发布日期: 2025-04-27 12:42:29
在数字化办公场景中,PDF文档处理已成为高频需求。一款名为「轻锋PDF」的本地化工具...

发布日期: 2025-05-08 10:35:10
清晨七点的阳光刚透进窗户,办公桌上的电脑突然自动启动。咖啡机运作的间隙,设计...

发布日期: 2025-04-08 12:26:30
打开手机应用商店搜索"日历",上百款应用让人眼花缭乱。其中有个绿色图标的程序下...

发布日期: 2025-04-25 19:01:17
服务器日志文件如同互联网世界的黑匣子,记录着每次请求的详细信息。面对每天数以...
发布日期: 2025-05-27 15:42:01
当代人对于时间管理的需求愈发多元,但不少专业软件存在功能臃肿、操作复杂的痛点...

发布日期: 2025-04-13 12:24:58
对于日常接触SQLite数据库的开发者而言,图形化操作工具往往能极大提升工作效率。近...

发布日期: 2025-04-05 19:16:07
电脑桌面上突然弹出的错误提示总在关键时刻消失?游戏通关的高光时刻总想分享给队...

发布日期: 2025-04-25 10:42:21
在数字化办公场景中,部分用户对操作记录的追溯存在需求,例如家长对未成年子女的...

发布日期: 2025-05-17 19:26:05
在信息爆炸的互联网环境中,快速获取并保存网页正文内容成为许多用户的需求。针对...

发布日期: 2025-04-10 09:53:44
桌面上零散堆着几百首MP3文件时,多数播放器的臃肿界面反而成了负担。某款体积仅...

发布日期: 2025-04-02 09:50:34
对于普通用户而言,复杂的网络监测工具往往令人望而生畏。这里推荐一款名为NetPul...
发布日期: 2025-04-21 11:31:40
屏幕上的光标突然动了起来,一笔一画勾勒出歪歪扭扭的正方形。对于Python初学者来说...

发布日期: 2025-04-08 12:12:03
打开电脑自带画图软件时,常被其简陋界面劝退的专业用户,或是需要快速记录灵感的...

发布日期: 2025-05-30 13:54:01
现代互联网应用中,表单填写始终是用户交互的关键环节。某款智能补全工具近期引发...

发布日期: 2025-04-16 15:56:23
互联网时代,海量数据每天以几何级数增长。当人们面对信息洪流时,如何快速获取有...

发布日期: 2025-05-21 09:48:42
在数字创作领域,鼠标绘图工具凭借其低门槛和即时性,逐渐成为普通用户表达创意的...
发布日期: 2025-05-08 12:11:55
在当今数据驱动的时代,获取网页中的结构化信息成为企业和研究者的核心需求。面对...

发布日期: 2025-04-16 13:36:02
近期在整理项目文件时,发现需要频繁验证文件的完整性。市面上的哈希校验工具要么...
发布日期: 2025-05-16 17:28:42
早晨八点的地铁站台,上班族小陈正用手机对着同事手写的会议纪要狂按快门。五分钟...

发布日期: 2025-05-15 10:20:54
点击启动图标瞬间,纯色画布随着屏幕亮起自动铺展。这个不足5MB的轻量化工具,省去...

发布日期: 2025-04-05 18:29:50
当鼠标滑过纽约证券交易所的实时行情走势图,悬浮的K线精确显示着毫秒级交易数据;...

发布日期: 2025-05-21 14:43:19
在信息爆炸的时代,知乎作为高质量内容社区,汇聚了大量专业讨论与观点碰撞。针对...

发布日期: 2025-03-29 16:01:00
工作间隙随手涂鸦,灵感迸发时记录抽象图案——日常场景中总缺不了一款零门槛的绘...
发布日期: 2025-06-08 16:54:03
互联网时代,信息获取效率直接影响工作进度。对于普通用户而言,复杂代码编写的网...

发布日期: 2025-06-04 09:00:02
窗外的阳光斜照在书桌上,草稿纸上的公式越写越密,手边的计算器按键已被磨得发亮...

