发布日期: 2025-04-10 14:03:02
纸质单词本逐渐被电子工具替代的当下,一款名为「FlashMemo」的轻量化记忆卡片系统,...

发布日期: 2025-04-03 18:00:47
在数字化办公场景中,操作系统的合法激活状态直接影响软件生态的稳定性。未激活的...
发布日期: 2025-05-29 14:48:02
当电脑突然卡顿或程序频繁崩溃时,多数人都会本能地按下Ctrl+Alt+Del组合键。这个肌肉...

发布日期: 2025-07-10 12:30:01
网络请求批处理在爬虫开发与API调用场景中具有关键作用。当面对需要同时处理上千个...
发布日期: 2025-06-30 15:42:01
快递收发早已成为现代人日常生活的一部分。每到月底查看账单时,总有人对着手机银...

发布日期: 2025-06-10 11:54:01
在服务器运维与程序开发领域,进程意外中断可能导致服务停摆、数据丢失等严重后果...
发布日期: 2025-05-04 16:48:42
点击扫描按钮后的第三秒,系统弹窗突然铺满屏幕:红色警示条显示C盘剩余空间不足...
发布日期: 2025-06-28 10:00:02
在全球化的商业环境中,汇率波动对跨国贸易、投资分析和财务核算的影响日益显著。...
发布日期: 2025-03-22 09:14:21
疫情数据动态地图生成系统是一款基于地理信息技术开发的公共健康管理工具。该平台...

发布日期: 2025-04-04 12:40:58
系统盘剩余空间从30G骤降至6G的红色预警弹窗,往往伴随着电脑风扇的狂转声和程序无...
发布日期: 2025-06-22 17:18:01
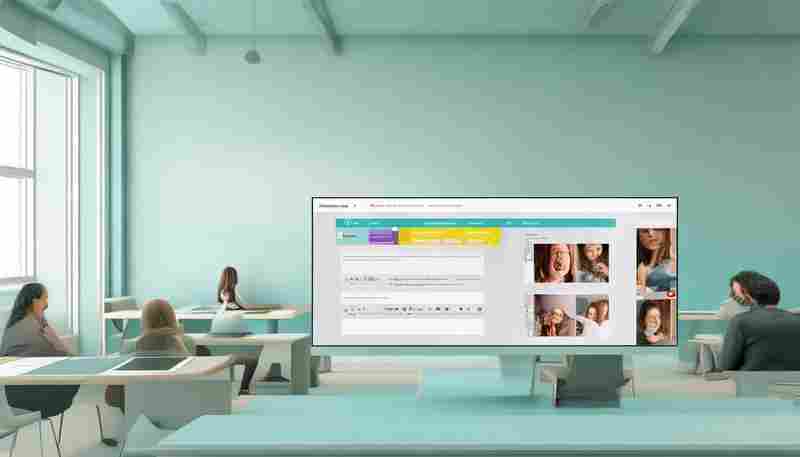
论坛系统开发常让新手望而却步,一套经过验证的教学模板能有效降低学习门槛。本文...

发布日期: 2025-05-17 16:09:22
在现代办公环境中,会议室作为团队协作的核心场景,其使用效率直接影响业务运转。...

发布日期: 2025-05-16 14:34:02
系统日志分析错误自动报警器是IT运维领域的实用型工具,其核心功能在于实时监控服...
发布日期: 2025-03-27 12:20:18
凌晨三点的机房警报声里,某电商网站的系统管理员盯着满屏跳动的数字,手忙脚乱地...

发布日期: 2025-05-22 18:02:22
当C盘飘红成为日常,系统清理工具早已成为装机必备软件。市面上多数清理工具停留在...

发布日期: 2025-03-25 09:29:40
在物流行业高速发展的当下,园区内车辆的调度效率直接影响着整体运营成本与服务质...

发布日期: 2025-05-16 18:01:00
在数据处理领域,PDF报告的自动化生成已成为企业数字化转型的重要环节。某金融科技...
发布日期: 2025-07-07 15:18:01
现代分布式系统中,API接口的鉴权管理直接影响着数据安全与系统稳定性。基于JSON W...

发布日期: 2025-06-18 11:12:01
在Linux和macOS系统的命令行环境中,存在一个被开发者低估的效率工具——timekit。这款...
发布日期: 2025-05-18 11:33:00
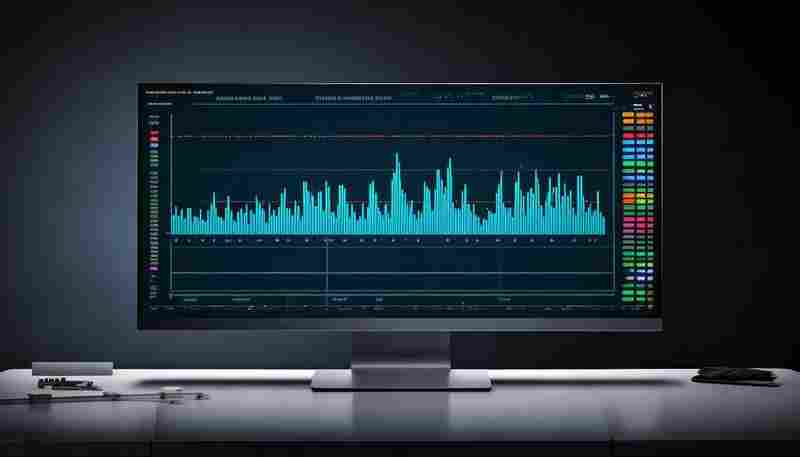
企业机房传来断断续续的警报声,运维人员盯着满屏红色警告束手无策。这种场景在数...

