
发布日期: 2025-06-03 16:18:01
设计师发来的海报尺寸是30002000像素,印刷厂却要求提供厘米单位参数",这样的场景在...

发布日期: 2025-05-04 11:20:17
在数字工具快速迭代的今天,一款专注于坐标系绘图的轻量化软件正成为数学爱好者、...

发布日期: 2025-06-11 12:39:02
现代计算机视觉领域,运动检测技术广泛应用于安防监控、智能家居、工业检测等场景...

发布日期: 2025-08-06 09:24:02
在短视频剪辑、网课录制或是会议记录的场景中,不同设备对视频格式的兼容性问题常...
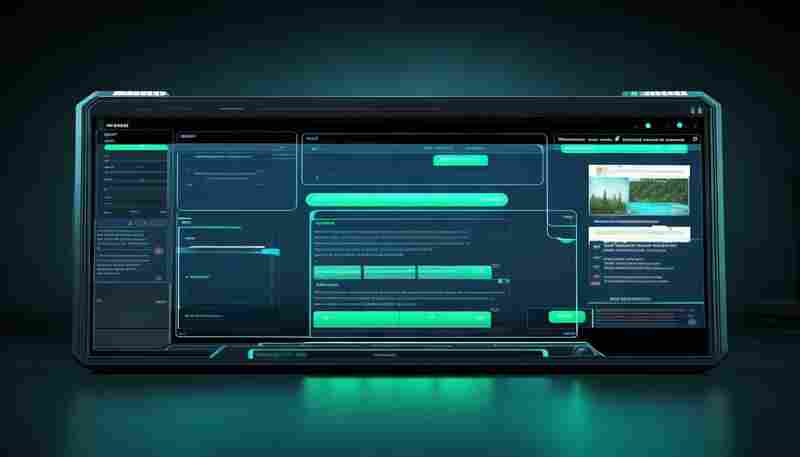
发布日期: 2025-06-05 10:12:02
在信息爆炸的互联网时代,快速提炼网页核心内容的需求日益增长。Python凭借其丰富的...

发布日期: 2025-05-14 10:37:05
现代生活节奏加快,日程管理成为刚需。一款轻量级的日历工具,若能兼顾简洁界面与...

发布日期: 2025-04-28 17:36:30
在线画廊图片管理新方案:轻量化元数据编辑工具解析 对于摄影师、画廊管理者或内容...

发布日期: 2025-06-02 13:48:01
某电商平台凌晨突发服务器宕机,后台订单数据停滞近半小时才被发现。技术团队排查...

发布日期: 2025-08-01 16:12:02
办公电脑里堆积了上百个版本的方案文档,移动硬盘中存着三年来的摄影素材——这种...

发布日期: 2025-04-15 17:23:10
在快节奏的工作场景中,开发人员常需要快速记录灵感或临时备忘。基于Python的PyAudi...

发布日期: 2025-04-10 19:55:20
在办公场景高频使用文字识别工具的当下,某国产独立开发者推出的"轻快OCR"引发关注...
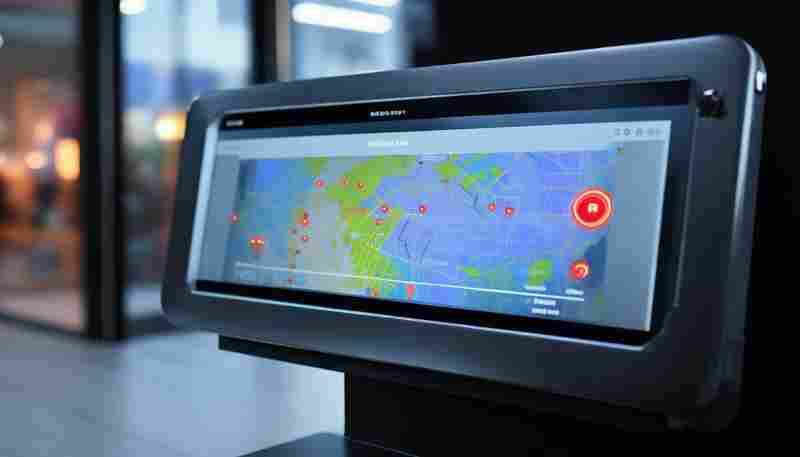
发布日期: 2025-06-16 15:24:01
在信息爆炸的数字化时代,网页内容更新频率以秒计算,企业、媒体、个人用户对特定...

发布日期: 2025-03-29 14:21:22
在日常办公中,Excel数据处理是高频需求,但面对海量数据时,重复的手动操作往往消...

发布日期: 2025-06-19 10:36:02
![程序员在电脑前使用Markdown工具] 工具定位与设计哲学 这款面向新手的Markdown生成器摒...

发布日期: 2025-06-06 09:42:02
互联网应用中验证码系统承担着人机识别的重要功能。一款基于Python开发的轻量化验证...

