
发布日期: 2025-03-21 12:27:01
数字时代产生的日志数据呈现指数级增长趋势,某电商平台单日产生的服务器日志就超...

发布日期: 2025-06-13 17:30:01
在日常工作中,海量文本文件的信息检索常令人头疼。传统的关键词搜索效率低下,尤...
发布日期: 2025-05-10 12:24:44
在数字影像呈指数级增长的时代,某摄影工作室的管理员王明曾用三天时间手动修改...
发布日期: 2025-05-24 15:11:33
办公室的硬盘里躺着数千个散乱命名的PDF文档,摄影师的存储卡中堆叠着上百张IMG_00...

发布日期: 2025-05-26 18:08:29
面对电脑中堆积如山的文件,"IMG_20230523_副本(1).jpg""实验数据_终版_V2.xlsx"这类混乱的命...

发布日期: 2025-05-14 09:39:21
在本地开发与调试过程中,开发者常遇到需要快速启动临时服务器的场景。笔者实测多...

发布日期: 2025-07-29 10:42:01
化学分子式作为物质组成的基础表达方式,其规范性与准确性直接影响科研、教育及工...

发布日期: 2025-04-02 15:03:29
深夜的办公室时常出现这样的场景:视频渲染进度条还剩2小时,下载任务卡在97%需要通...

发布日期: 2025-05-16 12:29:11
办公桌上堆叠的文件夹里,上千张照片命名为"DSC001"到"DSC999"。程序员电脑里躺着数十个...

发布日期: 2025-07-22 09:12:02
在数字化运维场景中,日志文件如同系统的"黑匣子",存储着服务器状态、用户行为、...

发布日期: 2025-05-31 11:12:02
输入密码的瞬间,系统弹出红字警告的场面令人窒息。当金融账户被盗刷、社交平台遭...
发布日期: 2025-04-30 19:57:01
在日常工作中,文件管理常成为困扰用户的难题。面对成百上千个命名混乱的文档、图...

发布日期: 2025-03-22 11:06:26
文献标识码的精准识别是学术工作者日常面临的基础挑战。全球每年新增的百万级文献...

发布日期: 2025-05-20 15:58:06
在软件迭代速度日益加快的背景下,测试环节的效率与精准度成为研发团队的核心痛点...
发布日期: 2025-06-10 13:42:01
在数字图像处理领域,批量处理工具往往能带来肉眼可见的效率提升。本文探讨的这款...
发布日期: 2025-07-12 19:18:02
证券从业者常面临海量交易文件命名混乱的问题。某量化团队曾因误用"600519_SH_2023"与...
发布日期: 2025-07-08 16:30:01
面对海量图片素材的整理需求,边框处理常成为困扰创作者的细节难题。单张手动添加...

发布日期: 2025-03-30 14:42:40
在软件开发领域,代码的可读性直接关系到团队协作效率和错误排查速度。近年来,一...

发布日期: 2025-05-13 14:26:15
音视频素材的精细化处理常面临一个痛点:如何根据时间标记快速拆分多音轨文件。某...

发布日期: 2025-04-03 19:33:10
窗外的阳光斜照在显示器上,右手食指因频繁点击开始微微发麻。游戏里的BOSS还剩最后...

发布日期: 2025-05-04 13:07:27
在信息爆炸的时代,二维码以高效、便捷的特性渗透到生活的各个场景。无论是餐厅点...

发布日期: 2025-05-29 13:06:01
备考过程中,时间管理与目标拆解一直是学生群体的痛点。面对多科目复习任务,如何...

发布日期: 2025-05-30 17:54:02
在空气动力学研究领域,实验成本高、周期长的问题长期困扰着工程师与科研人员。传...

发布日期: 2025-03-24 14:17:02
数学表达式解析能力是图形计算器、报表工具等应用的核心模块。某开发者社区近期开...

