
发布日期: 2025-04-15 14:06:20
打开电脑绘制流程图时,多数人都有过类似经历:精心设计的方案在交付时出现图形错...

发布日期: 2025-04-12 11:03:22
当代人获取信息的场景日益碎片化,文字转语音工具逐渐成为提升效率的刚需。对于注...

发布日期: 2025-04-14 10:31:55
在线上教育资源井喷的当下,学员常面临课程视频分散、平台限制下载的困扰。一款名...

发布日期: 2025-04-21 16:17:07
按下方向键的瞬间,屏幕上的像素点蛇头突然调转方向——这个诞生于1976年的经典游戏...
发布日期: 2025-03-27 16:18:49
端口扫描工具作为网络安全领域的"听诊器",能够快速探查目标主机的服务开放状态。...
发布日期: 2025-04-16 13:50:29
在程序员日常开发中,网络质量直接影响工作效率。某次项目部署时,团队遭遇上传速...

发布日期: 2025-03-29 17:40:39
网络论坛沉淀着海量的实时讨论内容,如何高效获取并分析这些信息成为许多研究者的...

发布日期: 2025-04-11 15:43:35
凌晨三点的机房服务器仍在嗡鸣作响,显示屏上的代码行如同流水线般滚动。这种昼夜...

发布日期: 2025-04-04 10:57:30
在网络安全威胁日益严峻的今天,一个可靠的密码已成为保护个人隐私的第一道防线。...

发布日期: 2025-04-16 09:32:46
在Web开发中,JSON Web Token(JWT)已成为跨系统身份验证的主流方案之一。但对于需要快...

发布日期: 2025-04-24 09:18:23
作为Python自带的GUI工具包,Tkinter长久以来都是新手接触图形界面开发的首选。最近在...

发布日期: 2025-04-18 15:23:22
日常使用电脑时,总会出现程序卡死、后台异常这类恼人的状况。Windows系统自带的任务...

发布日期: 2025-03-22 11:12:01
数独作为风靡全球的数字谜题,对逻辑思维要求极高。传统纸质题册更新慢,在线平台...
发布日期: 2025-04-25 12:03:58
在日常工作与生活中,任务管理效率直接影响个人生产力。对于追求轻量化工具的用户...

发布日期: 2025-04-18 10:13:37
在众多音乐播放器中,轻量化工具因其简洁性逐渐受到用户青睐。近期一款名为 Harmo...

发布日期: 2025-03-24 14:00:46
纸质书籍的厚重感逐渐被电子墨水取代时,一款轻量化的阅读工具成为刚需。电子书阅...

发布日期: 2025-03-21 11:53:18
当前网络环境中,视频平台的VIP内容解析工具正悄然改变着用户的观影方式。这类工具...

发布日期: 2025-04-10 15:21:33
在智能手机普及的今天,人们常忽略那些隐藏在应用列表里的基础工具。其中支持表达...

发布日期: 2025-04-08 11:25:56
在网络安全威胁日益复杂的今天,企业对于漏洞管理的要求已从被动修复转向主动防御...

发布日期: 2025-04-25 19:51:19
在互联网技术快速迭代的背景下,Web服务器作为信息传输的核心载体,始终扮演着关键...
发布日期: 2025-03-22 11:59:17
在第三方文本工具层出不穷的当下,一款名为TEdit Pro的桌面应用近期在技术社区引发讨...

发布日期: 2025-04-02 13:41:51
语言障碍在全球化场景中愈发凸显。一款支持多语种API调用的翻译工具,正在成为跨语...
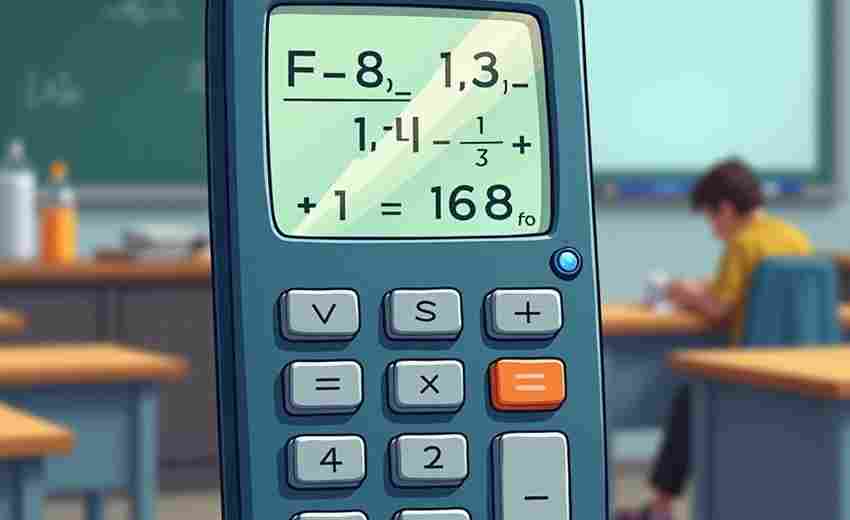
发布日期: 2025-04-08 18:41:27
清晨的实验室里,工程师小王对着显示屏上复杂的流体力学公式皱眉。传统计算器的按...

发布日期: 2025-04-26 11:04:31
网络爬虫技术已成为企业获取数据的重要手段,而如何高效管理爬虫任务并确保稳定性...

发布日期: 2025-04-07 17:07:51
网络数据采集过程中,代理IP失效导致采集中断的情况屡见不鲜。某开发者论坛近期流...

发布日期: 2025-04-19 10:16:44
清晨七点,闹钟第三次响起时,手机屏幕自动亮起备忘录:"重要会议资料需在九点前发...

