
发布日期: 2025-06-14 12:06:03
数字信息爆炸的时代,每天产生的新闻资讯如同暴雨倾盆。当微博热搜每小时更新、微...

发布日期: 2025-04-21 16:06:22
互联网时代,数据采集已成为技术人员的必修课。在众多网页解析工具中,BeautifulSou...

发布日期: 2025-04-11 19:33:02
凌晨三点,证券分析师陈默被手机震动惊醒。屏幕推送着某上市公司突发公告,他立刻...

发布日期: 2025-03-28 15:50:40
在信息爆炸的互联网时代,如何精准获取所需内容并避免被冗余信息淹没,成为许多用...

发布日期: 2025-04-12 10:17:17
金融市场的瞬息万变让实时资讯成为决策命脉。在信息爆炸的财经领域,一款基于多线...

发布日期: 2025-05-24 13:20:11
在信息爆炸的时代,数据获取能力直接影响工作效率。Python生态中的网页解析工具Bea...

发布日期: 2025-06-08 13:12:02
信息爆炸的时代,如何精准获取有效内容成了现代人的刚需。在众多工具中,RSS(简易...

发布日期: 2025-03-30 11:37:28
在信息爆炸的时代,快速获取有效内容已成为刚需。RSS(简易信息聚合)技术凭借其“...

发布日期: 2025-04-03 16:38:54
在这个信息爆炸的时代,每天产生的新闻资讯如同潮水般涌来。面对海量信息,人们常...
发布日期: 2025-06-03 19:42:02
在信息爆炸的时代,如何快速获取精准的本地资讯成为许多人的痛点。传统方式下,用...

发布日期: 2025-06-08 09:48:01
在信息过载的数字时代,用户对工具软件的需求早已突破基础功能层面。某款新近推出...

发布日期: 2025-04-03 11:24:29
互联网时代,新闻网站头条如同信息洪流中的灯塔,承载着公众关注的焦点。面对海量...

发布日期: 2025-05-19 10:18:14
在海量信息爆炸的互联网环境中,用户评论作为新闻传播的重要反馈载体,每天产生数...
发布日期: 2025-05-08 19:13:46
在信息爆炸的时代,新闻数据的快速处理与深度解析成为媒体从业者、市场研究人员甚...
发布日期: 2025-04-15 10:23:27
对于需要快速实现浏览器外壳功能的开发者而言,pywebview这个Python库正逐渐成为热门选...

发布日期: 2025-07-16 12:54:01
企业每天产生的日志数据呈指数级增长,如何从海量日志中快速定位异常事件并还原攻...

发布日期: 2025-06-03 09:12:01
2023年第三季度,某技术团队完成了一套针对新闻网站的图片自动化处理系统。该系统基...
发布日期: 2025-05-11 11:41:58
清晨七点的地铁站台,西装革履的年轻人单手握着咖啡,另一只手在手机屏幕上快速滑...
发布日期: 2025-06-26 16:00:02
在信息过载的时代,RSS技术始终是内容筛选的经典方案。对于追求效率的开发者、系统...
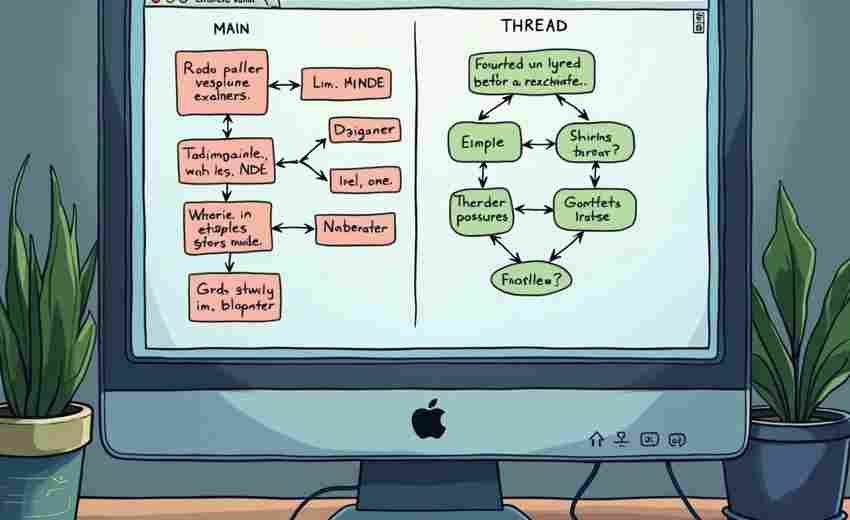
发布日期: 2025-03-31 15:25:35
在信息爆炸时代,定制专属新闻源成为刚需。基于Python的Flask框架搭建RSS阅读器,开发...

发布日期: 2025-05-08 15:14:05
清晨六点,纽约证券交易所的电子钟还未敲响,某香港私募基金的年轻分析师已打开手...
发布日期: 2025-05-11 16:21:01
在数据分析与可视化领域,快速构建灵活、交互性强的仪表盘一直是开发者的核心需求...
发布日期: 2025-04-24 15:51:24
清晨打开电脑或手机,桌面上实时滚动的新闻摘要第一时间抓住视线。这款支持TTS(文...

发布日期: 2025-04-13 16:00:25
在信息爆炸的时代,每天产生的新闻文本以亿计量级增长。如何快速识别核心内容的情...
发布日期: 2025-05-26 17:25:55
在数据驱动的互联网时代,高效稳定的爬虫系统已成为企业获取信息的重要工具。针对...

