
发布日期: 2025-04-12 10:35:15
在各类活动策划或日常娱乐中,随机抽奖号码的生成需求十分常见。一款支持自定义范...

发布日期: 2025-04-11 13:38:45
对于股民而言,及时获取股价变动是日常刚需。传统的操作往往需要反复打开手机App或...

发布日期: 2025-05-04 12:13:47
在信息爆炸的数字时代,海量文本处理成为各行业从业者的日常挑战。当传统替换功能...

发布日期: 2025-03-29 14:28:27
俄罗斯方块自诞生以来凭借简单规则与强策略性风靡全球,但新手玩家往往难以快速掌...
发布日期: 2025-05-17 10:53:44
在操作系统部署或硬件升级过程中,驱动程序的安装进度往往隐藏在后台黑箱中。某技...

发布日期: 2025-05-25 17:55:37
迷宫,一种古老的空间游戏,如今在数字工具的加持下焕发新生。简易迷宫生成器凭借...
发布日期: 2025-05-18 09:24:01
清晨推开办公室大门,许多人的第一件事不是泡咖啡,而是对着屏幕列下当天任务清单...

发布日期: 2025-03-27 09:25:43
在分布式存储或高并发业务场景中,文件系统的Inode资源管理常成为运维人员的隐性挑...

发布日期: 2025-05-04 19:12:14
运维工程师李明盯着屏幕前滚动的日志流,密密麻麻的文本里夹杂着三个不同系统的报...

发布日期: 2025-05-22 12:20:25
如果你常与文字打交道,对「左边敲代码,右边看效果」的写作模式一定不陌生。近年...

发布日期: 2025-05-13 16:59:51
在信息碎片化时代,文字创作工具的选择直接影响内容产出效率。基于Markdown语法的极...

发布日期: 2025-04-14 10:35:29
通过TCP协议的三次握手机制,端口扫描工具能够快速识别目标主机的网络服务开放情况...

发布日期: 2025-05-27 18:51:42
日志数据作为系统运行状态的"黑匣子",在故障诊断、性能优化等领域具有不可替代的...

发布日期: 2025-04-07 15:45:02
在数据科学领域,数组运算效率直接影响分析工作的成败。NumPy作为Python生态中历史最...

发布日期: 2025-03-29 15:07:39
在大数据时代,定向数据爬取成为企业及研究机构获取结构化信息的重要手段。Scrapy作...

发布日期: 2025-03-29 16:08:08
市面上各类文本编辑器琳琅满目,但真正符合基础办公需求的工具往往隐匿在复杂功能...

发布日期: 2025-05-17 16:34:18
工作电脑前频繁切换窗口查找截图按钮的时代该结束了。区域截图工具正以极简设计颠...

发布日期: 2025-03-22 13:26:54
编程学习者和开发者时常需要快速验证代码片段,传统方式需要反复切换开发环境。一...

发布日期: 2025-03-25 18:14:59
在全球化场景中,多语言文本处理的需求日益迫切。针对需要批量处理文档的场景,基...

发布日期: 2025-04-05 16:39:20
在大数据时代,数据分析的效率与准确性直接影响业务决策的质量。Pandas作为Python生态...

发布日期: 2025-05-06 15:15:48
在信息爆炸的互联网时代,网页表格承载着大量结构化数据。某金融公司分析师曾连续...

发布日期: 2025-04-19 15:26:34
上世纪六十年代,东京某中学的数学课上,老师用粉笔在黑板上演算着复杂的公式。台...

发布日期: 2025-03-27 19:38:20
窗台上那台磨砂质感的计算器被阳光晒得微温,按键缝隙残留着前日咖啡的糖粒。这种...

发布日期: 2025-05-08 13:09:02
在数字化转型的浪潮中,数据收集仍是许多中小企业的痛点。某技术团队近期开源了一...

发布日期: 2025-04-28 10:56:14
互联网时代每天产生海量访问日志数据,如何快速挖掘其中潜在价值成为技术团队面临...

发布日期: 2025-04-26 10:14:18
在数字化办公场景中,PDF文件因格式稳定、兼容性强成为主流文档载体。面对需要提取...
发布日期: 2025-03-27 12:38:08
日常办公或学习场景中,屏幕截图的使用频率远超想象。根据第三方数据平台统计,普...

发布日期: 2025-04-03 17:14:30
在某个阳光斜照的午后,耳机里突然响起的旋律可能瞬间将人拽回十年前的地铁站台。...

发布日期: 2025-05-27 18:48:01
轻触鼠标就能开启创作之旅——这款不足10MB的绘画软件用极简界面隐藏着丰富功能。启...
发布日期: 2025-04-07 13:26:14
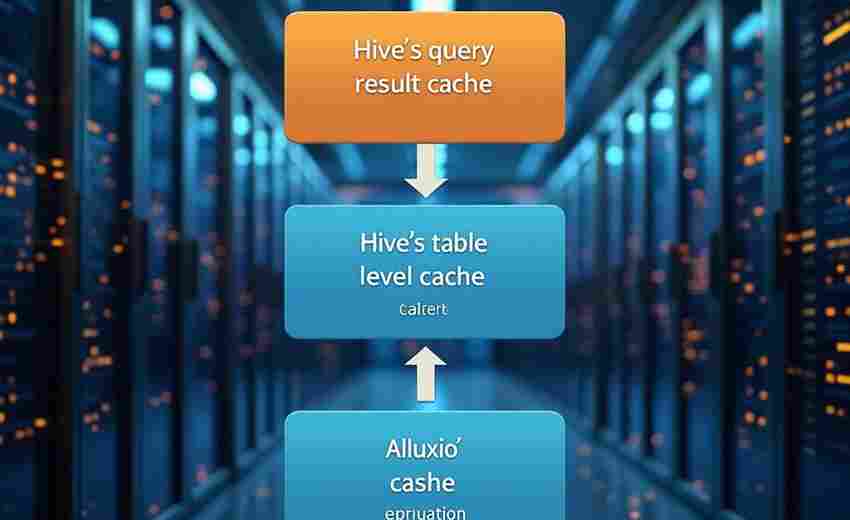
网络通信开发领域存在一个经典练手项目:基于Socket和多线程的TCP聊天室。这个不足...

