
发布日期: 2025-06-02 18:15:02
技术设备参数手册的英文缩写、德文版主板报错代码、日文驱动安装说明——全球化的...

发布日期: 2025-03-31 15:07:25
凌晨三点的办公室里,网络安全工程师李明正对着屏幕皱眉。某企业数据库刚遭受撞库...

发布日期: 2025-05-11 11:27:35
某个深夜的编程马拉松活动中,某位开发者盯着满屏代码突然笑出声——他的终端窗口...

发布日期: 2025-04-05 14:24:01
深秋午后,窗边摆着半盏冷茶,宣纸上的墨迹未干。这种场景常令诗词爱好者生出创作...
发布日期: 2025-04-26 19:13:38
在日常系统运维中,开发人员经常通过命令行参数启动进程。某个金融系统的Java应用曾...

发布日期: 2025-05-13 11:51:46
在数字技术与传统文化碰撞的浪潮中,中文诗歌随机生成器悄然成为文学爱好者的新宠...
发布日期: 2025-04-29 11:19:18
互联网服务监控领域长期存在一个痛点:当接口请求量激增时,开发人员往往需要耗费...

发布日期: 2025-03-22 10:25:09
数据加密领域近期出现了一款名为"CipherMatrix"的开源工具,其核心功能在于通过随机密...

发布日期: 2025-06-10 13:24:02
随着疫情防控常态化,核酸混检、抗原自测等场景对检测流程的规范性和公平性提出更...

发布日期: 2025-05-29 19:12:01
命令行随机密码生成工具使用指南 在网络安全意识逐渐增强的今天,高强度密码已成为...
发布日期: 2025-05-17 13:35:35
在数字化办公成为主流的今天,打字速度直接影响着工作效率。一款轻量化的打字速度...

发布日期: 2025-05-20 13:55:45
每个电脑用户都经历过这样的场景:深夜赶工时被突如其来的视频广告音量惊吓,视频...

发布日期: 2025-05-05 13:13:10
在工业制造、交通运输或开放式办公场景中,环境噪音的不可控性长期困扰着生产效率...

发布日期: 2025-04-29 17:26:56
夏日的阳光斜照进咖啡厅,笔记本屏幕突然变成一面反光镜;深夜关灯刷手机,屏幕亮...
发布日期: 2025-05-12 16:37:54
在数字化生活占据主导的当下,个人账户数量呈指数级增长。从社交平台到金融软件,...
发布日期: 2025-04-07 11:25:09
在图形化界面占据主流的时代,命令行工具因其高效与灵活性仍被开发者推崇。基于命...
发布日期: 2025-05-16 13:26:21
在数字账号频繁遭受攻击的当下,密码如同守护个人隐私的第一道大门。"123456"或"pas...
发布日期: 2025-06-13 19:36:02
在社交媒体传播中,GIF动图因其体积小、易加载的特性成为主流内容形式。针对视频转...

发布日期: 2025-03-28 13:28:42
在数字艺术领域,一种以几何算法为核心的随机艺术图案生成工具正悄然改变创作方式...

发布日期: 2025-04-10 13:56:02
网络安全领域近期出现了一款名为CycloPass的密码管理工具,其独特的动态密码机制在金...

发布日期: 2025-03-29 13:03:01
清晨八点按下开机键,小王盯着屏幕上用了半年的默认壁纸叹了口气。行政岗同事的电...

发布日期: 2025-06-05 13:48:02
昏暗的网吧里,老张盯着屏幕上的装甲车参数表,第三次摘下眼镜揉搓发酸的眼角。这...

发布日期: 2025-04-22 13:51:53
在Python GUI开发领域,Tkinter作为标准库组件长期占据重要地位。近期开源社区涌现出一...

发布日期: 2025-04-08 12:12:03
打开电脑自带画图软件时,常被其简陋界面劝退的专业用户,或是需要快速记录灵感的...

发布日期: 2025-05-10 16:06:46
在科研与工业领域,数据采样与分析的质量直接影响结论的可靠性。如何确保样本能代...

