
发布日期: 2025-07-08 13:36:02
全球数字化进程加速背景下,跨语言信息处理需求呈爆发式增长。某科技团队近期推出...

发布日期: 2025-05-08 13:12:23
当面对大段文字需要快速提炼核心信息时,一款基于Python Tkinter开发的本地化关键词提...

发布日期: 2025-05-14 09:10:56
在信息爆炸的数字化时代,文字工作者常面临海量文本的分析需求。一款高效的词频统...

发布日期: 2025-03-26 11:11:01
许多程序员在日常工作中常遇到代码版本比对的需求,开源社区的文本对比工具虽功能...

发布日期: 2025-05-26 18:12:01
文本自动摘要技术为信息处理提供了高效解决方案。基于Python的NLTK库实现的简易摘要工...
发布日期: 2025-07-05 15:24:01
打开电脑发现两份文档内容高度雷同,手动核对却要花费两小时——这种场景在论文查...
发布日期: 2025-06-25 10:12:01
在信息爆炸的数字化时代,如何从海量文本中快速定位关键内容,成为程序员、数据分...

发布日期: 2025-06-11 17:39:02
清晨七点,摄影工作室的硬盘里堆积着1200张航拍素材,其中37%的照片因设备抖动产生角...
发布日期: 2025-06-16 19:18:01
在数字化办公与日常沟通场景中,文字输入的准确性直接影响信息传递效率。一款名为...

发布日期: 2025-04-14 18:02:21
数据安全已成为数字时代的核心议题。无论是个人隐私保护还是企业级信息传输,加密...
发布日期: 2025-07-25 18:36:01
日常工作中,经常遇到需要整理文本的场景。程序员排查日志时面对上千行信息,作家...
发布日期: 2025-07-19 09:00:02
数字时代催生了海量文档处理需求,PDF文本内容提取器正成为跨行业工作者的效率加速...

发布日期: 2025-05-02 15:39:52
海量信息轰炸的时代,文字背后的情绪密码往往决定着商业决策的走向。一款名为Sen...

发布日期: 2025-06-10 12:48:01
互联网行业每天处理海量文本数据时,开发运维团队常面临敏感信息泄露风险。某安全...
发布日期: 2025-06-14 16:00:01
在数字办公场景中,HTML格式的邮件正文因其排版灵活、视觉丰富等特点,常被用于营销...

发布日期: 2025-04-24 12:35:04
在全球化的商业与文化交流中,语言差异常成为信息传递的障碍。传统翻译工具依赖人...
发布日期: 2025-07-12 11:18:01
互联网时代的数据抓取需求催生了一批高效工具。针对特定URL的文本提取场景,开发者...

发布日期: 2025-05-15 10:49:37
随着移动支付与数字化场景的普及,二维码已成为连接物理世界与数字空间的重要介质...
发布日期: 2025-06-26 10:12:01
文本转语音技术正逐渐渗透进日常办公场景。谷歌公司推出的gTTS(Google Text-to-Speech)作...

发布日期: 2025-05-23 15:44:43
在全球化协作日益频繁的今天,语言障碍仍是信息互通的主要壁垒。基于API的文本翻译...

发布日期: 2025-05-01 10:13:09
打开手机地图导航时,那个清晰的播报音正在替代传统机械提示音;银行客服热线中,...

发布日期: 2025-08-13 17:45:01
数字时代让图片传播变得触手可及,原创作品的版权保护需求也随之激增。据某摄影论...
发布日期: 2025-06-25 14:36:02
夏夜闷热的书房里,台灯在代码编辑器上投下暖黄光晕。当Python自带的Tkinter库与文本处...

发布日期: 2025-03-26 09:13:09
信息爆炸时代,处理海量文本文件时,肉眼逐行扫描关键词如同大海捞针。专业开发者...

发布日期: 2025-05-26 19:45:33
打开电脑准备整理文档时,常会遇到需要快速抓取关键词的情况。传统的手工记录方式...

发布日期: 2025-04-13 11:56:17
在跨境支付、企业财务对账等场景中,交易备注信息的规范性直接影响着后续数据处理...

发布日期: 2025-04-09 14:54:24
在日常办公或编程开发中,面对海量文本文件时,快速定位关键信息往往让人头疼。传...

发布日期: 2025-04-23 11:25:40
信息爆炸时代催生了海量跨语言文本处理需求。以某跨国科技公司研发部门为例,工程...

发布日期: 2025-04-26 17:58:47
语言障碍始终是跨文化交流中最难攻克的难题之一。当人们尝试用翻译软件逐字输入文...

发布日期: 2025-04-30 19:17:52
三窗格文本对比合并工具逐渐成为开发、写作等场景的必备效率助手。其核心价值在于...

发布日期: 2025-03-24 10:30:19
在信息处理需求日益复杂的场景中,文本内容的高效替换成为提升生产力的关键环节。...
发布日期: 2025-08-16 10:39:01
在信息爆炸的时代,文本数据分析成为挖掘价值的核心手段之一。无论是学术研究、市...

发布日期: 2025-06-12 18:00:02
深夜的写字楼里,某国产美妆品牌市场部正在召开紧急会议。新品面膜上市两周销量低...
发布日期: 2025-05-29 14:42:02
办公桌前的咖啡杯冒着热气,电脑右下角突然弹出一条会议提醒。手指悬在键盘上犹豫...

