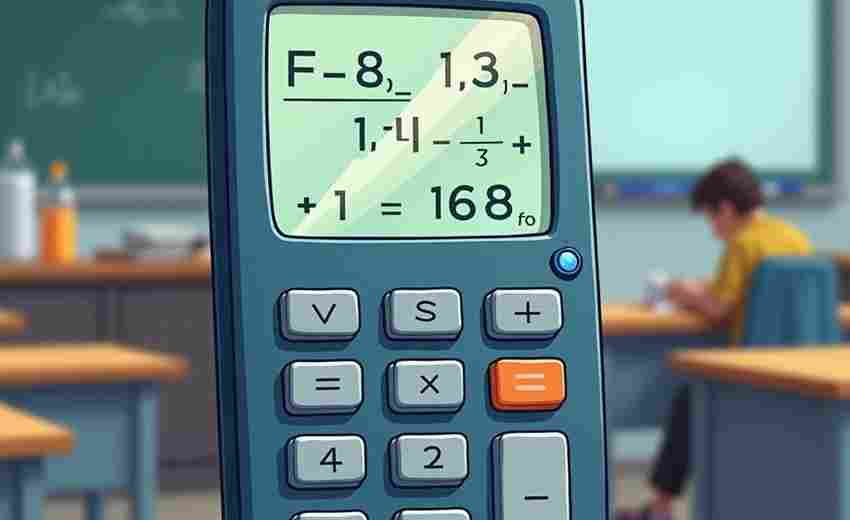Jupyter Notebook交互式编程环境
在数据科学实验室的玻璃墙上,总能看到研究者们面对着一本「会呼吸的电子笔记本」。这种支持代码、公式与可视化混排的界面,正在重塑人类探索数据的方式。作为交互式编程的标杆工具,Jupyter Notebook 让复杂的数据实验变得像在草稿纸上写方程式般自然。
一、思维可见化的革命
传统编程环境把代码与输出割裂在不同窗口,而 Jupyter 创造了独特的单元(Cell)系统。每个代码块如同实验台上的培养皿,允许研究者单独执行并立即看到图形化结果。这种即时反馈机制让调试过程变得可视化,错误不再是藏在黑暗中的谜题。
当在金融数据分析中处理百万级交易记录时,开发者可以边写清洗代码边观察数据分布图的变化。这种所见即所得的体验,使得处理缺失值、异常值的决策过程完全透明化,团队协作时每个成员都能清晰追溯数据处理逻辑。

教育领域最能体现这种优势。教师在演示机器学习算法时,能够逐行解释梯度下降的可视化过程,学生通过修改局部参数立即看到损失函数曲线的形态变化,抽象概念在交互中变得触手可及。
二、跨界融合的创作空间
Markdown 与 LaTeX 的无缝集成打破了技术文档的创作壁垒。数据科学家在编写随机森林算法时,可以直接在代码旁用数学符号推导基尼系数公式。这种技术叙事能力让论文撰写效率提升三倍以上,2018 年 NeurIPS 会议论文中有 42% 的复现代码直接托管在 Jupyter 文件中。
交互式控件库(ipywidgets)为静态报告注入生命力。流行病学研究者构建传播模型时,添加滑块控件实时调整基本传染数R0值,动态热力图即刻展现不同防控策略的效果差异。这种可操作的文档形式,正在取代传统PPT成为学术报告的新载体。
扩展生态系统的繁荣超出想象。从量子电路模拟器到蛋白质结构3D可视化,超过 580 个官方认证的扩展插件构成了庞大的工具矩阵。天文研究者甚至开发出星系演化模拟插件,直接在笔记本里操控宇宙时间轴。
三、云端协作的新范式
JupyterLab 模块化设计重新定义了开发环境。数据工程师可以在同一窗口并行打开数据看板、SQL查询界面和API测试工具,就像在真实实验室同时操作多个精密仪器。标签页系统支持同时监控模型训练日志和准确率曲线,工作效率产生质的飞跃。
版本控制与云存储的结合正在改变科研协作模式。Git集成功能让每个Cell的修改都有迹可循,配合JupyterHub的集群部署能力,跨国药企的研发团队能同步进行分子动力学模拟,实时合并每个人的计算成果。
内核隔离技术保障了多语言混编的安全性。在量化交易策略开发中,策略回测用Python编写,高性能计算部分调用Rust内核,风险控制模块则使用Julia实现,不同语言在独立沙箱中协同工作,既保证了执行效率又避免了环境冲突。
开源社区每周新增 150 个以上含Jupyter内核的工具包,从自动驾驶仿真到基因序列分析,这个始于2014年的大学项目已渗透到每个需要创造性探索的领域。当代码、文字与图像在单元格中自由流动,每个灵感火花都能被即刻验证,这或许就是数字时代研究者们最渴望的「思维加速器」。