发布日期: 2025-05-23 16:14:30
在像素游戏复兴的浪潮中,贪吃蛇这个诞生于1976年的经典玩法正以全新姿态回归。某款...

发布日期: 2025-06-06 10:30:01
数据安全领域近年频发的密码泄露事件不断敲响警钟。2023年某跨国企业因员工使用"1...

发布日期: 2025-04-24 14:47:13
传统试卷制作流程中,教师常需耗费数小时筛选题目、调整难度、排版格式。某款基于...

发布日期: 2025-04-21 17:39:20
在短视频盛行的时代,将精彩片段转换为GIF动图已成为内容创作者的刚需。近期测试的...
发布日期: 2025-06-17 17:42:02
在数字图像处理教学领域,传统边缘检测算法演示往往依赖静态参数设置与结果展示,...
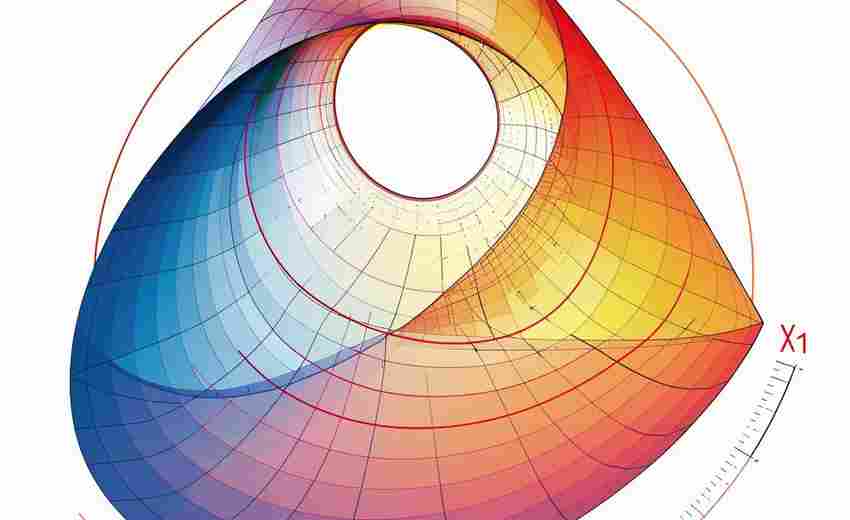
发布日期: 2025-04-01 12:40:31
在数学教学和科研领域,可视化工具始终是理解抽象概念的重要桥梁。某款支持动态参...

发布日期: 2025-04-26 11:18:23
在网络安全攻防体系中,密码字典扮演着关键角色。无论是企业渗透测试还是个人账户...

发布日期: 2025-03-29 15:46:45
全球数字经济加速发展,虚拟号码验证需求呈现爆发增长。根据第三方测试机构2023年的...

发布日期: 2025-04-30 09:56:01
输入姓名时习惯性敲下"张三",测试电话号码总用"",邮箱反复填写""……这些场景对开...

发布日期: 2025-05-01 19:15:40
像素艺术近年来在独立游戏、数字插画领域焕发新生。一款支持自定义画布尺寸的随机...

发布日期: 2025-06-21 10:18:03
密码安全在数字时代的重要性不言而喻。根据Verizon《数据泄露调查报告》,80%的网络攻...

发布日期: 2025-05-04 10:30:02
在数据中心运维领域,配置偏差引发的系统故障占比高达37%。某金融企业曾因TCP连接数...
发布日期: 2025-04-19 10:13:10
在软件开发和数据测试领域,生成符合业务场景的测试数据集是验证系统稳定性的关键...

发布日期: 2025-04-02 17:08:35
在数字技术蓬勃发展的今天,算法与人文的跨界融合催生出许多创新工具。中文诗词随...

发布日期: 2025-05-12 15:50:41
在数字音频处理领域,一款名为"ChaoticMix"的智能工具正引发创作者关注。这款基于深度...

发布日期: 2025-05-25 10:44:23
在数字化生活逐渐渗透的当下,密码管理已成为多数人绕不开的痛点。重复使用简单口...
发布日期: 2025-05-04 17:38:42
在数字身份频繁遭遇泄露的今天,密码安全正成为普通用户与技术团队共同关注的焦点...

