
发布日期: 2025-03-24 10:42:39
现代人每天的通话记录就像一本未整理的日记——零散的通话时长、杂乱的联系人名单...

发布日期: 2025-03-30 10:22:39
数据统计是现代企业决策的重要依据,但固定周期统计常与实际业务脱节。例如,零售...

发布日期: 2025-03-23 12:33:42
传统教学管理中,教师常被各类电子表格淹没,面对海量成绩数据往往无从下手。某教...

发布日期: 2025-05-04 09:00:02
Excel作为企业级数据管理工具,在全球积累了超过十亿用户。面对海量业务数据的处理...
发布日期: 2025-05-11 10:41:00
在信息化办公环境中,个人计算机存储着数以万计的文档资料。某证券分析师曾因无法...

发布日期: 2025-04-21 11:13:53
在日常计算机管理中,隐藏文件常被用于存储敏感数据或系统配置信息。由于这类文件...

发布日期: 2025-04-06 09:17:50
日志文件作为系统运行、用户行为的重要记录载体,往往包含海量信息。如何快速提取...

发布日期: 2025-04-22 10:46:46
处理数据报表的财务小王最近遇到了麻烦:月末要汇总全国32个分公司的销售数据,每...

发布日期: 2025-04-24 19:07:39
在数字写作逐渐普及的当下,创作者对于内容管理的需求愈发精细。一款名为「NovelM...
发布日期: 2025-04-27 10:19:45
在数字工作场景中,操作行为的量化分析逐渐成为效率优化的突破口。鼠标点击频率统...

发布日期: 2025-04-20 09:07:45
日常处理代码或文本文件时,开发者常需快速掌握项目规模。某开源工具近期引发关注...

发布日期: 2025-03-29 18:51:46
在日常文件传输场景中,中文路径支持往往成为被忽视的技术痛点。某跨国设计团队在...

发布日期: 2025-03-29 18:30:23
日常工作中,键盘输入错误几乎无法避免。无论是打字速度过快导致的误触,还是对键...

发布日期: 2025-05-10 16:06:46
在科研与工业领域,数据采样与分析的质量直接影响结论的可靠性。如何确保样本能代...

发布日期: 2025-04-14 09:04:34
一款功能丰富的贪吃蛇游戏工具近期在开发者社区引发关注。这款基于Python开发的开源...
发布日期: 2025-03-30 09:43:23
在分布式系统架构中,接口响应时间如同人体脉搏般重要。某电商平台曾因0.3秒的响应...

发布日期: 2025-04-29 09:46:36
手机屏幕熄灭的瞬间,计时器开始无声跳动。这个隐藏在系统底层的统计工具,正悄然...

发布日期: 2025-04-07 18:47:34
面对硬盘中杂乱堆积的文件,手动统计存储占用如同大海捞针。传统资源管理器仅提供...

发布日期: 2025-03-25 10:05:04
在信息爆炸的社交媒体时代,内容发布时机的选择直接影响传播效果。一条优质内容若...
发布日期: 2025-05-01 18:32:42
在短视频内容井喷的时代,创作者常面临一个隐形挑战:如何精准把控作品时长与主题...

发布日期: 2025-05-11 17:14:53
在数据分析日益普及的今天,如何快速将海量数据转化为清晰易懂的统计报告,成为许...

发布日期: 2025-04-22 09:17:43
在学术写作领域,LaTeX用户常面临公式环境统计的痛点。当处理百页以上的技术文档时...
发布日期: 2025-04-01 19:59:33
在数据驱动的业务场景中,非结构化数据的处理效率直接影响决策质量。CSV作为轻量级...
发布日期: 2025-04-23 16:57:23
在数字内容爆炸式增长的今天,视频处理工具已成为多个行业的刚需设备。针对视频时...

发布日期: 2025-04-17 13:55:19
在数字内容爆炸式增长的当下,视频文件的管理成为许多从业者的痛点。无论是影视后...

发布日期: 2025-04-13 09:50:59
鼠标滚轮使用频率统计工具正逐渐成为效率研究领域的热门产品。这款工具通过后台进...
发布日期: 2025-03-31 17:05:17
教育场景中,成绩数据蕴藏着大量可挖掘的信息。传统人工统计难以发现学科间的潜在...

发布日期: 2025-03-21 10:32:26
日常工作中,程序员、数据分析师或学术研究者常面临文本关键词提取需求。针对这一...

发布日期: 2025-04-22 10:11:09
对于长期与Windows系统打交道的用户而言,"开机慢"始终是个挥之不去的痛点。当我们还...

发布日期: 2025-04-12 17:33:28
汉字信息处理领域长期存在编码体系繁杂的痛点。为解决这一难题,某技术团队研发的...

发布日期: 2025-03-25 15:31:00
在服务器集群昼夜不息的轰鸣声中,每天产生的日志数据如同潮水般奔涌。某次凌晨两...
发布日期: 2025-04-30 09:34:29
在信息爆炸的社交媒体时代,品牌方与内容创作者常面临一个核心问题:如何精准把握...

发布日期: 2025-04-02 11:58:43
现代工作场景中,时间管理能力直接影响个人效率与团队协作质量。用户活动时间统计...

发布日期: 2025-04-01 19:09:37
凌晨三点的机房警报突然响起,运维工程师张涛揉了揉通红的眼睛。服务器集群的日志...