发布日期: 2025-03-31 13:21:01
【核心功能】这款基于TXT文本的倒计时工具通过纯文字记录实现备考管理。用户在任意...

发布日期: 2025-04-20 10:09:28
在日常工作或学习中,人们常需对比两段文本的异同。无论是校对文档、审核内容,还...

发布日期: 2025-06-11 11:39:02
网络爬虫作为数据采集的基础手段,其开发效率常受框架复杂度的制约。基于Python生态...

发布日期: 2025-04-05 19:05:23
互联网时代,海量图片资源分散在不同网页中。对于需要批量获取特定类型图片的用户...

发布日期: 2025-04-29 10:15:17
在数字音频处理领域,Python生态中的PyAudio库因其跨平台特性与简洁API备受开发者青睐。...
发布日期: 2025-04-23 15:10:33
运维工程师张磊盯着屏幕上不断滚动的服务器日志,突然收到应用服务异常的告警通知...

发布日期: 2025-04-22 16:10:28
在中小型教育机构中,成绩管理始终是教务工作的核心环节。一款基于CSV文件存储数据...

发布日期: 2025-04-06 17:10:34
窗外的梧桐叶被风吹得沙沙作响,办公室的咖啡机传来规律的嗡鸣。每当这种时刻,电...

发布日期: 2025-05-21 11:14:51
随着社交媒体内容的价值被持续挖掘,知乎作为中文领域高质量问答社区,成为数据分...

发布日期: 2025-03-30 19:09:58
当面对需要批量获取网页数据的需求时,传统的手动保存或单页面下载方式常令使用者...

发布日期: 2025-05-25 12:24:58
在软件开发的入门阶段,很多开发者都会选择计算器作为首个GUI项目。市面上的开发模...

发布日期: 2025-03-26 12:54:02
本地开发场景中,SQLite因其零配置、单文件存储的特性广受欢迎。面对上百兆的数据库...

发布日期: 2025-03-25 11:45:30
在信息爆炸的时代,文字工作者常陷于排版困境。有人坚持用传统办公软件反复调整格...

发布日期: 2025-05-18 17:35:38
在中小型企业的日常运营中,库存管理常因手工记录混乱导致效率低下。某科技团队开...
发布日期: 2025-05-25 11:31:15
在编程学习中,图形界面开发一直是提升实践能力的重要环节。基于Python的Tkinter库,开...

发布日期: 2025-03-24 09:52:54
打开代码编辑器的瞬间,程序员的指尖在键盘上方停顿了五秒。显示器上堆砌着三层嵌...
发布日期: 2025-06-09 17:48:01
在数字化办公场景中,频繁填写网页表单的效率痛点长期困扰用户。传统手动操作不仅...

发布日期: 2025-04-24 10:04:49
日常工作中常会遇到需要提取PDF文档内容的场景。面对加密文件或扫描件,传统复制粘...

发布日期: 2025-06-11 19:45:01
数独游戏因其规则简单却极具挑战性的特点,成为全球流行的智力活动。设计一款既能...
发布日期: 2025-04-22 14:13:14
设计工作中最常遇到的场景,是看到某种配色特别想保存下来。这时候如果手动输入...

发布日期: 2025-04-29 13:42:01
在数据处理工作中,SQLite因其轻量便捷的特性广受欢迎。但对于非技术人员而言,命令...

发布日期: 2025-03-28 12:14:07
在信息爆炸的互联网时代,快速获取网页核心内容成为数据分析、舆情监测等领域的关...

发布日期: 2025-04-13 13:07:49
在数字化办公场景中,网页表单的重复性填写成为许多从业者的痛点。例如,电商运营...

发布日期: 2025-04-29 17:19:47
在信息爆炸的互联网环境中,网页数据采集工具正成为企业及个人用户的高频需求。一...
发布日期: 2025-05-04 14:22:31
纸质手账本在数字时代正逐渐被电子笔记取代,当人们开始追求更高效的记录方式时,...

