
发布日期: 2025-07-04 19:42:01
凌晨三点,手机屏幕突然亮起,Telegram弹出一条告警消息:"服务器CPU负载突破95%阈值...

发布日期: 2025-04-26 16:29:31
教室里的数学老师将统计题目同步到电子白板,三十名学生同时输入变量;跨国项目组...
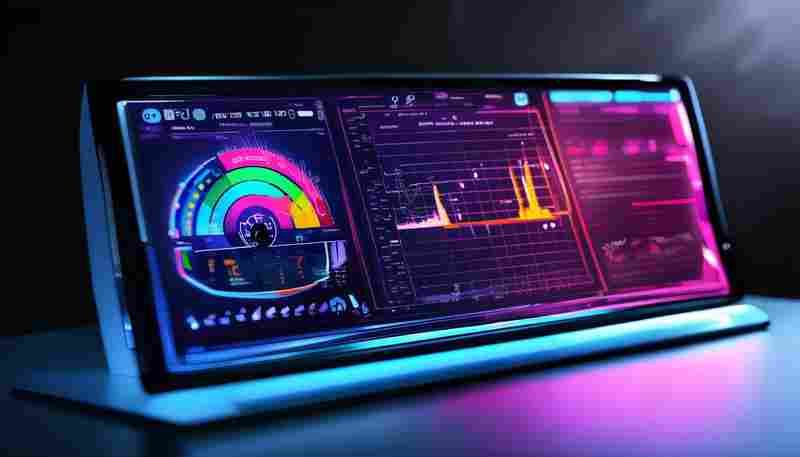
发布日期: 2025-05-26 19:56:25
在服务器运维与程序开发场景中,系统资源的实时监控如同驾驶舱里的仪表盘。本文将...
发布日期: 2025-08-20 10:24:02
在日常服务器运维或开发调试过程中,文件系统挂载点的异常状态往往成为隐蔽的风险...

发布日期: 2025-06-08 18:54:01
在计算机系统管理中,实时监控运行进程的能力直接影响故障排查效率。本文将以进程...

发布日期: 2025-03-31 14:10:49
凌晨三点的服务器机房,数十万张医疗票据扫描件在硬盘阵列中沉睡。当城市尚未苏醒...

发布日期: 2025-04-26 17:05:13
互联网流量运营领域,URL缩短工具早已突破基础功能边界。当营销活动需要追踪十万级...

发布日期: 2025-04-13 12:28:20
在Windows系统的深层架构中,隐藏着超过200个基础服务程序,它们如同精密钟表的齿轮般...
发布日期: 2025-07-20 19:30:02
在互联网即时通讯技术日益成熟的今天,使用Python语言搭建简易聊天室服务器端成为开...
发布日期: 2025-08-20 12:00:02
凌晨三点的机房警报声响起时,运维工程师面对突然宕机的服务器常常陷入困境。传统...

发布日期: 2025-04-15 11:24:50
随着服务器日志文件体积的突破性增长,运维人员普遍面临两大痛点:海量日志占据存...

发布日期: 2025-04-30 17:20:11
在数据中心运维领域,服务器监控报警工具如同人体神经系统般重要。当某台物理服务...
发布日期: 2025-08-13 09:18:01
凌晨三点的数据中心,蜂鸣器突然响起,值班工程师的手机弹出红色警报——某核心服...

发布日期: 2025-03-27 12:48:39
互联网服务的稳定性直接影响用户体验,而服务器返回的HTTP状态码往往是问题排查的第...
发布日期: 2025-07-20 16:00:02
凌晨三点的机房警报声响起时,运维工程师王磊的工位电话同步震动。监控大屏上,某...

发布日期: 2025-06-19 18:24:02
Python内置的轻量级服务器工具:http.server模块使用指北 办公桌上堆着设计稿和产品原型...

发布日期: 2025-04-28 18:30:00
在分布式系统架构中,服务启动耗时直接影响业务连续性。某电商平台曾因支付服务冷...
发布日期: 2025-05-17 13:46:17
在服务器运维或文件共享场景中,技术人员常遇到需要将本地目录树快速转化为可下载...
发布日期: 2025-08-11 17:00:01
全球分布式架构的普及使企业面临多区域服务端口管理的挑战。某安全团队研发的跨区...
发布日期: 2025-05-31 09:48:01
窗外的服务器指示灯在暗夜里规律地闪烁,运维工程师老张突然接到报警短信。他打开...
发布日期: 2025-06-26 11:48:01
凌晨三点的告警提示音,对于运维团队来说如同噩梦。服务突然崩溃,手动重启耗时费...
发布日期: 2025-08-10 17:06:02
运维工程师凌晨三点接到告警电话,系统监控界面显示核心业务服务连续三次异常重启...
发布日期: 2025-08-16 15:24:03
在全球化应用开发场景中,文字编码处理已成为基础架构的关键环节。某技术团队推出...
发布日期: 2025-07-20 12:36:01
在企业IT运维场景中,Windows服务的稳定性直接影响业务连续性。传统人工巡检服务状态...
发布日期: 2025-06-17 11:00:02
用Discord搭建网站更新提醒工具 互联网信息更新速度快,用户常因无法及时获取网站内...

发布日期: 2025-03-23 11:17:07
在数据中心机房此起彼伏的警报声中,某电商平台的技术团队曾经历过惊心动魄的24小...

