时代,从海量文本中快速提取关键内容已成为工作刚需。无论是科研人员...

发布日期: 2025-04-02 13:20:27
在数据密集型工作场景中,处理海量CSV文件时经常会遇到内容重复比对的需求。某科技...

发布日期: 2025-04-15 15:42:35
在信息爆炸的数字化时代,PDF文档因其稳定的格式特性,已成为职场办公与学术研究的...

发布日期: 2025-03-23 13:22:55
在中文文本处理领域,拼音注音标注是一项基础但繁琐的工作。无论是教材编写、语言...

发布日期: 2025-03-31 11:09:01
股市瞬息万变,价格波动往往在几分钟内决定盈亏。对于普通投资者而言,实时盯盘耗...

发布日期: 2025-05-12 15:47:16
办公室的灯光在深夜十一点依然明亮,财务主管李薇正在为季度报表做最后核对。当她...

发布日期: 2025-03-23 10:53:32
折腾过汇率换算的朋友都知道,浏览器查汇率总有广告弹窗干扰,手机APP又常要求注册...

发布日期: 2025-04-23 16:18:13
凌晨两点半的手机震动声,在床头柜上突兀响起。屏幕亮起的瞬间,蜷缩在被窝里的身...

发布日期: 2025-04-26 18:20:16
在数据中心或云平台中,系统服务的稳定性直接影响业务连续性。某次凌晨三点,某电...

发布日期: 2025-05-27 13:43:18
互联网传输文件的便捷性背后,暗藏着数据被篡改或损坏的风险。专业技术人员常通过...

发布日期: 2025-04-08 16:47:24
商品价格波动如同潮汐般难以捉摸,但一双数字化的"眼睛"正在改变这种混沌状态。当...

发布日期: 2025-04-07 13:58:02
在信息爆炸的社交媒体时代,微博作为国内重要的舆论场与流量池,其用户粉丝数据逐...

发布日期: 2025-05-25 10:26:17
在商品流通、仓储管理、资产盘点等领域,条码技术早已成为现代企业运转的基石。传...
发布日期: 2025-05-23 10:57:36
现代信息系统运行时产生的日志数据量常呈指数级增长。某中型电商平台单日日志量可...
发布日期: 2025-05-18 19:51:16
金融从业者常面临外汇数据处理难题——如何在庞杂信息中快速提取有效内容?一款专...

发布日期: 2025-05-24 11:25:16
在数字艺术领域,图像风格迁移技术正掀起一场静默的革命。通过深度学习算法,用户...

发布日期: 2025-04-01 16:47:11
在全球化的场景下,跨语言交流的需求日益增长,尤其是涉及地理信息、旅行导航或商...

发布日期: 2025-03-23 11:38:51
点击桌面右下角的时间显示区域,一个极简的悬浮窗跃然而出。这是TodoMaster区别于其他...

发布日期: 2025-03-22 12:42:26
互联网时代,网站宕机一分钟可能导致数千用户流失。某在线支付平台曾因服务器波动...

发布日期: 2025-03-22 10:40:49
在阳台上种死第三盆薄荷后,老张终于意识到种花种草不能只靠"感觉"。浇水是否过量...

发布日期: 2025-04-26 13:45:01
现代软件开发中,跨时区时间处理是绕不开的挑战。无论是全球化系统日志对齐,还是...

发布日期: 2025-04-13 12:42:31
泛黄的老照片承载着几代人的情感记忆,却在时光侵蚀下面临褪色模糊的困境。某科技...

发布日期: 2025-04-04 14:49:02
互联网信息存储场景中,压缩文件承担着海量文本数据的传输与保存任务。传统检索方...

发布日期: 2025-04-25 10:49:09
在社交媒体运营日益常态化的今天,及时获取账号动态更新信息直接影响着用户互动效...

发布日期: 2025-06-14 15:24:02
在数据录入员每天重复点击上千次鼠标的企业财务部,在电商运营人员熬夜处理促销活...

发布日期: 2025-04-22 09:03:26
面对不同场景的证件照需求,用户常需反复调整尺寸、背景或格式。传统修图软件操作...

