
发布日期: 2025-04-08 14:53:27
工作汇报需要整合多张软件界面截图,电商运营需横向对比商品参数,自媒体创作者总...

发布日期: 2025-03-28 19:24:01
清晨阳光斜射进办公室的玻璃窗,程序员李明习惯性双击桌面上那个黄色图标——这是...

发布日期: 2025-04-16 15:27:27
现代数据存储环境中,跨设备、跨平台的文件管理需求日益复杂。某科技公司研发部门...

发布日期: 2025-04-01 15:28:51
手机振动提示电量不足时,用户常常发现重要的会议录音还停留在平板设备里;出差途...
发布日期: 2025-05-07 13:27:25
键盘在桌面上敲出清脆声响,光标随着命令行的输入不断闪烁。对于习惯终端操作的用...

发布日期: 2025-05-21 15:37:02
办公室的键盘声此起彼伏,小张盯着屏幕上的数据表,第7次双击鼠标试图调整单元格格...

发布日期: 2025-05-12 09:15:02
在服务器运维领域,文件权限管理如同数字世界的门禁系统。某次安全事件调查中,工...
发布日期: 2025-05-17 09:38:41
日常工作中常遇到Excel表格数据混乱的情况。手动调整费时费力,尤其当数据量达到数...

发布日期: 2025-03-22 10:28:01
数据清洗作为数据分析的基础环节,常因流程繁琐、人工干预多导致效率低下。某技术...

发布日期: 2025-04-23 19:52:13
(背景)运维过数据库的人都知道,慢查询日志就像系统体检报告单。面对动辄数GB的...

发布日期: 2025-05-21 16:41:19
在Python项目的开发过程中,安装包时的依赖冲突犹如房间里突然断电——你永远不知道...

发布日期: 2025-04-21 09:26:45
结构应力测试数据波动分析工具在工程监测领域正逐步成为不可或缺的技术手段。该工...

发布日期: 2025-04-28 19:41:26
企业级IT系统中,每天产生的日志数据如同潮水般涌现。运维人员需要从海量信息中快...

发布日期: 2025-04-05 09:49:39
每到新学期选课阶段,学生们总会面临一个难题:如何在有限的课程池中选择心仪的课...
发布日期: 2025-05-25 18:57:02
在Python生态中,Tkinter作为内置GUI开发库始终占据独特地位。近期一款基于Tkinter的图形...

发布日期: 2025-04-01 15:21:42
在数字化转型加速的当下,企业对于远程运维的需求持续增长。服务远程管理代理工具...

发布日期: 2025-05-23 15:26:46
暴雨突袭导致交通瘫痪,台风预警不及时让渔船遇险…近年来极端天气频发,如何快速...

发布日期: 2025-04-07 12:47:03
在纽约大都会博物馆的《溪山行旅图》展厅前,两个法国游客正用手机扫描展品旁的汉...

发布日期: 2025-04-16 17:15:21
办公族常遇到这样的场景:下载文件夹堆积着PDF、图片、压缩包等数百个文件,手动整...

发布日期: 2025-04-28 17:08:03
随着数字摄影的普及,照片背后的信息价值逐渐被挖掘。许多用户希望从海量照片中提...
发布日期: 2025-06-09 15:42:01
办公桌面上总少不了一款趁手的笔记工具。对于追求效率的用户而言,过于臃肿的笔记...

发布日期: 2025-04-05 18:11:59
电子书爱好者常会遇到EPUB文件突然无法打开的窘境。当精心收集的电子书变成乱码或直...

发布日期: 2025-04-10 15:10:52
在代码协作中,Git仓库的变更记录如同团队的"数字记忆库",但面对海量的提交日志和...

发布日期: 2025-04-20 09:51:39
互联网每天产生数亿条社交媒体内容,如何从中快速获取用户真实情感反馈成为企业及...

发布日期: 2025-04-14 19:32:17
在数字图像处理领域,高效管理大量视觉素材的需求持续增长。两款互补型工具——全...

发布日期: 2025-03-21 09:27:02
在互联网上搜索电影资源时,用户常会遇到链接失效、画质模糊、甚至误触版权风险等...

发布日期: 2025-04-04 19:48:02
日常工作中整理数百张会议照片时,总会出现"IMG_20230601_001(1)(备份).jpg"这类混乱文件名...

发布日期: 2025-05-03 15:46:40
互联网信息每秒都在更新,但人工盯梢网页变化如同大海捞针。面对动态网页、新闻资...
发布日期: 2025-06-03 12:24:01
桌面端文本编辑器领域长期被商业软件占据,最近用PyQt5配合QSyntaxHighlighter组件开发了...
发布日期: 2025-04-23 09:12:01
在信息爆炸的数字化时代,开发者、运维团队或文案编辑常面临同一类问题:如何在短...

发布日期: 2025-04-15 16:44:04
在分布式系统架构普及的今天,配置信息安全管理已成为企业技术团队的核心课题。某...

发布日期: 2025-05-02 13:06:34
日常办公场景中,经常需要处理来自不同系统的数据报表。某金融企业财务部门曾因手...

发布日期: 2025-05-24 19:58:43
碎片化记录生活已成日常,但如何将零散照片快速整理成有故事感的作品?简易照片拼...

发布日期: 2025-04-24 17:02:33
软件研发领域长期存在一项基础但繁琐的任务:处理多语言JSON文件中的注释内容。这些...

