发布日期: 2025-05-01 11:42:21
在数字内容创作日益普及的今天,摄影师、电商运营和自媒体工作者常面临海量图片处...
发布日期: 2025-05-13 13:42:48
在数字化办公场景中,邮件系统集成始终是个高频需求。当项目需要将邮件发送能力嵌...

发布日期: 2025-04-04 15:03:01
在开发场景中,程序员常面临数百个代码文件混杂的困境。当项目规模超过5万行代码时...
发布日期: 2025-05-01 11:06:35
在信息爆炸的时代,电子文档的数量呈指数级增长。无论是企业内部的合同报告,还是...

发布日期: 2025-04-13 17:12:01
网络安全领域,漏洞扫描是基础设施防护的第一道防线。一款基于Nmap开发的轻量化漏洞...

发布日期: 2025-03-25 19:47:32
在互联网信息爆炸的时代,如何精准抓取目标链接成为数据处理的关键环节。基于正则...

发布日期: 2025-05-12 18:59:31
开发工作中经常遇到需要临时共享本地文件的情况。使用网盘传输效率低,配置专业服...
发布日期: 2025-05-17 16:45:01
在数据处理的日常工作中,Excel文件总会突然出现各种"小脾气":重复记录像杂草般疯长...

发布日期: 2025-05-16 14:30:36
在数字影像处理领域,细微的色彩差异往往直接影响作品的最终呈现效果。某研究团队...

发布日期: 2025-03-24 13:02:37
日常办公场景中,用户常面临杂乱的文件归档难题——项目文件夹里混杂着设计稿、合...

发布日期: 2025-04-18 14:44:11
办公区新装的千兆网络频繁卡顿,家庭影音服务器突然无法流畅播放4K视频,这些场景...

发布日期: 2025-03-28 17:55:14
互联网服务安全体系中,验证码机制长期承担着人机识别的重要职能。随着企业业务流...

发布日期: 2025-03-30 11:12:16
基于TCP/IP协议的Socket通信技术为局域网即时通讯提供了底层支持。在Windows或Linux环境下...

发布日期: 2025-03-22 09:03:12
贪吃蛇作为一款跨越时代的电子游戏,从上世纪70年代诞生至今从未淡出玩家视野。基...

发布日期: 2025-05-11 14:08:42
办公桌前的便利贴总被空调吹得七零八落,手机里的待办清单总被社交软件淹没。对于...

发布日期: 2025-04-29 09:36:02
清晨的闹钟响起,智能窗帘自动拉开,咖啡机开始工作——这一切只需一句语音指令。...

发布日期: 2025-03-31 10:08:38
在局域网场景下,文件传输效率直接影响着团队协作的流畅度。传统FTP或HTTP传输方式虽...

发布日期: 2025-04-23 15:21:08
在科研实验与工程开发中,单位换算常成为打断工作流的"绊脚石"。某开源社区近期发...
发布日期: 2025-04-04 12:08:56
在视频直播、在线会议成为日常的今天,实时摄像头滤镜工具逐渐从娱乐玩具演变为刚...
发布日期: 2025-05-05 15:01:02
在全球化的出行需求下,机票信息查询的效率直接影响旅行体验。一款基于Expedia API开...
发布日期: 2025-04-03 16:06:54
互联网视频资源呈指数级增长,催生出对视频信息结构化处理的技术需求。基于Python生...
发布日期: 2025-05-20 16:12:22
清晨出门前习惯性翻看手机,屏幕上的实时温度、湿度、风力数据早已成为现代人安排...

发布日期: 2025-03-28 13:28:42
在数字艺术领域,一种以几何算法为核心的随机艺术图案生成工具正悄然改变创作方式...

发布日期: 2025-05-05 13:41:49
在移动应用开发与小型项目管理中,SQLite数据库凭借其零配置、轻量化的特性成为首选...

发布日期: 2025-04-23 11:57:53
在大数据技术生态中,PySpark凭借其独特的混合架构逐渐成为企业级数据处理的首选方案...

发布日期: 2025-04-12 13:01:26
一、工具设计原理 端口扫描检测工具的核心逻辑依赖于Socket通信的底层协议交互。通过...