发布日期: 2025-06-08 09:36:02
在快节奏的生活中,许多人习惯用手机或电脑记录日程,但市面上复杂的日历软件往往...

发布日期: 2025-05-20 15:36:35
鼠标点击柱状图顶端橙色区块,页面右侧立即弹出四月华北地区销售额明细。拖动时间...

发布日期: 2025-04-10 14:10:21
Windows注册表如同操作系统的神经中枢,存储着软硬件配置的核心数据。随着使用时间增...
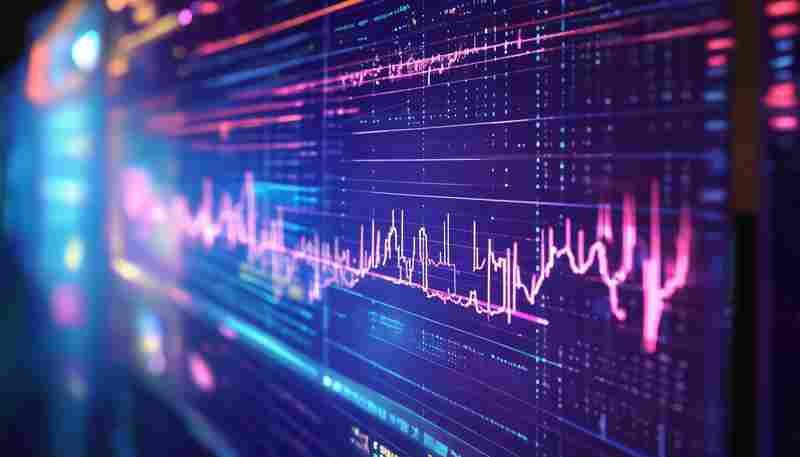
发布日期: 2025-05-05 19:23:13
对于投资者和数据分析师而言,实时股票价格是制定决策的核心依据。手动记录数据效...
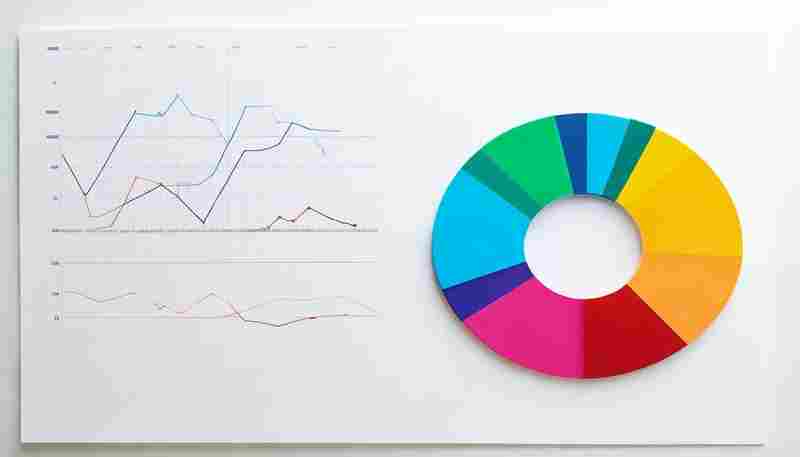
发布日期: 2025-04-27 16:52:14
鼠标在Excel表格密密麻麻的数字间滑动,会议室墙上的投影仪发出低沉的嗡鸣。市场部...

发布日期: 2025-04-09 15:49:05
文献引用标号功能作为学术写作的刚需,长期困扰着大量研究者。传统手动编号方式不...
发布日期: 2025-07-21 09:06:01
网页正文内容自动翻译工具近年来逐渐成为跨语言信息获取的核心载体。这类工具通过...

发布日期: 2025-06-11 18:57:02
当代码运行在自制的虚拟环境中,屏幕突然跳出预期的运算结果时,实验室的日光灯管...
发布日期: 2025-07-16 11:12:02
打开电脑收藏夹的瞬间,看到2015年收藏的旅游攻略和上周刚存的代码文档混在一起,这...

发布日期: 2025-06-22 17:42:02
在数字化信息爆炸的时代,网站内容的安全性成为许多企业及个人用户的隐忧。服务器...

发布日期: 2025-06-10 09:00:01
在数字化协作场景中,轻量化通信工具始终存在需求。基于Linux/macOS系统的netcat工具(...
发布日期: 2025-07-11 11:30:02
简易Web爬虫工具:快速抓取指定URL内容 在信息爆炸的时代,高效获取目标数据成为许多...

发布日期: 2025-04-05 19:16:07
电脑桌面上突然弹出的错误提示总在关键时刻消失?游戏通关的高光时刻总想分享给队...

