
发布日期: 2025-03-29 15:53:51
办公族和设计师的电脑桌面上,总会出现各种截图工具的身影。在众多同类软件中,区...

发布日期: 2025-03-28 14:18:40
在数字化场景日益复杂的今天,网络稳定性已成为企业运营和个人用户体验的核心命脉...

发布日期: 2025-04-19 10:38:08
周末晚上八点,某视频团队正准备跨国传输4K素材时,网络突然卡顿。运维组长调出近...
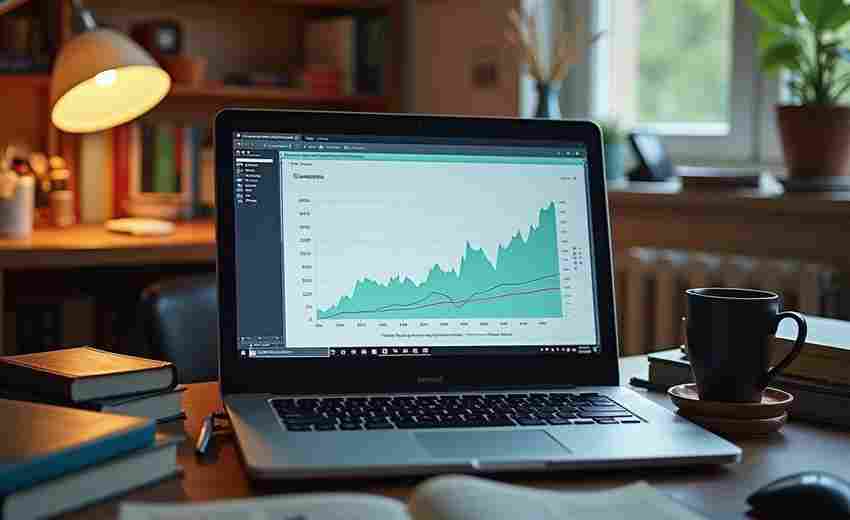
发布日期: 2025-04-21 14:11:56
写作过程中,章节字数的波动往往暗藏叙事节奏的秘密。传统的手工统计耗时费力,且...

发布日期: 2025-04-12 16:03:43
现代人的电子设备常被各类任务挤占。视频会议需要同步记录要点,网课教程得配合实...
发布日期: 2025-05-02 19:08:41
在互联网应用开发领域,Flask框架凭借其简洁灵活的特性,成为快速搭建社区论坛的优...

发布日期: 2025-03-21 09:43:11
清晨拉开窗帘前,许多人习惯先看一眼手机上的天气应用。但频繁解锁屏幕难免麻烦,...
发布日期: 2025-04-26 16:18:48
凌晨三点的机房警报声响起时,运维工程师老张摸索着关闭手机闹钟。这次不是真实的...

发布日期: 2025-05-13 09:04:04
窗外的雨滴敲打着玻璃,天气预报却总在手机里沉睡。当工作文档铺满屏幕时,突然弹...

发布日期: 2025-03-25 15:34:41
对于长期使用Windows系统的用户而言,注册表冗余项积累导致的系统卡顿、软件冲突等问...

发布日期: 2025-04-20 12:50:00
清晨七点的地铁车厢里,指尖在磨砂金属表面划过,实体按键的触感透过指腹传来。这...

发布日期: 2025-04-22 17:11:15
一张吸睛海报需要几步完成?过去可能需要专业软件、设计培训与数小时反复修改。如...

发布日期: 2025-03-28 13:18:02
在中小型团队内部,文档共享与知识沉淀常面临效率瓶颈。基于Python Flask框架开发的局...

发布日期: 2025-04-13 13:25:48
在效率工具泛滥的时代,程序员和技术爱好者们逐渐发现:最原始的交互方式,往往隐...

发布日期: 2025-04-24 17:13:23
一款优秀的数独生成工具,能够根据用户需求快速生成不同难度的题目,同时兼顾趣味...

发布日期: 2025-05-02 16:08:23
在互联网数据呈指数级增长的背景下,定向抓取特定网站的网络爬虫工具逐渐成为企业...
发布日期: 2025-04-26 15:43:04
在数据成为核心生产力的时代,许多职场人常面临这样的困境:市场部的Mary需要分析五...

发布日期: 2025-04-18 09:00:02
身高体重指数(BMI)作为国际通用的健康评估指标,已成为现代人快速了解自身体质的...

发布日期: 2025-04-21 12:49:57
在软件工程领域,代码质量直接影响项目成败。某研发团队曾因忽略代码规范导致项目...

发布日期: 2025-04-23 17:29:37
在Python生态中,Tkinter作为标准GUI库常被开发者忽视,但其低门槛和轻量化特性使其成为...

发布日期: 2025-03-21 10:03:01
物联网设备的快速普及让MQTT协议逐渐成为设备通信的主流选择。这种轻量级的发布-订...

发布日期: 2025-04-12 15:52:56
写字楼会议室视频会议频繁卡顿,商场餐饮区扫码点餐总显示加载中,智能家居设备间...

发布日期: 2025-05-11 15:20:16
互联网环境中,设备间通信依赖端口状态传递数据。某企业运维团队曾因数据库端口意...

发布日期: 2025-04-15 14:06:20
打开电脑绘制流程图时,多数人都有过类似经历:精心设计的方案在交付时出现图形错...

发布日期: 2025-03-27 15:14:48
在屋顶光伏日渐普及的背景下,某技术爱好者社区近期流传着一套基于SQLite数据库的发...