发布日期: 2025-05-18 14:35:50
在互联网账户安全防护体系中,两步验证已成为主流认证方式。当用户登录各类平台时...
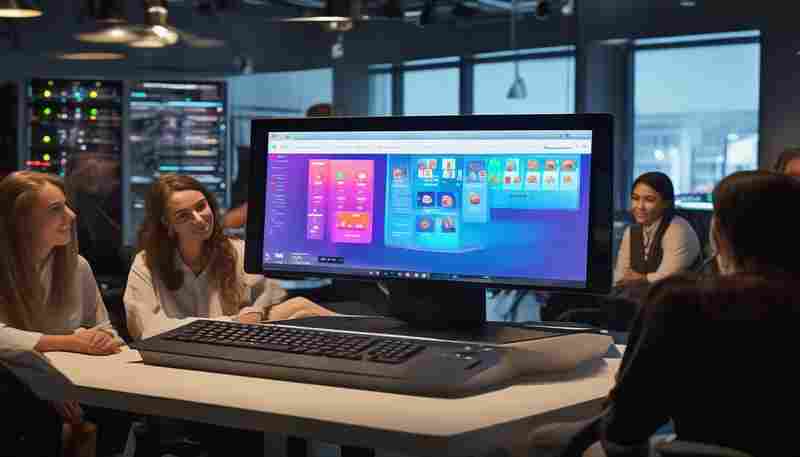
发布日期: 2025-05-18 10:10:43
在信息化办公场景中,内部通讯工具的重要性日益凸显。基于TCP协议的局域网聊天室作...

发布日期: 2025-05-04 19:12:14
运维工程师李明盯着屏幕前滚动的日志流,密密麻麻的文本里夹杂着三个不同系统的报...

发布日期: 2025-03-29 13:10:09
在Python生态中,基于Tkinter开发的简易文本编辑器成为许多开发者接触GUI编程的经典实践...

发布日期: 2025-04-22 10:32:32
在本地开发环境中快速搭建文件共享服务,Python生态中的Flask框架展现出独特优势。其...
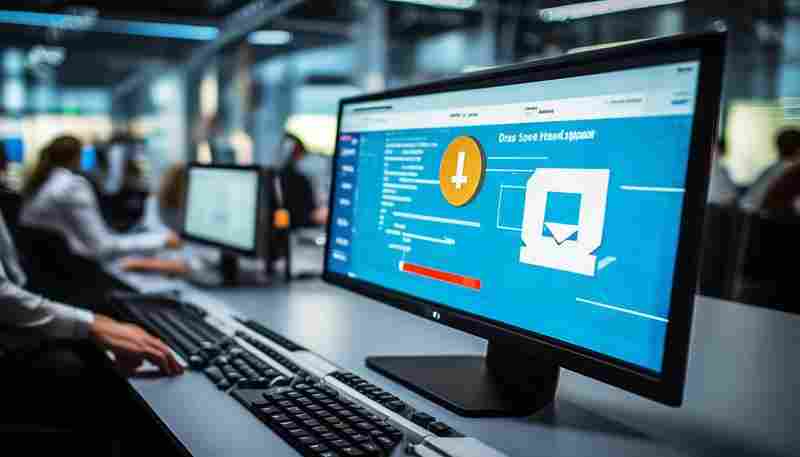
发布日期: 2025-05-25 15:20:59
企业级服务器运维过程中,磁盘空间管理直接影响系统稳定性。某款基于SMTP协议的自动...

发布日期: 2025-04-22 17:14:49
在工业自动化、物联网及智能设备领域,实时传感器数据的传输效率直接影响系统响应...

发布日期: 2025-04-10 11:15:28
命令行窗口弹出黑色背景,光标闪烁的瞬间,许多开发者会本能地敲下`python -m http.se...

发布日期: 2025-03-28 13:18:02
在中小型团队内部,文档共享与知识沉淀常面临效率瓶颈。基于Python Flask框架开发的局...
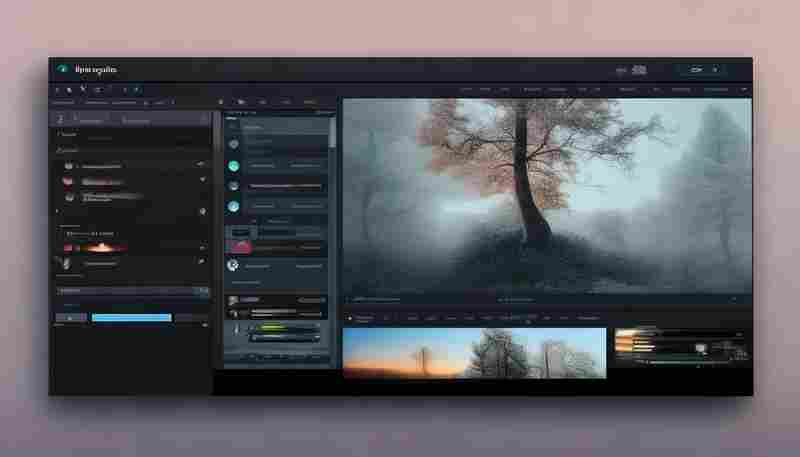
发布日期: 2025-04-28 13:08:23
在数字内容创作日益普及的当下,图像处理工具的选择直接影响着工作效率。一款名为...