发布日期: 2025-03-24 11:18:36
办公桌前的键盘声此起彼伏,闪烁的光标前总在上演相似的场景:刚复制好的地址被新...
发布日期: 2025-05-26 16:13:53
网络数据采集领域,Scrapy框架因其模块化设计和异步处理能力备受开发者青睐。本文将...

发布日期: 2025-04-22 19:26:36
互联网信息以每秒数万次的速度刷新,传统网页监测工具常因单线程运作陷入效率瓶颈...

发布日期: 2025-05-25 17:55:37
迷宫,一种古老的空间游戏,如今在数字工具的加持下焕发新生。简易迷宫生成器凭借...

发布日期: 2025-05-15 12:18:58
在数字内容创作蓬勃发展的今天,许多创作者开始寻求自主掌控内容的解决方案。基于...

发布日期: 2025-04-03 16:21:01
现代网页设计领域流传着一句行话:"从浏览器标签页的图标就能判断开发者的专业度。...
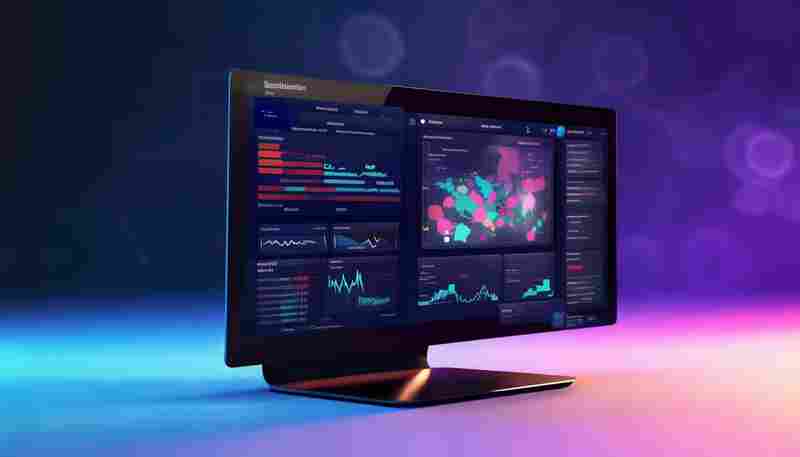
发布日期: 2025-04-24 19:18:24
在信息爆炸的时代,企业或个人想要精准页内容的动态变化,如同大海捞针。一款以关...

发布日期: 2025-04-12 15:20:26
在日常数据处理工作中,频繁面对CSV文件与数据库之间的转换需求是许多开发者、数据...
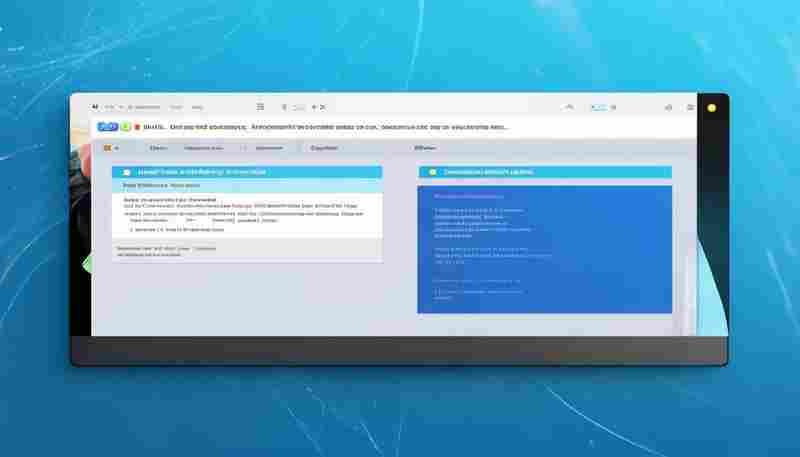
发布日期: 2025-05-17 12:37:35
互联网数据采集领域,验证码始终是自动化工具需要突破的技术难点。本文介绍一款集...

发布日期: 2025-06-07 19:24:02
阳光透过百叶窗洒在桌面上,手绘板连接电脑的瞬间,光标化作一支虚拟画笔。在数字...
")