发布日期: 2025-04-08 18:16:29
在信息爆炸的时代,人们对于碎片化内容的获取需求催生出各类创意工具。随机名言显...

发布日期: 2025-06-05 09:54:02
在互联网渗透生活的今天,密码安全已成为不可忽视的议题。统计数据显示,全球每分...

发布日期: 2025-04-13 10:58:45
互联网时代,每个账户都需要独立密码已是共识,但「生日+手机尾号」的固定组合仍在...

发布日期: 2025-05-17 11:08:07
互联网时代,密码如同家门钥匙。据Verizon数据泄露报告显示,80%以上的网络攻击与密码...

发布日期: 2025-03-31 19:37:03
深夜追剧时突然需要调低音量,游戏激战正酣时想快速关闭声音,视频会议中频繁调整...
发布日期: 2025-06-13 10:36:01
现代网络安全的核心防线往往始于一串字符。随着数据泄露事件频发,用户对密码强度...

发布日期: 2025-04-09 19:19:49
在数字音频处理领域,效率与灵活性一直是刚需。一款支持高度自定义参数的音频转换...

发布日期: 2025-05-22 09:08:34
深夜追剧怕吵醒家人,在线会议突然弹出广告音,游戏激战需要环境声效配合…这些场...

发布日期: 2025-03-27 12:41:42
在Windows系统中调节屏幕亮度通常依赖硬件按键或图形化设置面板,但对于开发者和运维...

发布日期: 2025-04-27 15:48:01
调试Python脚本参数时,开发者常陷入这样的困境:反复修改数值却忘记版本记录,多人...

发布日期: 2025-04-08 13:09:17
在数字身份频繁遭遇泄露的今天,传统密码设置习惯已暴露致命缺陷。根据Verizon《20...
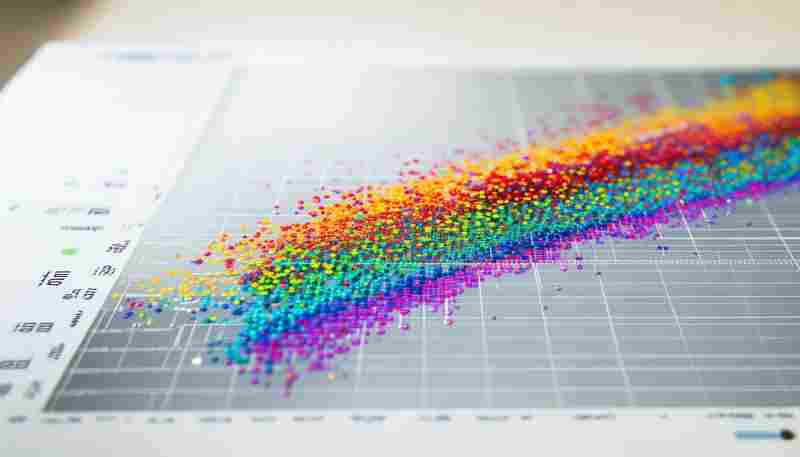
发布日期: 2025-05-09 18:37:38
NumPy作为Python生态中科学计算的核心工具库,其随机数模块在数据处理、仿真模拟等领...

发布日期: 2025-05-20 14:20:59
互联网安全领域对验证码技术的需求正经历迭代升级。传统字符型验证码因易被OCR技术...

发布日期: 2025-04-13 11:56:17
在跨境支付、企业财务对账等场景中,交易备注信息的规范性直接影响着后续数据处理...

发布日期: 2025-03-22 11:26:58
市面上各类打字速度测试软件层出不穷,但真正能帮助用户提升盲打能力的工具并不多...

发布日期: 2025-04-09 12:21:24
在快节奏的现代生活中,许多人渴望通过文字寻找片刻的宁静或灵感,却常因创作门槛...

发布日期: 2025-04-07 13:08:24
现代人手机里存着78个需要记忆的密码,这个数字还在以每年12%的速度增长。当某银行...

发布日期: 2025-04-22 18:58:05
在数字化浪潮席卷全球的今天,网络安全已成为不可忽视的议题。当用户注册账号、提...