发布日期: 2025-03-23 09:25:44
办公室的玻璃窗外飘着细雨,行政部的小王正焦头烂额翻找纸质通讯录。市场部急需联...

发布日期: 2025-04-17 12:39:02
当互联网成为信息海洋的时代,手动收集网页数据就像用木桶舀海水般低效。网络爬虫...

发布日期: 2025-04-11 12:20:03
在数字身份管理成为刚需的当下,一款基于Flask框架开发的网页端密码保险箱工具悄然...

发布日期: 2025-04-02 13:38:16
书桌前散落着未拆封的咖啡包,电脑屏幕上开着三个文档窗口,手机在裤袋里每隔两分...
发布日期: 2025-04-10 14:03:02
纸质单词本逐渐被电子工具替代的当下,一款名为「FlashMemo」的轻量化记忆卡片系统,...

发布日期: 2025-03-23 09:39:38
现代生活节奏快,工作事务繁杂,许多人习惯用清单工具管理每日任务。基于Python的...

发布日期: 2025-04-09 09:43:44
在工业设计、3D打印及数字化建模领域,STL格式因其广泛兼容性成为三维模型传输的标...

发布日期: 2025-04-24 14:04:21
对于需要快速绘制基础几何图形的用户而言,简易绘图板软件凭借其直观的操作和轻量...

发布日期: 2025-04-03 18:43:32
在数据采集需求日益增长的背景下,一款名为WebExtractor的轻量级工具在开发者社区引发...
发布日期: 2025-04-25 09:20:06
数据可视化的门槛正被一款名为"ChartFlow"的工具打破。这款基于CSV格式的轻量级工具,...
发布日期: 2025-03-30 12:30:50
在金融交易领域,数据可视化工具正成为投资者不可或缺的决策助手。基于Python技术栈...

发布日期: 2025-04-13 09:29:40
网络安全工程师李明在检测某政务系统时,发现其响应头缺失关键安全配置,攻击者仅...

发布日期: 2025-03-27 11:44:30
SQLite轻量化数据库在移动端和嵌入式场景广泛应用,但其原生工具链缺乏便捷的备份解...

发布日期: 2025-04-20 09:40:58
午后的阳光斜照进咖啡馆,邻桌女孩的手机突然传出《致爱丽丝》的旋律。抬眼望去,...

发布日期: 2025-04-23 16:32:37
在数据采集领域,定时爬虫的可靠性与灵活性直接影响业务效率。针对需要周期性执行...

发布日期: 2025-04-05 12:26:27
互联网时代的数据采集需求呈现出碎片化与即时化特征。针对中小型业务场景的快速数...

发布日期: 2025-03-28 10:34:18
网络爬虫技术为数据采集提供了便利,表格数据抓取作为其中高频需求,已成为市场研...

发布日期: 2025-04-19 15:19:24
在信息爆炸的移动互联网时代,高效获取有效资讯已成为现代人的刚需。一款具备内容...
发布日期: 2025-04-23 13:44:51
网络设备发现技术作为现代网络管理的基础功能,其实现方式直接影响着运维效率。传...
发布日期: 2025-03-22 12:23:25
互联网数据的指数级增长让企业面临信息处理的巨大挑战。某科技团队近期推出的网络...

发布日期: 2025-04-06 17:10:34
窗外的梧桐叶被风吹得沙沙作响,办公室的咖啡机传来规律的嗡鸣。每当这种时刻,电...

发布日期: 2025-04-08 18:59:19
打开电脑写文档时,总有人对着凌乱的格式皱眉头。调整标题字号、对齐段落、插入代...

发布日期: 2025-04-10 15:03:44
在信息过载的数字化时代,电子邮件依然是职场沟通和个人事务的重要工具。一款高效...

发布日期: 2025-04-16 18:09:02
键盘敲击声频繁响起的午后,办公室角落里突然爆出一声哀叹。同事小李的电脑屏幕上...

发布日期: 2025-04-07 13:44:05
午后的咖啡馆里,手指在手机屏幕上来回滑动,寻找与此刻情绪契合的播放列表。这个...

发布日期: 2025-04-23 15:06:50
屏幕右下角的消息提示音每隔几秒就会响起,聊天窗口的滚动速度肉眼几乎难以捕捉。...

发布日期: 2025-03-23 10:43:45
网络卡顿、视频会议掉线、文件传输中断……这些问题背后往往存在同一个隐形杀手—...

发布日期: 2025-04-08 15:36:01
在技术快速迭代的当下,GitHub作为全球最大的开源社区,每天都会涌现大量创新项目。...

发布日期: 2025-04-25 12:46:58
黑白交错的国际象棋棋盘是棋类运动的标志性符号。对于需要快速生成标准棋盘的用户...

发布日期: 2025-04-07 18:44:10
清晨八点的地铁车厢里,上班族小陈习惯性掏出手机。不同于周围刷短视频的人群,他...

发布日期: 2025-03-21 13:22:29
在信息爆炸的时代,内容创作者常陷入工具选择的困境。当市面上的博客平台愈发臃肿...

发布日期: 2025-03-24 13:01:07
在日常办公场景中,Excel表格的数据处理需求频繁出现,尤其是多表格合并或单表拆分...

发布日期: 2025-03-31 18:55:56
在全球化业务部署和混合云架构普及的背景下,网络质量监测逐渐从单点测试转向分布...

发布日期: 2025-04-02 14:28:09
对于需要快速处理数学运算或日常单位转换的用户而言,一台功能实用、界面简洁的计...
")