发布日期: 2025-05-26 13:24:35
服务器机房内,运维工程师的手机突然弹出红色警报提示。某台核心服务器的内存使用...

发布日期: 2025-04-13 09:04:16
在数据处理领域,效率与规范性始终是核心痛点。近期市场涌现的Excel智能辅助工具,...

发布日期: 2025-03-22 12:56:40
——数据处理效率革命性工具 在办公场景中,Excel多工作簿的合并与拆分是财务、人事...
发布日期: 2025-05-17 12:26:48
运维团队常面临这样的困境:服务器CPU飙高时,网络流量却显示正常;网络突发拥塞时...

发布日期: 2025-04-03 18:07:55
在数据处理与分析领域,Excel因其易用性和广泛兼容性成为最常见的工具之一。面对大...
发布日期: 2025-04-27 11:45:26
离心机作为实验室常规设备,其运行数据的有效管理直接影响着样本处理质量与设备维...

发布日期: 2025-04-15 16:36:55
工作场景中常会遇到这样的困扰:月度销售报表分散在六个省份的Excel文件里,财务部...
发布日期: 2025-04-14 17:47:12
在数据处理领域,Excel的普及性无需多言,但将复杂表格转为通用性更强的CSV格式时,...

发布日期: 2025-04-28 17:47:13
在信息处理效率至上的职场环境中,邮件合并工具逐渐成为办公场景的隐形助手。这种...
发布日期: 2025-05-19 15:44:14
在数字化转型的浪潮中,Excel作为企业数据处理的核心工具,其效率瓶颈逐渐显现。一...

发布日期: 2025-04-15 14:09:54
运维监控领域正经历从被动响应到主动干预的转型期。某数据中心曾因突发的CPU占用激...

发布日期: 2025-04-09 12:32:09
现代人总在寻找充电插座的间隙中度过日常,手机电量低于40%引发的焦虑感不亚于银行...

发布日期: 2025-05-26 11:22:07
在日常的计算机使用过程中,隐藏文件的存在常常带来意想不到的困扰。操作系统或第...

发布日期: 2025-04-25 14:16:08
在科研实验场景中,危险化学品、生物制剂及放射性物质的管理直接关系到人员安全与...

发布日期: 2025-05-21 12:05:31
书法爱好者在临摹字帖时,常面临笔画走向不清晰、运笔细节难捕捉的困扰。基于Ope...

发布日期: 2025-04-28 14:19:48
在数字化管理场景中,系统运行数据的实时监控与分析直接影响运维效率。传统人工统...

发布日期: 2025-05-25 16:29:24
在数字音乐时代,歌单逐渐成为用户存储音乐品味的重要载体。网易云音乐凭借其丰富...

发布日期: 2025-05-19 13:53:20
数据整合是现代办公场景中常见的需求。当多个部门分别提交销售报表、财务数据或时...

发布日期: 2025-04-13 10:51:45
在数字信息交互过程中,文件编码与解码如同一种无声的语言翻译。Base64作为广泛使用...

发布日期: 2025-04-30 14:35:58
实验室设备管理一直是科研机构面临的现实挑战。传统人工登记方式存在记录滞后、数...

发布日期: 2025-04-24 13:39:10
在数据处理领域,CSV与Excel文件的交叉使用极为普遍。业务人员常面临不同格式表格的...
发布日期: 2025-05-27 09:29:24
在数据处理领域,CSV与Excel文件的格式之争长期存在。某互联网公司市场部近期发现,...
发布日期: 2025-04-25 11:28:38
企业级服务器运行时,CPU使用率突然飙升至98%,运维团队却无法快速定位异常进程;公...
发布日期: 2025-05-08 18:27:02
重复性数据录入曾是财务、行政、运营等岗位的日常痛点。某互联网公司市场部员工小...

发布日期: 2025-05-15 09:37:26
在动态网页开发领域,如何高效处理周期性事件的展示一直是技术难点。基于Python Ji...

发布日期: 2025-05-13 18:43:54
打开电脑发现桌面上堆满CSV格式的数据文件,财务部的同事第三次催促报表提交,手动...
发布日期: 2025-05-16 19:01:25
在数据驱动的业务场景中,Excel文件常因格式混乱、重复冗余或结构不统一导致分析效...

发布日期: 2025-04-20 18:35:45
日常数据处理中,Excel表格经常出现数据冗余、格式混乱等问题。传统手工操作效率低...

发布日期: 2025-04-11 10:39:53
在日常数据处理中,SQLite因其轻量便携的特性成为许多开发者的首选数据库。当需要将...
发布日期: 2025-04-25 19:12:01
互联网每天产生数以亿计的网页数据,企业需要实时监控竞品价格,学术研究者需要抓...

发布日期: 2025-03-20 16:13:38
在电商企业的运营部门,张经理每周都会遇到这样的场景:销售系统导出的CSV文件使用...

发布日期: 2025-05-14 10:55:03
在Linux服务器维护过程中,管理员经常需要查看某个进程的资源消耗情况。某次处理服...

发布日期: 2025-04-24 14:07:57
在信息过载的日常工作中,很多人都有过忘记重要事项的经历。基于Python的APScheduler库...