发布日期: 2025-04-28 14:55:38
在数字工作场景中,键盘快捷键是提升效率的隐形引擎。但系统默认的快捷键组合往往...
发布日期: 2025-06-25 13:00:01
在数据清洗、日志分析、代码审查等场景中,正则表达式(Regular Expression)因其灵活的...
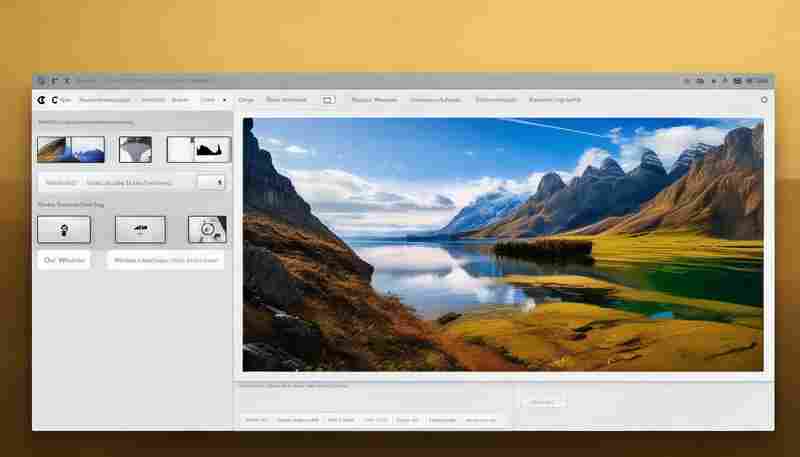
发布日期: 2025-04-27 09:04:49
清晨的阳光斜照进办公室时,行政助理小林正对着相机存储卡里300多张会议照片发愁。...

发布日期: 2025-06-15 12:24:02
在数字文件指数级增长的时代,某款基于规则引擎的批量重命名工具正在悄然改变文件...
发布日期: 2025-07-12 15:48:02
当企业数据库积累数万条时,某电商平台运营团队曾面临数据混乱的困境。电话号码与...
发布日期: 2025-07-07 13:00:01
互联网时代,数据成为决策的核心依据。面对海量网页信息,如何高效提取目标内容?...

发布日期: 2025-05-05 10:50:08
在信息爆炸的时代,如何从海量数据中快速识别关键舆情,成为企业、机构乃至个人用...
发布日期: 2025-06-30 18:36:01
批量文件重命名工具是数字资产管理领域的重要生产力工具。面对数以千计的图片、文...
发布日期: 2025-07-18 18:42:02
在数字化浪潮中,密码安全已成为每个网民必须面对的课题。某款名为CipherForge的密码...
发布日期: 2025-06-13 13:36:01
在信息爆炸的互联网时代,快速获取网页中的图片资源成为许多用户的刚需。无论是设...

发布日期: 2025-04-29 17:34:06
屏幕右下角的系统托盘图标突然闪烁,工程师李明在调试代码时发现某个数值计算存在...

发布日期: 2025-04-10 16:58:10
在日常运维与数据分析中,日志文件常以海量、非结构化的形态出现。面对成百上千行...

发布日期: 2025-06-11 14:33:02
会议记录的时间点标注是提升信息检索效率的关键环节,但在实际工作中常因文本格式...
发布日期: 2025-07-06 11:48:01
运维工程师的日常工作中,系统日志如同人体脉搏般持续跳动。某次服务器突发性能瓶...
发布日期: 2025-04-30 11:50:08
化学符号与分子式的规范性直接影响科研数据的准确性和可重复性。为应对实验记录数...
发布日期: 2025-06-14 09:06:01
在移动互联网时代,某电商运营团队曾因活动页面图片尺寸混乱导致跳失率激增37%,这...

发布日期: 2025-04-24 18:24:25
厨房里的汤锅咕嘟作响,健身房的跑步机节奏均匀,会议室的大屏数字不断跳动——倒...

发布日期: 2025-06-22 12:12:01
在信息处理场景中,批量修改文本内容属于高频操作需求。无论是代码文件中的变量替...