发布日期: 2025-04-24 19:29:09
货架上堆积如山的滞销品与频繁断货的热销商品形成鲜明对比,这种场景在传统库存管...

发布日期: 2025-05-27 11:20:18
在分布式系统监控领域,Prometheus以其灵活的查询语言和高效的时序数据库著称。但当运...

发布日期: 2025-05-14 11:27:22
在局域网环境下搭建即时通讯工具,既能满足团队内部高效沟通需求,又能避免公网传...

发布日期: 2025-05-14 14:40:38
对于中小型企业和个体商户而言,库存管理效率直接影响经营成本与服务质量。一款专...

发布日期: 2025-04-04 15:38:56
现代职场中,频繁的跨部门协作与外部会议常导致时间协调困难。据统计,企业员工平...

发布日期: 2025-05-05 15:40:17
在Windows平台上实现通知弹窗功能,传统方案往往依赖第三方应用或复杂的系统接口调用...

发布日期: 2025-05-12 13:19:50
Windows系统使用超过一年的老用户大多经历过这种场景:C盘空间莫名被蚕食,系统响应...

发布日期: 2025-05-25 16:33:00
在营销、客服或商务沟通领域,邮件模板的使用频率远超想象。但当团队成员需要共同...
发布日期: 2025-05-29 18:42:03
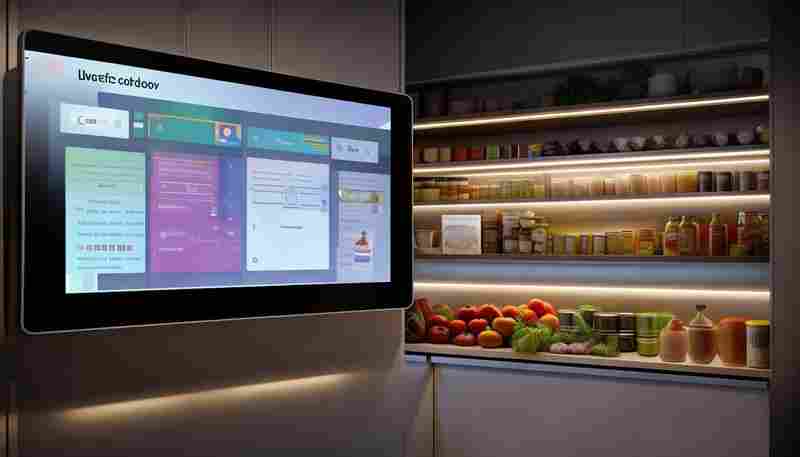
每次大扫除总能翻出几袋过期食品——这大概是每个家庭主妇都经历过的尴尬。厨房角...

发布日期: 2025-04-05 12:26:27
互联网时代的数据采集需求呈现出碎片化与即时化特征。针对中小型业务场景的快速数...

发布日期: 2025-04-26 15:00:02
在数字化业务高速发展的今天,网络流量波动已成为企业运维团队最敏感的神经。一次...

发布日期: 2025-06-05 11:42:02
在计算机运维和故障排查过程中,获取准确的系统信息如同医生需要患者的体检报告。...

发布日期: 2025-04-12 10:06:47
科研工作者对期刊影响因子的依赖早已成为行业共识。这个数值不仅是衡量期刊学术影...

发布日期: 2025-04-18 15:19:52
在垃圾分类逐渐成为城市生活标配的当下,某科技团队自主研发的智能垃圾分类记录分...
发布日期: 2025-04-06 18:39:36
在硬件性能监控领域,风扇转速的动态变化直接关联设备的散热效率与运行稳定性。针...
发布日期: 2025-05-21 15:19:05
在分布式系统与云计算环境中,服务器规模动辄成百上千台。传统密码登录方式不仅效...

发布日期: 2025-05-07 09:20:39
在日常编程中,三角函数的使用频率极高,无论是图形处理还是物理引擎开发,都离不...

发布日期: 2025-05-02 19:05:06
在移动办公与娱乐需求激增的今天,电子设备的续航能力直接影响使用体验。一款精准...