发布日期: 2025-04-10 16:07:41
在人工智能技术快速发展的当下,手写数字识别作为计算机视觉领域的经典问题,始终...
发布日期: 2025-04-21 10:27:31
当区块链技术逐渐渗透到金融、物流、政务等核心领域时,公众对其底层机制的认知鸿...

发布日期: 2025-04-30 09:16:44
互联网时代,海量网页数据蕴藏着大量价值。如何快速定位目标链接并实现批量提取?...

发布日期: 2025-03-23 10:47:19
在线简易备忘录:用分类标签重塑效率管理 现代人生活节奏快,待办事项常如潮水般涌...

发布日期: 2025-04-24 16:27:01
网页标题作为站点内容的核心标识,往往承载着关键信息。针对特定网站的标题采集需...

发布日期: 2025-04-02 12:44:36
在大数据时代,获取网络信息的效率直接影响着决策质量。一款支持关键词过滤的简易...

发布日期: 2025-03-26 09:45:28
键盘敲击声密集响起,屏幕顶端随机掉落的单词正以肉眼可见的速度下降。右手紧握鼠...

发布日期: 2025-04-29 18:13:20
清晨八点的咖啡杯旁,程序员老张习惯性打开终端。三行命令之后,昨晚用Markdown写的...

发布日期: 2025-04-17 14:38:38
在信息爆炸的时代,如何高效追踪内容更新成为技术从业者的刚需。基于终端的RSS阅读...

发布日期: 2025-04-14 18:25:38
在网站运维过程中,断链、死链的存在不仅影响用户体验,还会导致搜索引擎排名下滑...

发布日期: 2025-04-18 12:15:52
网络服务质量的优劣直接影响用户体验,如何准确评估网络性能成为运维领域的核心课...

发布日期: 2025-04-30 14:46:37
办公桌上堆着七份不同格式的PDF文档,从扫描合同到加密报表,这些文件正在考验着新...

发布日期: 2025-04-23 18:01:37
爬虫技术的迭代演进催生出众多高效工具,Scrapy框架凭借其模块化设计与工业级性能表...

发布日期: 2025-04-08 16:43:50
在线上会议、网课教学或远程协作场景中,快速标注屏幕内容的需求越来越普遍。一款...
发布日期: 2025-04-29 10:22:25
在信息爆炸的时代,高效获取并管理内容成为刚需。一款名为 FeedCache 的简易RSS阅读器...

发布日期: 2025-04-15 10:41:36
随着全球视频创作者数量突破5000万,YouTube平台日均新增评论量超过20亿条。面对海量的...

发布日期: 2025-05-08 13:51:59
在本地开发或团队协作场景中,经常需要快速共享项目文件。传统的FTP或云盘方案配置...

发布日期: 2025-04-19 19:53:50
在互联网应用中,留言板作为用户互动的基础功能,常被用于收集反馈、社区交流等场...

发布日期: 2025-03-26 13:40:22
网络爬虫开发者最头疼的问题之一,莫过于IP地址被封禁。当目标网站的风控系统识别...

发布日期: 2025-04-03 14:41:23
在IPv4向IPv6过渡、HTTP/2逐步取代HTTP/1.1的技术迭代背景下,协议版本性能对比工具已成为...
发布日期: 2025-04-25 19:08:34
市面上一款名为QuickMailer的轻量级邮件客户端近期引发关注,其核心功能直击日常办公...

发布日期: 2025-05-04 11:59:16
在编程工作中,临时搭建一个本地HTTP服务器的需求并不少见。比如调试网页接口、快速...

发布日期: 2025-04-22 15:49:16
在网络安全威胁指数级增长的今天,密码暴力破解时间估算器正在成为网络安全领域的...

发布日期: 2025-03-26 18:54:26
在互联网应用中,代理服务器的重要性无需赘述。但市面上的验证工具要么操作繁琐,...

发布日期: 2025-04-18 19:47:00
端口扫描作为网络运维的基础操作,对扫描结果的保存与分析直接影响后续排查效率。...
发布日期: 2025-04-23 15:10:33
运维工程师张磊盯着屏幕上不断滚动的服务器日志,突然收到应用服务异常的告警通知...
发布日期: 2025-03-24 11:24:01
在复杂的网络环境中定位数据传输路径的阻塞点,基于ICMP协议的路径追踪工具始终是网...

发布日期: 2025-03-24 11:55:22
窗外的梧桐叶随风晃动,电脑屏幕前的手指正握着鼠标在画布上勾线。这个仅占用8MB内...
发布日期: 2025-04-23 12:01:27
现代人工作生活几乎离不开网络支撑。当视频会议频繁卡顿、文件传输进度条停滞时,...

发布日期: 2025-03-28 18:09:28
清晨八点半的咖啡馆,程序员林夏的MacBook旁摆着一枚银色计时器。金属外壳被摩挲得发...

发布日期: 2025-03-27 17:37:12
窗外的蝉鸣逐渐微弱,显示器右下角的半透明数字跳至17:00。这个由Python开发的桌面时...

发布日期: 2025-04-04 13:20:07
密码管理一直是数字生活的痛点。随手写在便签纸容易泄露,重复使用弱密码风险高,...

发布日期: 2025-04-04 09:00:02
运维工程师张明盯着屏幕上不断滚动的日志文件,十指在键盘上停顿了三次又继续敲击...

发布日期: 2025-03-28 16:58:17
网络爬虫技术自互联网诞生以来便持续迭代,近期某开发者论坛开源的工具包因兼顾效...

发布日期: 2025-05-03 11:32:49
纽约街头的温度计显示华氏75度,巴黎商场的手表标注38毫米表盘,东京超市的牛排标价...
")