
发布日期: 2025-05-01 11:52:58
在编程语言实现领域,词法分析器的开发效率直接影响着编译器的构建进度。LexicalAn...

发布日期: 2025-05-22 12:49:48
清晨七点的手机震动唤醒的不只是闹钟,还有日历应用自动推送的会议备忘。通勤路上...

发布日期: 2025-05-04 09:43:44
Tkinter作为Python标准GUI工具包,凭借其轻量化特点成为快速开发桌面应用的首选。这款基...
发布日期: 2025-05-17 13:53:17
工作台前的显示器微微发烫,文件夹里躺着三千张待处理的商品图。电商部门的同事发...

发布日期: 2025-05-11 19:13:06
在网络安全防护体系中,验证码技术始终扮演着守门人的角色。某开发者社区近期开源...

发布日期: 2025-04-17 16:35:51
工作日的早晨总是兵荒马乱。很多人习惯用手机记事本罗列当日任务,但往往写着写着...

发布日期: 2025-06-08 16:24:01
日常运维中经常遇到数百兆的日志文件需要分析,手动翻阅如同大海捞针。某开源社区...

发布日期: 2025-06-08 09:12:01
互联网数据抓取领域存在多种技术方案,本文将从实际应用角度剖析不同工具的特点。...

发布日期: 2025-04-13 14:08:48
在个人博客搭建领域,开发者常面临功能冗余与维护成本的矛盾。一款基于Flask框架开...

发布日期: 2025-05-11 17:50:43
俄罗斯方块作为风靡全球的益智游戏,其核心玩法经久不衰。如今,许多开发者通过现...

发布日期: 2025-05-06 19:01:06
现代营销场景中,长链接的传播困境始终存在——社交媒体字符限制、印刷物料空间局...

发布日期: 2025-05-11 14:01:34
数据驱动决策的今天,天气数据已成为农业种植、物流运输、旅游规划等领域的关键参...

发布日期: 2025-04-04 12:48:01
在代码托管平台普及的今天,工程师们早已习惯用Git管理文本文件。但面对设计稿、视...

发布日期: 2025-04-29 16:18:59
在数字化办公逐渐普及的当下,网页截图成为许多人日常工作的高频需求。当设计师需...

发布日期: 2025-03-21 13:53:30
在终端场景下处理二维码往往令人头疼——切换图形界面工具打断工作流、依赖第三方...

发布日期: 2025-03-21 11:11:30
互联网图片资源呈爆发式增长,如何高效处理海量图片成为开发者面临的实际问题。一...

发布日期: 2025-03-25 17:25:02
对于股票投资者而言,实时掌握价格波动是决策的关键。一款功能直观、数据精准的股...

发布日期: 2025-04-10 15:03:44
在信息过载的数字化时代,电子邮件依然是职场沟通和个人事务的重要工具。一款高效...

发布日期: 2025-05-29 14:18:01
当一款标价699元的蓝牙耳机在京东悄然降至599元时,某品牌的市场总监在凌晨三点收到...
发布日期: 2025-05-21 13:31:29
现代生活的待办事项多如牛毛,如何高效管理并分清轻重缓急,成了许多人头疼的问题...

发布日期: 2025-03-26 15:44:56
凌晨三点的机房监控屏突然闪烁红光,某电商平台运维人员发现数据库出现异常锁表现...
发布日期: 2025-05-19 10:43:39
互联网数据量呈指数级增长,企业对于精准数据的需求催生出各类网页抓取工具。其中...

发布日期: 2025-06-07 10:18:01
数据采集领域正经历着革命性转变。当某电商运营团队仅用鼠标拖拽就完成竞品价格监...
发布日期: 2025-05-18 10:42:38
电脑屏幕上密密麻麻的数据表格中,有个关键单元格需要特别标注。行政专员小林熟练...

发布日期: 2025-04-23 14:49:01
在项目管理和技术开发领域,流程图的高效绘制直接影响信息传递的精准度。一款轻量...

发布日期: 2025-04-01 16:11:30
对于经常需要调整系统设置的技术人员而言,直接操作注册表总伴随着风险。某款体积...

发布日期: 2025-04-20 12:50:00
清晨七点的地铁车厢里,指尖在磨砂金属表面划过,实体按键的触感透过指腹传来。这...

发布日期: 2025-05-08 10:35:10
清晨七点的阳光刚透进窗户,办公桌上的电脑突然自动启动。咖啡机运作的间隙,设计...
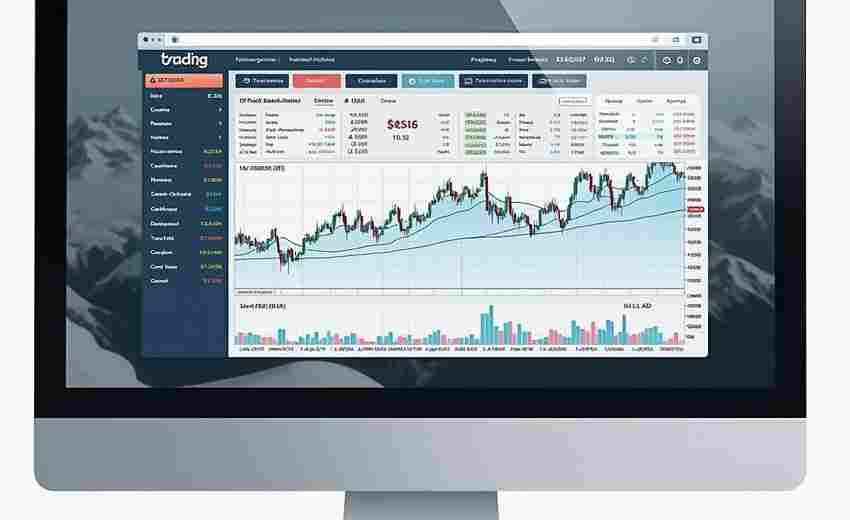
发布日期: 2025-03-30 16:33:01
电脑屏幕频繁切换股票页面的困扰,大多数股民都经历过。随着盯盘工具不断迭代,多...
发布日期: 2025-05-18 09:24:01
清晨推开办公室大门,许多人的第一件事不是泡咖啡,而是对着屏幕列下当天任务清单...
发布日期: 2025-05-09 13:36:22
数据采集领域长期存在一个痛点:爬虫抓取的海量信息如何快速整理成可读、可分析的...