发布日期: 2025-03-22 09:28:01
在信息爆炸的数字化时代,高效获取有效资讯逐渐成为刚需。基于RSS技术的新闻聚合工...

发布日期: 2025-05-07 16:12:03
在数据科学领域,工具迭代速度往往比传统软件开发更快。当Python成为数据工作者的主...
发布日期: 2025-04-25 19:12:01
互联网每天产生数以亿计的网页数据,企业需要实时监控竞品价格,学术研究者需要抓...
发布日期: 2025-07-01 11:00:01
电脑屏幕右下角弹出第17条推送时,终于有人意识到问题所在——我们正在被算法投喂...

发布日期: 2025-04-01 19:05:53
在信息爆炸的时代,如何快速获取新闻核心内容成为许多人的刚需。一款基于人工智能...
发布日期: 2025-04-10 16:40:12
新闻聚合爬虫工具中,基于Python的BeautifulSoup库因其灵活性和易用性备受开发者青睐。这...

发布日期: 2025-04-06 17:21:19
互联网时代,新闻资讯以秒为单位迭代更新。某科技公司研发的新闻网站滚动更新内容...
发布日期: 2025-07-22 12:48:01
清晨七点的地铁里,戴着蓝牙耳机的上班族闭目养神,耳边流淌着晨间新闻播报;深夜...

发布日期: 2025-04-06 15:08:37
在线考试系统的开发中,单选题作为基础题型,其功能实现直接影响系统的可用性。利...

发布日期: 2025-04-09 12:35:34
新闻网站评论区作为公众舆论的重要载体,正在成为社会各界关注的信息富矿。针对这...

发布日期: 2025-04-13 18:09:43
在这个信息爆炸的时代,每天打开手机至少会收到32条新闻推送通知。某互联网公司最...

发布日期: 2025-05-23 17:26:11
在快节奏的工作场景中,一款简洁高效的在线备忘录工具能显著提升信息管理效率。...

发布日期: 2025-04-03 18:36:23
当手机每天推送300条新闻却找不到一条真正需要的资讯时,当代人正在经历前所未有的...

发布日期: 2025-03-27 13:45:43
在全球信息爆炸的时代,跨语言新闻获取成为刚需。一款名为"GlobalFeed"的多语言新闻摘...

发布日期: 2025-06-10 19:18:01
清晨七点的地铁站台,西装革履的金融从业者戴着蓝牙耳机,西班牙语播报的拉美经济...

发布日期: 2025-05-08 12:01:13
在信息爆炸的时代,快速获取并分析网络新闻内容成为企业、研究机构及个人的刚需。...

发布日期: 2025-04-04 17:32:55
开发团队在软件交付环节常面临重复劳动难题。某金融App团队曾因手动打包失误导致生...
发布日期: 2025-07-24 17:30:01
在信息爆炸的互联网环境中,分类订阅型RSS阅读器正成为知识工作者的效率利器。这类...

发布日期: 2025-04-20 18:28:38
在信息爆炸的数字化时代,高效获取新闻资讯成为刚需。新闻网站文章链接抓取器作为...

发布日期: 2025-06-15 11:36:02
在软件工程实践中,构建产物从开发环境到生产环境的流转常面临多重风险。某头部电...

发布日期: 2025-05-03 15:00:22
开发团队常面临这样的困境:某次版本更新后,测试环境运行正常的代码在线上突然崩...
发布日期: 2025-08-06 13:54:01
在信息爆炸的传播环境中,新闻稿的传播效果往往与关键词的运用密切相关。如何快速...

发布日期: 2025-03-24 12:04:58
在信息爆炸时代,每天全球产生的新闻标题数以百万计。某款自主研发的时间序列分析...
发布日期: 2025-07-23 13:06:01
网页数据抓取领域存在诸多技术方案,Python生态中的BeautifulSoup库因其独特的文档树解析...
发布日期: 2025-07-14 17:30:01
在信息爆炸的数字化时代,快速提炼文本核心内容成为刚需。一款基于Gradio框架开发的...
发布日期: 2025-06-29 14:30:01
数字化时代,信息获取效率成为现代人的核心竞争力。面对海量资讯,一款支持分类收...

发布日期: 2025-04-16 12:35:14
在信息爆炸的数字化时代,每天产生的新闻资讯量足以填满三座大型图书馆。专业媒体...

发布日期: 2025-03-31 19:44:18
在信息过载的时代,媒体每天产出超过300万条新闻资讯。面对如此庞大的数据洪流,某...

发布日期: 2025-06-13 11:30:02
互联网时代,信息过载与内容风险成为企业及个人用户面临的现实挑战。如何在保障信...

发布日期: 2025-04-29 14:39:02
新闻行业每天产生海量信息,如何快速捕捉核心内容成为从业者的必修课。新闻标题关...

发布日期: 2025-04-09 09:33:01
(正文开始) 工具定位与特点 BeautifulSoup作为Python生态中经典的HTML解析库,常被用于构...

发布日期: 2025-06-10 10:12:02
全球金融市场每日产生海量信息,投资者常陷入数据沼泽难以抉择。某科技公司近期推...

发布日期: 2025-04-19 19:39:35
网页数据抓取技术中,表格信息的结构化提取常让开发者头疼。Python生态中的Beautiful...

发布日期: 2025-06-20 15:12:01
在信息爆炸的时代,新闻工作者常面临海量文本处理难题。如何从每日数百篇稿件中快...

发布日期: 2025-03-31 14:17:57
在信息爆炸的互联网环境中,新闻聚合平台需要持续获取时效性强、覆盖面广的内容资...