发布日期: 2025-05-06 09:21:01
在数字影像时代,每张照片都像一本隐藏的日记。拍摄设备、时间参数、地理位置……...
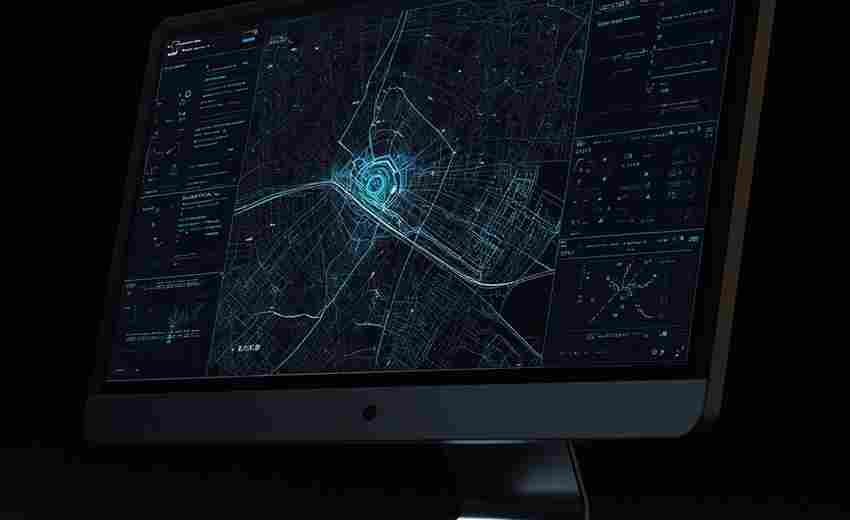
发布日期: 2025-03-23 10:06:48
当程序员在深夜调试代码时敲击键盘的节奏,或是文字工作者在灵感迸发时按键的轨迹...

发布日期: 2025-04-15 15:57:43
存储系统突然报警的红色标识在凌晨两点格外刺眼。运维工程师李明盯着监控屏幕上的...

发布日期: 2025-03-27 15:14:48
在屋顶光伏日渐普及的背景下,某技术爱好者社区近期流传着一套基于SQLite数据库的发...
发布日期: 2025-05-08 18:30:40
在软件研发与运维场景中,文件差异对比是高频刚需。传统可视化对比工具虽然直观,...

发布日期: 2025-03-26 14:05:15
客厅的智能空调突然跳闸,用户翻出上个月电费账单才意识到问题所在。类似场景在家...

发布日期: 2025-05-10 11:23:58
在信息爆炸的时代,从海量文本中快速提取核心信息的需求日益迫切。无论是学术研究...

发布日期: 2025-04-27 19:04:03
短视频创作者常为标题抓耳挠腮。一个吸睛的标题往往藏着流量密码,而破译密码的关...

发布日期: 2025-04-06 14:47:13
手机键盘输入统计热力图生成器是一款针对触屏设备开发的实用工具。它通过捕捉用户...
发布日期: 2025-04-26 12:12:19
一键生成数据统计报告:智能工具如何释放数据分析潜力 在数据驱动的决策环境中,快...

发布日期: 2025-05-12 13:48:38
在数据处理与分析领域,快速生成可视化图表的需求日益迫切。Excel作为办公场景中最...
发布日期: 2025-04-19 15:44:21
打开手机备忘录里密密麻麻的待办事项,很多人都有过类似的经历:写着「完成季度汇...

发布日期: 2025-04-11 09:00:02
互联网广告的屏蔽率正以每年12%的速度攀升。当用户借助插件过滤页面元素时,企业主...

发布日期: 2025-03-24 12:24:01
打开一篇长文档,如何快速抓住作者的核心观点?面对海量文本数据,怎样提炼出高频...
发布日期: 2025-05-11 10:19:36
纸质书时代,读者习惯用折角或书签记录阅读进度。当阅读媒介转向电子屏幕,数据追...

发布日期: 2025-04-28 11:53:28
在文本处理领域,中文转拼音的需求长期存在。无论是为生僻字标注读音、处理国际化...
发布日期: 2025-05-11 17:39:55
服务器监控面板突然弹出红色警报,凌晨两点三刻的运维值班室,工程师的咖啡杯停在...

发布日期: 2025-05-05 09:49:34
日志文件作为系统运行的重要记录载体,常隐藏着服务器状态、程序异常等关键信息。...

发布日期: 2025-04-06 16:42:02
在日常工作中,邮件沟通占据重要地位。但发件人往往面临两大困扰:对方是否及时查...

发布日期: 2025-04-07 19:44:43
当硬盘空间频繁告急,多数人习惯性打开资源管理器逐层翻找大文件。这种手动操作效...

发布日期: 2025-05-03 19:02:55
在数字化办公场景中,字体资源管理常被忽视。某企业IT部门曾发现,其办公系统安装...

发布日期: 2025-03-23 10:43:45
网络卡顿、视频会议掉线、文件传输中断……这些问题背后往往存在同一个隐形杀手—...

发布日期: 2025-03-25 11:30:46
教育工作者常面临成绩管理的多重挑战。传统的手工记录方式不仅耗费时间,数据核对...

发布日期: 2025-04-12 16:50:31
版本控制系统中的分支合并操作,往往像散落在仓库里的记忆碎片。当团队协作进入深...
发布日期: 2025-03-28 18:59:21
在数据处理与分析中,直方图是一种直观展示数据分布的图形工具。针对频繁需要快速...

发布日期: 2025-03-30 15:07:24
在日常工作与学习中,电子设备中堆积的文件常常让人陷入混乱。文档、图片、视频、...
")