发布日期: 2025-04-12 16:03:43
现代人的电子设备常被各类任务挤占。视频会议需要同步记录要点,网课教程得配合实...

发布日期: 2025-04-16 09:57:55
在局域网管理与网络安全维护领域,掌握网络流量可视化技术已成为IT从业者的必备技...

发布日期: 2025-05-25 15:42:29
在互联网内容生态中,无效链接(死链)如同隐藏的陷阱,不仅影响用户体验,还会对...
发布日期: 2025-05-12 11:10:08
在数字化协作场景中,即时通讯工具已成为日常沟通的重要载体。一款支持消息历史存...

发布日期: 2025-04-07 19:19:43
在程序开发与系统运维的日常工作中,性能监控如同医生的听诊器。一款名为PerfMon的轻...
发布日期: 2025-06-09 13:00:02
网络论坛沉淀着大量用户生成内容,从产品反馈到行业讨论都具备研究价值。手动复制...

发布日期: 2025-03-24 11:55:22
窗外的梧桐叶随风晃动,电脑屏幕前的手指正握着鼠标在画布上勾线。这个仅占用8MB内...

发布日期: 2025-06-01 12:30:01
建筑制图行业流传着一句老话:"图纸就是工程师的语言"。面对纷繁复杂的CAD图纸格式...

发布日期: 2025-03-27 10:15:32
在信息处理场景中,快速定位文本关键词的需求日益普遍。无论是学术文献的精读、法...
发布日期: 2025-04-17 13:30:00
在Web开发领域,实时通信功能的应用场景日益广泛。本文将介绍如何利用Python的Flask框...

发布日期: 2025-04-19 10:16:44
清晨七点,闹钟第三次响起时,手机屏幕自动亮起备忘录:"重要会议资料需在九点前发...
发布日期: 2025-05-26 12:19:43
数独作为经典的逻辑游戏,其数字排列的数学规律与规则设计值得深入探讨。本文将以...

发布日期: 2025-04-01 18:48:03
局域网文件传输是日常工作中频繁发生的需求,当U盘拷贝或即时通讯工具传输无法满足...
发布日期: 2025-04-25 09:20:06
数据可视化的门槛正被一款名为"ChartFlow"的工具打破。这款基于CSV格式的轻量级工具,...
发布日期: 2025-05-07 10:35:34
对于习惯用Markdown写作的用户来说,一款简洁高效的本地编辑器往往比在线工具更实用...

发布日期: 2025-04-04 11:15:30
网络管理员和安全研究人员常常需要快速掌握目标主机的端口开放情况。基于命令行的...

发布日期: 2025-05-02 15:47:08
手机屏幕亮起,指尖轻点几下,复杂的积分方程瞬间得出结果;输入一串数字,英镑自...

发布日期: 2025-03-28 13:50:15
在软件授权管理与产品商业化进程中,注册码生成器扮演着关键角色。本文聚焦一款操...

发布日期: 2025-04-11 12:34:16
在软件测试领域,传统静态测试用例的设计往往依赖人工经验,难以覆盖复杂系统的潜...

发布日期: 2025-04-04 10:21:02
许多团队在组织活动时都面临过投票效率低下的困扰。纸质表格统计耗时长,微信群接...

发布日期: 2025-05-22 10:50:27
在Python生态中,Requests库如同开发者的"网络瑞士军刀"。这个简洁优雅的HTTP客户端库,...

发布日期: 2025-06-08 09:18:01
在信息爆炸的互联网时代,快速获取目标数据成为企业和研究者的刚需。静态网页作为...

发布日期: 2025-04-17 14:18:31
在分布式系统开发领域,Socket通信技术始终占据基础地位。本文解析如何利用Socket实现...

发布日期: 2025-04-13 16:32:36
办公桌面的数字文件散落成堆,灵感碎片在聊天窗口与邮件间流浪——信息爆炸时代,...
发布日期: 2025-05-11 15:48:58
在信息过载的时代,许多用户依然依赖RSS订阅技术获取垂直领域的内容更新。尽管移动...

发布日期: 2025-06-06 17:48:01
在股票投资领域,K线图是技术分析的核心工具之一。对于普通投资者而言,掌握基础的...

发布日期: 2025-05-09 19:02:42
数据管理领域正经历从单一维度到多维协作的转型。当企业需要同时处理客户档案、产...

发布日期: 2025-04-29 10:15:17
在数字音频处理领域,Python生态中的PyAudio库因其跨平台特性与简洁API备受开发者青睐。...

发布日期: 2025-05-19 14:14:42
在Python生态中,Tkinter作为标准GUI库常被低估其潜力。通过Canvas画布组件实现的简易绘画...
")