发布日期: 2025-05-21 11:25:39
在办公文件共享场景中,经常遇到跨设备传输受阻的尴尬。某款轻量级FTP工具近期引发...
发布日期: 2025-08-05 09:42:01
提起像素艺术,许多人脑海中会浮现出早期电子游戏的粗糙画面。正是这种由方块堆砌...
发布日期: 2025-07-07 11:00:02
很多开发者都有过这样的经历:调试接口时收到XML报文却需要转成JSON格式,手动修改不...
发布日期: 2025-05-19 18:25:49
在信息碎片化时代,数据呈现能力直接影响决策效率。一款零代码操作的可视化工具正...

发布日期: 2025-04-21 16:06:22
互联网时代,数据采集已成为技术人员的必修课。在众多网页解析工具中,BeautifulSou...

发布日期: 2025-04-27 10:37:28
在项目调试或临时文件共享的场景中,开发人员常遇到需要快速启动HTTP服务器的需求。...

发布日期: 2025-04-23 10:35:44
互联网时代,数据成为驱动决策的核心要素。面对海量网页信息,传统复制粘贴或简单...

发布日期: 2025-05-15 17:47:44
互联网信息量呈指数级增长背景下,数据抓取工具正经历技术迭代。基于多线程架构的...
发布日期: 2025-07-29 18:30:01
在数据分析或日常办公场景中,CSV文件因其结构简洁、兼容性强的特点,成为高频使用...

发布日期: 2025-05-14 14:37:02
在信息爆炸的时代,快速从海量文档中提取关键内容成为刚需。一款名为 QuickSearcher 的...

发布日期: 2025-04-09 14:15:20
互联网时代的数据抓取如同现代淘金热,XPath解析工具正成为从业者必备的挖掘装备。...

发布日期: 2025-04-28 19:55:40
在数据驱动的时代,网页爬虫技术已成为信息采集的核心手段之一。随着网站反爬机制...
发布日期: 2025-07-06 09:06:01
互联网每天产生约328亿GB数据,内容抓取技术成为企业及个人获取信息的重要途径。当...

发布日期: 2025-05-19 15:40:41
互联网每天产生约328万TB的数据,如何从海量信息中精准捕获目标内容并转化为可用资...

发布日期: 2025-04-23 16:32:37
在数据采集领域,定时爬虫的可靠性与灵活性直接影响业务效率。针对需要周期性执行...

发布日期: 2025-03-27 19:24:01
在信息爆炸的时代,Markdown凭借其轻量化、易读易写的特性,成为程序员、内容创作者...
发布日期: 2025-07-31 19:42:01
互联网视频资源日益丰富,但受限于平台规则,用户常面临「在线观看流畅,本地保存...

发布日期: 2025-04-27 10:44:45
数学方程的求解历来是学生、教师乃至科研工作者绕不开的基础技能。其中,一元二次...
发布日期: 2025-08-05 16:42:02
浏览器页面加载出数千行代码时,工程师常要面对海量嵌套的HTML标签。某电商平台测试...

发布日期: 2025-04-16 12:10:11
在快节奏的现代办公场景中,邮件依然是商务沟通的重要载体。面对频繁的客户联络、...
发布日期: 2025-05-31 15:09:01
热搜榜单作为社交媒体舆情的风向标,在品牌营销、学术研究等领域有着重要参考价值...

发布日期: 2025-05-12 14:35:34
打字速度测试工具早已突破专业领域的局限,逐渐成为大众提升效率的日常助手。市面...
发布日期: 2025-07-26 15:18:02
日常工作和生活中,快速记录信息的需求无处不在。传统录音工具虽然能留存声音,但...
发布日期: 2025-05-05 19:33:55
局域网文件传输工具是一款基于Socket通信协议开发的轻量级文件传输解决方案。该工具...

发布日期: 2025-03-23 10:23:18
在数字设计领域,色彩搭配是决定作品成败的关键因素之一。从海量素材中精准提取主...
发布日期: 2025-07-15 17:24:02
机房里此起彼伏的服务器警报声突然安静下来,运维组长王工却皱起眉头。他熟练地打...
发布日期: 2025-05-05 16:08:43
互联网内容的动态变化特性,使得网页内容的追踪与比对成为许多用户刚需。无论是企...

发布日期: 2025-05-18 18:00:37
阳光斜斜洒在咖啡杯旁,指尖在手机屏幕上轻快滑动。这款名为"SketchMate"的画板应用图...
发布日期: 2025-05-11 10:22:57
在数据抓取领域,Scrapy框架凭借其高效的异步处理能力和模块化设计,成为开发者构建...
发布日期: 2025-07-17 10:18:01
在激烈的市场竞争中,价格策略往往成为企业突围的关键。一款基于爬虫技术的竞品价...

发布日期: 2025-04-27 15:23:07
网页标题作为页面内容的核心概括,其精准抓取能力直接影响着数据采集效率。本文介...

发布日期: 2025-05-06 15:44:29
天气数据在农业种植、物流运输、户外活动等领域具有重要参考价值。传统人工查询方...