发布日期: 2025-04-07 13:58:02
在信息爆炸的社交媒体时代,微博作为国内重要的舆论场与流量池,其用户粉丝数据逐...

发布日期: 2025-06-12 09:42:01
在日常数据处理场景中,Excel公式错误往往成为困扰用户的隐形障碍。从财务人员编制...
发布日期: 2025-04-08 19:13:34
工作场景中经常遇到这种情况:演示文档需要圈出数据重点,设计稿要标注修改意见,...

发布日期: 2025-04-06 17:42:45
清晨九点,某跨境电商公司的技术部已进入工作状态。运营组电脑屏幕上的二十余个店...

发布日期: 2025-04-21 18:25:48
在金融科技项目的接口测试环节,我们研发团队常面临批量生成测试用Token的难题。传...

发布日期: 2025-03-30 15:29:00
数据备份如同现代人的数字保险箱,但反复存储的冗余文件往往让硬盘空间不堪重负。...

发布日期: 2025-05-08 15:24:47
日常办公场景中,重要文件意外丢失或误删的情况时有发生。针对Windows及Linux系统的文...

发布日期: 2025-04-18 16:38:18
在快节奏的商业环境中,数据报表制作效率直接影响着企业决策速度。某科技公司市场...
发布日期: 2025-06-07 16:30:02
在移动互联网深度渗透的当下,地理定位技术已成为本地生活服务的核心引擎。一款集...
发布日期: 2025-04-04 12:08:56
在视频直播、在线会议成为日常的今天,实时摄像头滤镜工具逐渐从娱乐玩具演变为刚...

发布日期: 2025-05-12 11:49:45
在数字化办公场景中,文档格式错乱、文字错误、排版偏差等问题频繁困扰着文件处理...

发布日期: 2025-04-26 14:49:20
在日常工作场景中,文本文件的修改与协作极为常见。无论是程序员调试代码,还是编...

发布日期: 2025-04-04 11:08:24
互联网的隐私合规门槛逐年升高,从欧盟的《通用数据保护条例》(GDPR)到国内《个人...
发布日期: 2025-06-07 10:24:02
许多人在浏览网页时都遇到过需要批量保存图片的情况,无论是收集设计素材还是保存...

发布日期: 2025-06-09 11:00:01
互联网时代,热搜榜单如同社会情绪的晴雨表。每分钟更新的关键词背后,往往隐藏着...
发布日期: 2025-05-03 19:42:02
数据可视化是数据分析不可或缺的环节,而折线图因其直观展示趋势变化的特性,在各...

发布日期: 2025-06-07 11:36:02
许多用户都经历过这样的场景:C盘不知不觉飘红,资源管理器卡顿到无法响应,各类软...

发布日期: 2025-04-14 12:47:52
凌晨三点的机房警报声响起,运维工程师李明盯着监控面板上飙升的CPU曲线,发现某个...
发布日期: 2025-06-10 16:00:02
输入"123456"时,屏幕突然弹出红色警告,动态热力图显示熵值仅18bit;当改成"Tr43@Cloud...
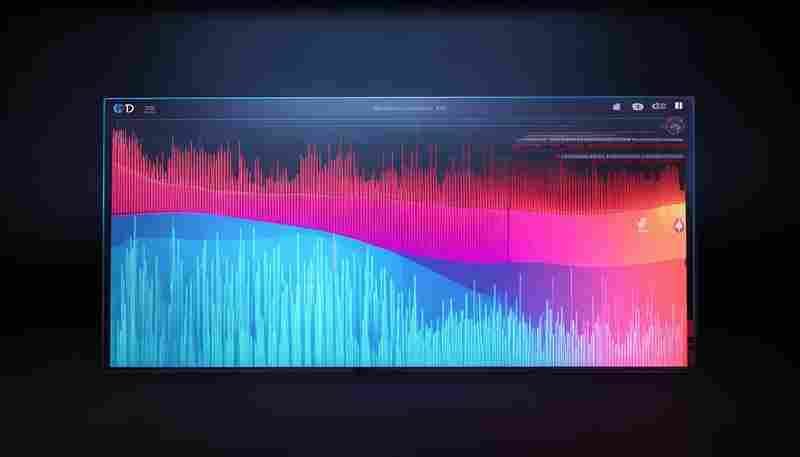
发布日期: 2025-05-07 09:17:04
在服务器运维与开发场景中,CPU使用率是衡量系统健康的核心指标。当资源占用异常时...

发布日期: 2025-04-20 10:02:09
深夜两点,某电商平台的数据库突然停止响应。运维团队排查发现,日志文件占满服务...

发布日期: 2025-05-26 15:48:40
在数字内容生产领域,视频文件的元数据管理正成为影响工作效率的重要环节。面对动...

发布日期: 2025-04-17 19:33:02
近年来,随着学术交流的国际化发展,中英文混合文本在论文、商业报告等场景中的使...

发布日期: 2025-04-06 18:54:01
数字时代下,一人多设备登录已成为常态。无论是个人用户在不同手机、电脑间切换,...
发布日期: 2025-04-04 17:43:24
在数据处理领域,重复信息的识别与分析常成为关键挑战。例如,在文本压缩、代码优...
发布日期: 2025-05-25 17:37:35
在商务合作项目中传输设计原稿时,技术人员常常会遇到邮件附件容量限制的困扰。某...
")