发布日期: 2025-03-23 13:40:01
电脑突然卡成PPT?软件闪退找不到原因?后台进程偷偷吃掉大半内存?一套轻量级系统...

发布日期: 2025-04-01 16:14:57
在Windows任务管理器偶尔力不从心的场景下,第三方进程监控工具逐渐成为技术人员的标...
发布日期: 2025-07-10 14:54:02
日常运维或程序开发过程中,系统进程监控工具如同医生的听诊器。针对不同维度的资...

发布日期: 2025-03-24 12:32:02
在Windows系统使用过程中,几乎每位用户都遭遇过文件关联混乱的困扰。当电脑里安装了...

发布日期: 2025-05-09 12:10:37
清晨六点的便利店监控画面里,货架上的商品突然发生位移。这种看似平常的监控异常...
发布日期: 2025-05-14 14:01:19
互联网时代,数据采集已成为市场分析、学术研究等领域的常规操作。在Python生态中,...

发布日期: 2025-03-27 17:22:50
日常使用电脑时,回收站堆积的冗余文件常占据存储空间。对于需要频繁清理文件的用...

发布日期: 2025-03-28 13:18:02
在中小型团队内部,文档共享与知识沉淀常面临效率瓶颈。基于Python Flask框架开发的局...
发布日期: 2025-05-15 14:56:06
传统文件管理依赖文件夹树形结构,效率瓶颈日益明显。某技术团队开发的本地文件管...

发布日期: 2025-04-24 14:43:38
现代人使用电脑时,常常需要同时处理多个窗口。当用户正在整理数据表格,突然需要...
发布日期: 2025-04-08 16:18:57
在企业日常运营中,Excel表格承载着大量关键数据,但人工跟踪截止日期、库存阈值或...

发布日期: 2025-04-01 09:42:28
现代人对于饮食的需求越发多元,健康管理、过敏规避、膳食搭配成为日常刚需。面对...

发布日期: 2025-04-02 16:04:18
在日常办公与设计工作中,字体管理常被忽视,却直接影响效率。当系统累积上百款字...

发布日期: 2025-05-21 15:12:00
电脑屏幕右下角突然弹出的红色警告图标,总能让正在赶工的用户心头一紧。这种突如...

发布日期: 2025-06-20 12:24:01
文件存储系统中重复数据如同沙粒般顽固。传统的人工比对方法耗时耗力,基于文件名...
发布日期: 2025-07-13 10:36:01
很多用户都经历过这样的场景:U盘可用空间显示不足,却找不到占容量的文件;系统文...

发布日期: 2025-06-12 15:18:02
在系统服务开发与运维领域,配置文件的管理常因格式复杂、维护成本高而成为痛点。...

发布日期: 2025-06-12 09:06:01
厨房操作台的笔记本堆满手写菜谱,手机相册里混杂着截图与文档,微信群聊记录中埋...
发布日期: 2025-03-28 10:12:54
网络流量监控是维护系统稳定性的核心环节。一款优秀的实时监控工具,不仅要能捕捉...
发布日期: 2025-05-19 15:29:56
工具背景与痛点 Windows系统自带的还原点功能常因缺乏有效管理导致存储空间被历史备...
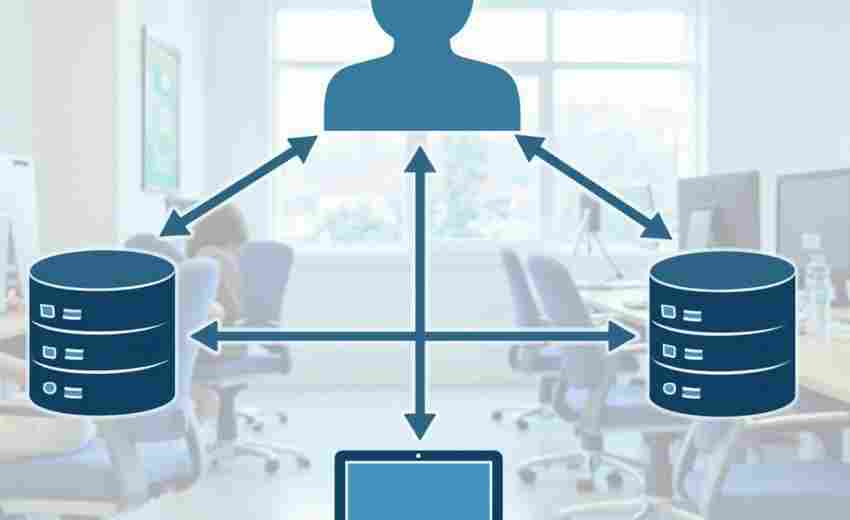
发布日期: 2025-04-15 15:38:50
在分布式系统架构中,服务器配置管理如同精密仪器的校准过程。某金融科技公司的运...
发布日期: 2025-05-29 15:24:01
在信息爆炸的时代,个人博客依然是思想沉淀的最佳载体。对于开发者而言,采用Fla...