发布日期: 2025-03-29 11:55:26
当你在浏览外文资料时,是否经历过频繁切换翻译软件的烦躁?跨国视频会议中面对实...

发布日期: 2025-05-09 16:56:40
在信息爆炸的数字化场景中,海量文本检索需求催生了专业工具的进化。基于正则表达...

发布日期: 2025-05-30 14:06:02
在信息爆炸的社交媒体时代,品牌运营、舆情监控或个人用户的内容存档需求持续增长...
发布日期: 2025-05-07 18:53:42
现代数字环境中,文件比对需求呈爆发式增长。专业工程师每天需要处理超过200次文件...

发布日期: 2025-06-10 16:36:01
在数据处理与系统开发领域,JSON格式的日志文件常因结构复杂、层级嵌套多而出现语法...

发布日期: 2025-04-29 17:26:56
夏日的阳光斜照进咖啡厅,笔记本屏幕突然变成一面反光镜;深夜关灯刷手机,屏幕亮...
发布日期: 2025-04-24 10:33:25
深夜鏖战网游时突然卡成PPT,视频会议中对方画面定格成表情包,这些场景背后都指向...

发布日期: 2025-04-24 15:15:29
在日常工作和数据传输中,大体积文件的传输与共享常令人头疼。网络环境不稳定、存...

发布日期: 2025-04-16 12:49:38
在复杂的企业网络环境中,策略配置冲突一直是运维团队的痛点。不同设备间的防火墙...

发布日期: 2025-03-28 18:16:37
互联网安全防护体系中,端口扫描检测如同一道隐形的防火墙。当攻击者尝试通过批量...

发布日期: 2025-05-13 12:09:40
日常办公场景中,PDF文件合并需求屡见不鲜。科研人员需要整合多篇文献报告,法务部...

发布日期: 2025-04-19 18:49:42
在物流行业高速发展的当下,快递单号查询跟踪工具已成为企业提升效率、优化用户体...
发布日期: 2025-06-09 15:48:01
系统自带的资源管理器常被低估。Windows任务管理器(Ctrl+Shift+Esc)的"性能"标签页藏着...
发布日期: 2025-06-07 17:30:03
按下开机键的瞬间,Linux系统的故事就开始了。当硬件自检的嘀嗒声响起,dmesg日志如同...
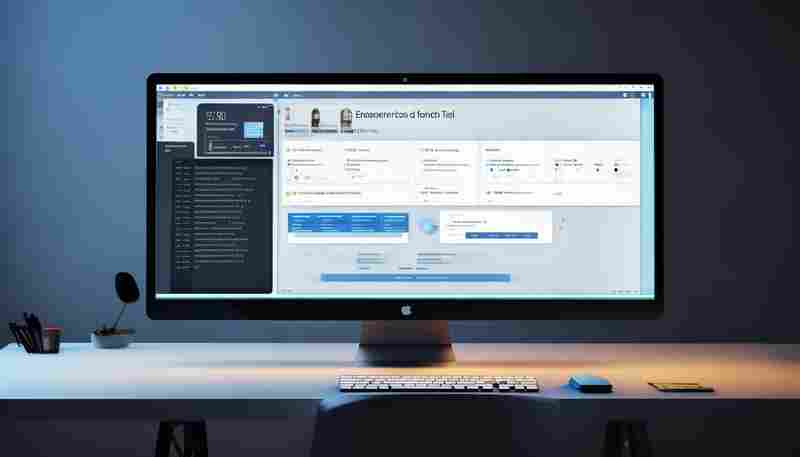
发布日期: 2025-05-20 15:47:24
在企业数字化管理中,通讯录作为组织架构的核心载体,承载着员工信息同步、权限分...
发布日期: 2025-06-10 16:00:02
输入"123456"时,屏幕突然弹出红色警告,动态热力图显示熵值仅18bit;当改成"Tr43@Cloud...

发布日期: 2025-06-06 11:48:01
全球化浪潮推动跨国协作成为常态,但语言差异始终是信息互通的最大障碍。传统翻译...

发布日期: 2025-04-12 10:03:01
在工业监控、智能家居等领域,实时掌握设备运行状态直接影响管理效率。虚拟房间...