发布日期: 2025-06-05 10:24:02
密码安全始终是网络安全链条中最薄弱的环节之一。面对海量用户数据的管理需求,某...
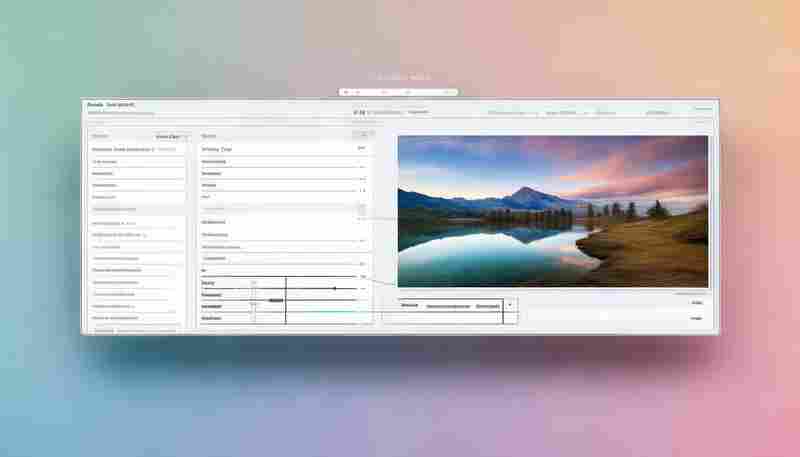
发布日期: 2025-07-30 09:36:01
打开电脑文件夹,二十张产品图横七竖八躺着——电商团队小王盯着屏幕叹气。网店后...
发布日期: 2025-05-03 09:35:07
在日常文件管理中,数字序号的批量添加常让用户陷入繁琐操作。传统方法依赖手动修...
发布日期: 2025-07-25 11:06:01
现代人的电子桌面总是塞满文件与图标,偶尔瞥见角落跳出一行文字:"焦虑的反面是具...
发布日期: 2025-03-30 10:26:14
网络服务器每天产生海量请求日志,运维工程师打开日志文件时,常被密密麻麻的文字...

发布日期: 2025-07-08 16:48:01
工作文档刚敲到一半,突然被领导催进度;追剧到关键时刻,手忙脚乱找遥控器暂停;...
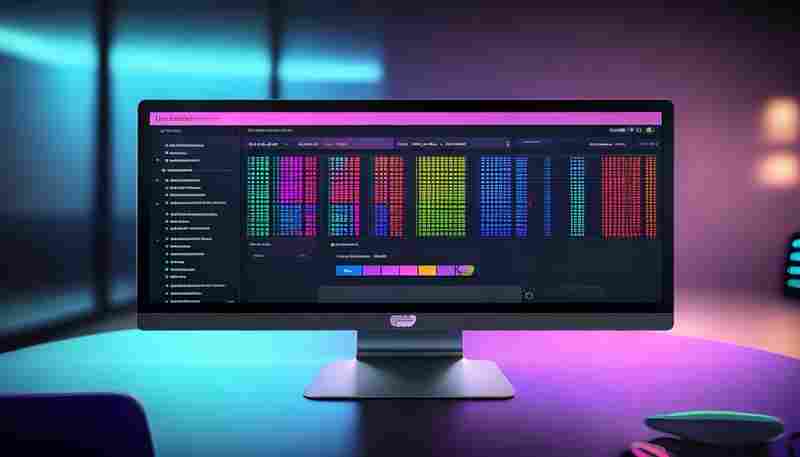
发布日期: 2025-04-26 14:06:39
日常工作中,堆积如山的文件常让人陷入命名混乱的窘境。"财务报告_终版""财务报告...

发布日期: 2025-05-20 16:23:15
随着互联网内容的爆炸式增长,信息审核效率成为平台运营的核心挑战。一款搭载正则...

发布日期: 2025-03-25 11:42:02
互联网时代每天产生近300万个密码,其中23%的密码能被黑客在30秒内破解。一套基于正...
发布日期: 2025-07-31 19:06:02
Windows系统右下角的灰色时间栏常被用户吐槽"存在感过低",某些第三方时钟软件又因界...
发布日期: 2025-06-08 18:48:02
现代人生活节奏快,任务切换频繁。桌面上突然弹出的会议通知,学习时忘记关掉的短...

发布日期: 2025-04-23 12:15:45
在信息爆炸的数字化时代,PDF文件因其稳定的格式特性成为主流文档载体。面对动辄数...

发布日期: 2025-04-16 19:58:17
在运维、数据分析或安全监测领域,日志文件的分析效率直接决定问题排查的速度。传...

发布日期: 2025-06-10 17:06:02
日常工作中处理海量文本时,常会遇到需要精准抓取特定字符模式的场景。某互联网公...

发布日期: 2025-04-16 17:47:42
对于程序员或数据分析师而言,正则表达式(Regex)是处理文本的"瑞士军刀",但编写和...

发布日期: 2025-04-10 12:05:33
电脑右下角突然弹出"系统即将更新"的提示时,正在渲染视频的设计师后背瞬间冒汗;...
发布日期: 2025-03-24 09:38:03
市面上计算器工具琳琅满目,但真正能精准处理科学计算表达式的产品并不多见。某款...

发布日期: 2025-03-30 18:23:37
办公室的玻璃窗上总贴着五颜六色的便利贴,这个场景在数字时代有了全新版本。当电...