发布日期: 2025-04-18 15:23:22
日常使用电脑时,总会出现程序卡死、后台异常这类恼人的状况。Windows系统自带的任务...
发布日期: 2025-04-22 17:18:24
在金融公司担任数据分析师的李明,每个月都要处理来自全国300家分店的销售数据。手...
发布日期: 2025-05-13 18:33:01
现代人日均面对电子屏幕的时间已超过8小时,工作、娱乐、社交逐渐被数字化生活吞噬...
发布日期: 2025-05-15 09:52:17
在企业数据处理场景中,CSV与Excel文件的交叉比对是高频需求。例如财务对账、库存盘...

发布日期: 2025-05-12 14:28:16
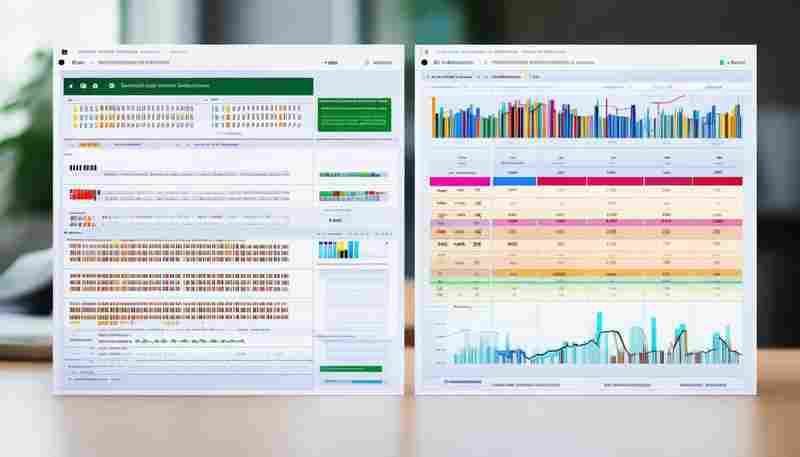
在Linux系统运维领域,传统监控工具常给工程师带来"雾里看花"的困扰。当某天凌晨突然...
发布日期: 2025-06-06 15:06:02
在日常办公场景中,数据格式转换是高频需求。无论是从业务系统中导出的CSV文件,还...

发布日期: 2025-05-31 10:18:02
在数据清洗与分析的场景中,Python开发者时常面临这样的困境:耗费数小时完成数据预...

发布日期: 2025-05-19 17:50:08
在数据科学领域,图形化呈现往往比数字表格更具洞察力。当处理实时变化的传感器数...
发布日期: 2025-04-29 15:39:48
现代职场中,微信承载了海量工作信息。同事群的项目进展、客户群的沟通记录、部门...

发布日期: 2025-04-05 18:58:18
随着企业数据量的快速增长,Excel表格作为最常见的办公文档格式,其数据质量问题日...

发布日期: 2025-03-24 12:01:11
数据库备份恢复是系统运维的基础能力,基于Python生态的PyMySQL库能够快速实现轻量级解...
发布日期: 2025-04-28 12:54:02
在数字化营销时代,社交媒体账号的粉丝数据已成为衡量运营效果的核心指标。传统的...

发布日期: 2025-04-24 09:00:01
在游戏开发领域,Pygame作为一款轻量级Python框架,长期受到2D游戏开发者的青睐。其开...

发布日期: 2025-04-26 11:50:55
在日常办公中,Excel数据整合是许多人绕不开的任务。尤其是当需要处理多个部门、不...
发布日期: 2025-04-26 13:16:39
在某个凌晨三点,某科技公司的安防系统突然触发警报。IT主管通过一串设备接入记录...

发布日期: 2025-04-24 09:29:08
在企业数据处理场景中,Excel表格常因人工录入或系统导出的不规范产生脏数据。传统...

发布日期: 2025-04-22 15:06:34
在数据分析场景中,跨表格匹配信息是高频刚需。某连锁企业市场部曾因手动核对200家...

发布日期: 2025-05-25 11:16:50
当财务人员每月处理上千条交易记录时,数据格式转换往往成为效率瓶颈。某互联网公...

发布日期: 2025-04-21 11:42:23
办公场景中常见的数据表格错乱、格式混杂问题常让人头疼。对于需要处理数千行Exc...

发布日期: 2025-05-16 12:07:43
提到设备管理,实验室管理员常常头疼的问题总绕不开"超时使用"。某高校材料实验室...
发布日期: 2025-04-23 18:12:19
CSV文件与Excel表格的日常较量从未停止。当财务人员需要将银行流水导入报表模板,当...
发布日期: 2025-04-26 10:35:52
互联网时代,RSS订阅依然是获取结构化信息的重要渠道。基于Python生态的BeautifulSoup库,...

发布日期: 2025-05-08 09:26:03
当前企业运营中普遍存在多部门分表存储数据的现象,每月需处理的销售报表、库存清...

发布日期: 2025-04-19 19:11:03
在数据中心轰鸣的服务器阵列间,某运维工程师的手机突然震动。通知栏显示着醒目的...

发布日期: 2025-04-10 12:55:35
在财务部小王连续第三个月加班处理报表的深夜,行政部李主任正为三十个部门的数据...

发布日期: 2025-04-19 16:09:03
在数字化办公场景中,电子邮件系统承载着企业80%以上的正式通信需求。基于IMAP协议的...

发布日期: 2025-05-05 14:10:07
在数据处理需求日益增长的今天,开发者们经常需要寻找既能快速上手又具备足够灵活...