发布日期: 2025-04-08 10:53:59
在游戏玩家群体中,重复性操作带来的疲劳始终是影响体验的痛点。基于Selenium框架开...

发布日期: 2025-04-08 10:00:32
在数字绘图领域,功能繁多的专业软件常让人望而却步。对于需要快速完成几何图形设...

发布日期: 2025-05-11 12:46:24
打开笔记本电脑的瞬间,十三个浏览器标签页同时亮起,商品价格、企业信息、行业报...

发布日期: 2025-04-04 11:04:50
在跨设备或跨团队协作的场景中,文件传输和同步一直是刚需。传统的手动上传下载方...

发布日期: 2025-03-24 11:48:21
企业级应用系统运行时,日志文件如同程序运行的"心电图",但动辄数十GB的文本数据往...
发布日期: 2025-05-27 10:48:02
互联网时代的信息爆炸让人疲惫。新闻推送、社交媒体、短视频平台轮番争夺注意力,...

发布日期: 2025-04-18 10:06:20
在复杂的局域网环境中,快速识别并管理接入设备是运维工作的重要环节。基于ARP协议...

发布日期: 2025-03-31 12:13:17
办公桌上总躺着几本泛黄的记事本,密密麻麻记满各类网站账号密码。某天发现邮箱被...
发布日期: 2025-04-24 16:12:40
许多职场人都经历过这样的尴尬:带着存有重要资料的U盘奔波于不同设备,某天突然发...

发布日期: 2025-04-18 17:21:01
在数字内容生产领域,图像批处理已成为设计师、电商运营等群体的高频需求。针对固...

发布日期: 2025-03-25 09:58:10
在快节奏的现代生活中,高效管理日程成为刚需。一款主打轻量化的日历提醒程序,凭...

发布日期: 2025-05-22 16:43:15
传统数学练习册的固定题型难以满足差异化学习需求,某教育科技团队近期推出的数学...

发布日期: 2025-06-02 10:06:01
井字棋作为二维空间对抗游戏的入门标杆,其规则简单却暗含策略思维。基于Python标准...
发布日期: 2025-05-15 11:36:03
拖拽式节点创建,一键生成逻辑清晰的流程图——当下市场中涌现的各类绘图工具中,...

发布日期: 2025-05-19 19:45:22
对于需要快速完成基础运算的用户而言,系统自带的计算器往往存在界面复杂、功能冗...

发布日期: 2025-05-08 10:35:10
清晨七点的阳光刚透进窗户,办公桌上的电脑突然自动启动。咖啡机运作的间隙,设计...
发布日期: 2025-05-07 13:05:51
调试嵌入式设备时,工程师的工作台上总少不了一个不起眼却关键的工具——串口数据...

发布日期: 2025-03-27 18:09:18
在碎片化学习与多任务处理场景下,某款国产视频播放器近期引发市场关注。这款支持...
发布日期: 2025-04-20 11:17:17
日常使用网络遇到卡顿时,多数人会本能地掏出手机搜索"网速测试"。其实操作系统自...

发布日期: 2025-04-08 19:06:25
数据查询工具的选择往往令非技术人员望而生畏。针对SQLite数据库与CSV文件设计的轻量...

发布日期: 2025-03-23 09:30:54
在数字设计领域,图形绘制工具的革新始终牵动着创作者神经。近期两款新晋软件——...

发布日期: 2025-06-02 14:00:02
日常运维场景中,技术人员常面临海量日志数据的处理压力。某款基于关键词过滤的日...
发布日期: 2025-05-05 18:21:33
日常系统运维或软件开发中,日志文件的分析效率直接影响问题排查速度。传统文本编...

发布日期: 2025-04-09 13:04:10
午后的办公室充斥着键盘敲击声,技术主管李明第三次在记事本里翻找昨天配置的阿里...

发布日期: 2025-05-23 12:06:01
在每秒产生4.7MB数据的互联网世界,文件传输效率直接影响着数字生活品质。某款采用...
发布日期: 2025-05-12 12:00:17
窗外的阳光穿透纱帘时,桌面右下角悬浮的圆形小窗已悄然显示"32℃ 晴"。这款基于P...

发布日期: 2025-04-01 14:42:32
在信息爆炸的时代,论坛、贴吧等社区平台每天产生海量讨论内容。如何从繁杂的文本...
发布日期: 2025-04-02 14:06:46
上海陆家嘴某私募基金交易员李明习惯性按下F5刷新行情页面,屏幕右下角突然弹出的...
发布日期: 2025-05-01 09:26:39
桌面上散落着387个未整理文件——这是上周清理硬盘时触目惊心的发现。从PDF技术文档...

发布日期: 2025-05-01 17:21:27
清晨的阳光透过咖啡店玻璃窗,灶台上的电子秤突然罢工。厨师老张掏出手机点开蓝色...