发布日期: 2025-03-28 13:32:23
在Linux服务器运维过程中,管理员时常遇到需要动态修改运行中进程参数的情况。某次...

发布日期: 2025-05-14 09:39:21
在本地开发与调试过程中,开发者常遇到需要快速启动临时服务器的场景。笔者实测多...

发布日期: 2025-06-13 10:54:02
面对服务器每天产生的GB级日志文件,运维工程师张磊打开Jupyter Notebook,在Python环境中...

发布日期: 2025-03-25 13:44:18
在服务器机房此起彼伏的嗡鸣声中,运维工程师的日常工作如同在钢丝上行走。某个关...

发布日期: 2025-06-14 15:36:01
在数字化转型的浪潮中,数据格式转换已成为企业日常运营的基础需求。基于Python Fl...
发布日期: 2025-07-07 16:24:02
凌晨三点,某电商平台的支付系统突然崩溃。运维团队在二十台服务器之间来回切换,...
发布日期: 2025-05-11 17:39:55
服务器监控面板突然弹出红色警报,凌晨两点三刻的运维值班室,工程师的咖啡杯停在...

发布日期: 2025-06-13 13:18:02
运行中的服务器突然宕机,生产线设备突发高温报警,实验室精密仪器因过热导致数据...
发布日期: 2025-07-16 09:42:02
在Linux服务器管理中,系统服务管理是每位运维工程师的日常必修课。传统的操作方式...
发布日期: 2025-07-23 15:36:01
服务器日志像人体的健康数据,每分每秒都在记录系统运行状态。传统人工巡检如同用...
发布日期: 2025-06-26 15:18:02
Windows系统长期使用后常伴随启动项冗余问题。通过注册表与服务项的精简管理,可有效...

发布日期: 2025-05-09 14:37:14
在企业的IT基础设施中,系统服务进程的稳定性直接关系到业务连续性。一次突发的服...

发布日期: 2025-03-22 10:47:09
全球超过80%的服务器使用SSH协议进行远程管理,而恶意登录尝试数量正以每年37%的速度...

发布日期: 2025-06-11 14:27:01
在服务器运维与网络安全领域,防火墙规则的准确性直接决定系统防护能力。传统的手...

发布日期: 2025-04-29 19:25:40
在互联网服务的日常运维中,网站可用性如同数字世界的脉搏。一套基于Python Requests库...

发布日期: 2025-05-23 12:41:52
在互联网公司的机房走廊里,闪烁的服务器指示灯像夜空中的繁星,每台Linux服务器都...
发布日期: 2025-07-21 09:00:01
在远程服务器操作、自动化脚本执行等场景中,SSH密钥对承担着身份认证的核心功能。...
发布日期: 2025-08-17 11:42:01
在Python生态中,Web框架的选择一直充满多样性。从传统的Django、Flask到新兴的FastAPI,开...
发布日期: 2025-06-27 14:18:01
在分布式系统开发过程中,JWT令牌验证模块的调试往往需要搭建完整的授权服务体系。...
发布日期: 2025-05-02 16:05:02
在数字化服务场景中,系统崩溃如同高速行驶中的爆胎,任何延误处理都可能引发连锁...

发布日期: 2025-05-14 11:13:04
操作系统后台运行的数百个服务进程中,某个异常进程突然耗尽系统资源时,运维人员...

发布日期: 2025-06-18 13:06:02
某电商平台的促销活动服务器在凌晨三点突然宕机,监控系统在15秒内自动拉起备用节...

发布日期: 2025-04-03 11:31:47
在数据交换需求频繁的办公场景中,FTP协议仍是跨平台传输的可靠选择。Python生态圈提...

发布日期: 2025-03-28 19:13:38
在分布式系统与微服务架构普及的今天,运维团队常面临操作追溯困难、故障定位效率...

发布日期: 2025-04-12 17:51:30
在Windows系统维护过程中,某些关键进程的持续运行直接影响业务连续性。传统任务计划...

发布日期: 2025-03-26 15:37:47
在服务器运维过程中,日志文件膨胀一直是高频痛点。一台中型服务器每月产生的日志...
发布日期: 2025-07-26 18:24:02
在即时通讯工具广泛应用的今天,理解底层通信原理对开发者尤为重要。基于TCP协议搭...
发布日期: 2025-08-16 19:06:02
每当Windows系统开机时间超过30秒,任务管理器里那些陌生进程就容易让人血压升高。手...

发布日期: 2025-03-26 14:51:32
凌晨三点的机房警报骤然响起,运维工程师在刺耳蜂鸣声中惊醒。这样的场景正在被新...

发布日期: 2025-04-06 15:04:52
在分布式架构普及的当下,一台服务器宕机、一个接口超时、一次流量突增,都可能涉...
发布日期: 2025-08-02 09:06:01
分布式系统运维领域存在一个经典难题:当系统涉及数百个服务节点时,如何准确掌握...
发布日期: 2025-07-15 16:30:02
在服务器运维与分布式系统管理中,资源利用率监控一直是保障业务稳定性的核心需求...

发布日期: 2025-05-31 15:03:01
机房服务器突然宕机导致业务中断?远程摄像头意外离线影响监控系统运行?工业设备...
发布日期: 2025-06-27 19:12:01
局域网即时通讯工具在无外网环境或对数据安全要求较高的场景中具备实用价值。一套...