发布日期: 2025-03-21 13:02:40
在信息处理场景中,文本内容的实时校验需求日益高频。针对跨平台、多窗口场景下的...

发布日期: 2025-05-01 18:18:34
在信息爆炸的数字化时代,文字内容的安全审查需求呈指数级增长。某企业近期推出的...

发布日期: 2025-04-05 19:33:58
黑白棋(Reversi)作为一款经典的棋盘策略游戏,诞生于19世纪末,凭借其规则简单但策...
发布日期: 2025-05-31 18:15:02
在法律实务中,频繁查阅PDF格式的合同、法规文件是日常工作的一部分。纸质文件的电...

发布日期: 2025-03-22 13:56:44
在数字化信息高速流通的当下,文本内容的安全性成为企业、机构乃至个人不可忽视的...
发布日期: 2025-07-16 12:48:01
清晨八点,咖啡机刚发出萃取的轻响,某跨境电商公司的运营主管已经收到系统邮件。...
发布日期: 2025-07-23 14:30:02
窗外的雨滴敲打着键盘,文档里闪烁的光标正等待输入。现代人习惯了在数字世界记录...

发布日期: 2025-04-05 19:51:35
信息爆炸时代,海量文本数据的实时处理需求催生了中文情感词典构建技术的突破性发...

发布日期: 2025-05-14 12:31:44
数据爆炸时代催生了大量文本与表格处理需求。一款名为SmartReporter的智能报告生成工具...
发布日期: 2025-08-04 10:36:01
乱码与数据统计是文本处理领域的两大顽疾。某电商平台曾因编码识别错误导致促销信...
发布日期: 2025-06-30 19:36:01
在数字化办公场景中,PDF文档因其跨平台稳定性成为主流格式,但批量提取文本内容始...

发布日期: 2025-05-28 09:33:01
在代码合并的紧要关头,程序员李明发现两个版本的核心模块存在逻辑冲突。面对满屏...

发布日期: 2025-03-30 15:32:34
在信息爆炸的时代,文本内容的快速迭代成为常态。无论是代码版本的更新、合同条款...

发布日期: 2025-06-03 13:12:02
打开文档瞬间,密密麻麻的文字堆叠在屏幕上。某位作者盯着第三章节皱起眉头——他...

发布日期: 2025-03-29 19:38:07
在信息爆炸的办公场景中,如何快速记录灵感、管理待办事项,成为现代职场人的刚需...

发布日期: 2025-04-15 09:57:56
日常办公或编程开发中,常会遇到批量修改文本的需求。例如程序员需要将某段代码变...
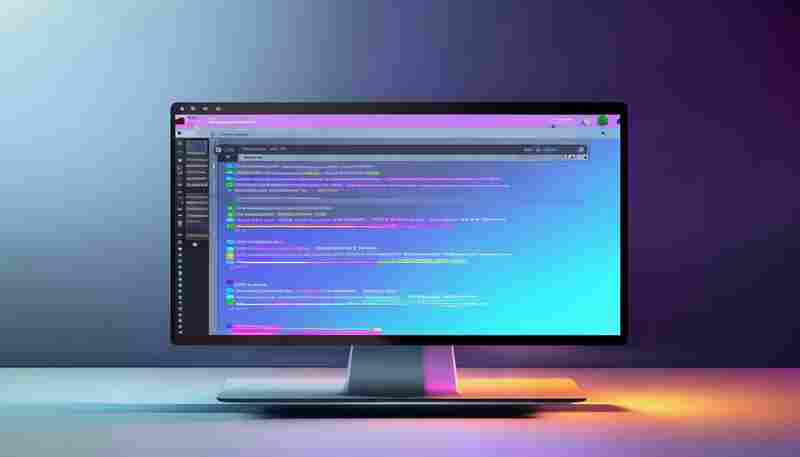
发布日期: 2025-05-19 10:14:46
纸质文档堆满桌面的时代早已过去,但文字工作者依然面临新的挑战——电子文档的版...

发布日期: 2025-05-06 16:05:58
在信息爆炸的数字化时代,PDF文档因其稳定的格式特性成为职场人士与学术研究者最常...

发布日期: 2025-07-04 18:00:02
数码照片整理时,遇到手机误拍导致的方向错误总是令人头疼。传统修图软件需要逐张...
发布日期: 2025-08-07 11:42:02
在Python生态中,pyttsx3作为一款本地化的文本转语音库,因其无需依赖网络服务的特点受...
发布日期: 2025-06-30 18:18:01
在日常办公与编程工作中,文本文件的行数统计常成为棘手问题。某款轻量化工具凭借...

发布日期: 2025-05-26 15:16:15
全球化进程加速催生出大量跨语言需求。企业商务函件需要精准转换,学术论文期待术...

发布日期: 2025-05-23 13:14:05
日常办公中常遇到这样的场景:相机导出的数百张照片命名混乱,项目文档需要统一添...

发布日期: 2025-04-07 15:30:46
在企业数字化转型浪潮中,市场分析、运营复盘等场景对动态报告的需求激增。某互联...

发布日期: 2025-05-15 12:33:02
二维码早已渗透日常生活的每个角落。从商场促销海报到街边煎饼摊的收款码,这种由...
发布日期: 2025-07-20 19:36:01
在数据存储与传输场景中,压缩工具如同数字世界的真空压缩袋。GNU开发的gzip工具自...