发布日期: 2025-03-22 12:43:39
互联网的每一台设备都如同带着隐形坐标的移动信标,地理IP追踪技术正将虚拟世界与...
发布日期: 2025-05-18 14:03:28
在信息爆炸的时代,电脑中堆积的文件常使人陷入无序的焦虑。某次整理工作文档时,...
发布日期: 2025-04-23 12:08:39
窗台上堆着三本翻卷边的通讯录,张伟第三次尝试把客户的新号码挤进密密麻麻的表格...

发布日期: 2025-04-03 09:26:15
海量微博评论中蕴藏着公众情绪的实时波动,人工分析效率低下且容易受主观因素影响...

发布日期: 2025-05-23 16:25:08
清晨的阳光斜照在显示器上,设计师王宇的手指在数位板上快速移动,屏幕里的咖啡杯...

发布日期: 2025-03-27 17:55:01
互联网时代每天产生约3000亿封电子邮件,其中蕴含大量商业情报与用户行为数据。针对...

发布日期: 2025-05-20 13:52:11
在数字办公场景中,存在着大量需要定期截取屏幕画面的需求。传统的手动截图方式效...

发布日期: 2025-04-07 18:04:52
在数据安全威胁日益复杂的背景下,如何精准控制文件访问权限成为企业数字化转型的...

发布日期: 2025-04-24 09:18:23
作为Python自带的GUI工具包,Tkinter长久以来都是新手接触图形界面开发的首选。最近在...

发布日期: 2025-04-15 19:56:27
在数字内容创作领域,视觉素材的获取效率直接影响着工作效率。设计师、自媒体运营...
发布日期: 2025-03-21 11:45:57
在工业控制与数据分析领域,实时监测系统对可视化工具的性能要求日益严苛。基于...

发布日期: 2025-04-18 15:30:36
在信息碎片化时代,越来越多创作者开始寻求自主内容平台。基于Python的Flask框架搭建...

发布日期: 2025-04-06 16:02:03
PIL(Python Imaging Library)作为历史悠久的图像处理工具,在特效生成领域仍有独特价值。...
发布日期: 2025-05-19 19:27:40
开发团队每次提交代码前,总有个穿格子衫的同事默默打开命令行,随着光标闪烁,几...

发布日期: 2025-05-09 16:20:52
在数字化场景愈发丰富的今天,二维码逐渐成为连接物理世界与数字信息的桥梁。对于...

发布日期: 2025-04-19 14:15:18
在数字化转型的浪潮中,企业数据资产的管理逐渐成为核心竞争力。某科技公司的技术...
发布日期: 2025-04-24 13:50:03
在办公室对着电脑屏幕发呆时,突然弹出一个窗口写着“努力不一定被看见,但摸鱼一...
发布日期: 2025-04-04 19:19:47
在信息爆炸的时代,高效获取内容成为刚需。RSS技术凭借其聚合特性,始终是许多用户...
发布日期: 2025-05-13 18:15:01
网络速度直接影响着日常使用体验,无论是视频会议卡顿、游戏延迟飙升,还是文件传...

发布日期: 2025-05-04 14:40:22
在数字化办公场景中,文件传输协议(FTP)的同步需求始终是企业和开发者的刚需。传...

发布日期: 2025-05-24 15:50:46
在数据爆炸的时代,硬盘故障导致的损失屡见不鲜。某位开发者曾因主硬盘突然损坏丢...

发布日期: 2025-05-04 15:30:01
在信息爆炸的时代,研究人员、编辑和数据分析师常面临海量文本处理需求。一款名为...

发布日期: 2025-05-02 16:33:30
日常工作中,用户常需快速查看各类文件,但传统方式需依赖本地软件安装,效率低下...

发布日期: 2025-05-22 15:27:31
在中小型企业或团队协作场景中,文件传输效率直接影响着工作进度。传统FTP服务器配...
