发布日期: 2025-05-13 19:09:00
调试API接口时,开发者常会遇到请求参数错误、响应数据异常等问题。某次处理微信支...

发布日期: 2025-05-03 13:05:45
在全球化协作日益频繁的当下,跨语言沟通成为刚需,但翻译结果的准确性与一致性始...

发布日期: 2025-05-19 09:31:39
随着网络安全威胁日益复杂,SSL证书已成为网站信任体系的核心组件。一张有效的SSL证...

发布日期: 2025-04-26 18:05:56
在全球化进程加速的背景下,翻译记忆库(TMX)作为语言服务行业的重要资产,其精细...

发布日期: 2025-06-28 17:42:02
全球化协作日益频繁,语言障碍却始终困扰着跨地区团队与个人。传统翻译工具往往需...

发布日期: 2025-04-07 13:54:27
网页内容的全球化传播已成为企业及个人开发者的核心需求。但传统翻译工具面对Mar...
发布日期: 2025-05-16 09:54:30
在数字内容爆炸式增长的时代,专业设计师、电商运营和学术研究人员常面临海量图片...
发布日期: 2025-07-31 12:18:02
当我们在浏览外文资料或处理跨国业务时,频繁切换翻译软件的经历几乎成为数字时代...

发布日期: 2025-06-23 10:00:01
在数据中心运维的日常工作中,网络延迟波动如同人体体温变化,细微的异常可能预示...

发布日期: 2025-06-05 13:18:02
数据采集与可视化技术已成为企业决策的重要支撑。针对动态数据实时监测与分析需求...
发布日期: 2025-07-10 15:00:01
在互联网信息爆炸的时代,图片作为内容传播的重要载体,常被用于设计、营销或日常...
发布日期: 2025-07-06 13:36:02
在信息爆炸的时代,网络爬虫逐渐成为获取数据的核心手段之一。传统爬虫工具往往因...
发布日期: 2025-07-13 10:42:02
企业内网突然卡顿,视频会议频繁掉线,远程办公遭遇延迟——这些困扰的背后,往往...

发布日期: 2025-06-13 19:30:02
在网络运维领域,主机存活检测如同心跳监测般重要。某技术团队近期开发的多线程...

发布日期: 2025-05-05 17:10:15
互联网基础设施规模持续扩张,企业网络设备数量呈现指数级增长。某中型金融企业运...

发布日期: 2025-05-24 12:29:58
在全球化的业务场景中,翻译任务日志的规模化处理需求日益增长。面对动辄数万行的...
发布日期: 2025-06-24 15:30:02
在无线网络全面渗透的今天,Wi-Fi信号质量直接影响着家庭娱乐、企业办公甚至工业物...
发布日期: 2025-06-27 19:42:02
在互联网数据爆炸的时代,如何高效获取目标网站的文本信息成为许多从业者的刚需。...

发布日期: 2025-05-23 10:50:28
数字时代,数据安全成为企业生存的底线。网络关键词作为品牌运营、用户洞察的核心...

发布日期: 2025-06-08 11:06:02
多语言商品描述曾是跨境卖家的痛点。传统翻译模式中,人工处理耗时费力,机翻质量...
发布日期: 2025-04-26 16:18:48
凌晨三点的机房警报声响起时,运维工程师老张摸索着关闭手机闹钟。这次不是真实的...

发布日期: 2025-04-05 13:55:36
当我们需要快速获取特定网站公开数据时,基于Python的Requests+BeautifulSoup组合已成为技术...

发布日期: 2025-05-12 09:25:45
阅读外文资料时遭遇"文字孤岛",传统翻译软件需要反复切换窗口的操作痛点,催生了...

发布日期: 2025-03-29 14:14:14
在全球化协作成为常态的软件开发领域,多语言版本迭代常伴随着海量翻译任务。传统...

发布日期: 2025-04-27 17:10:04
打开任意外文网页点击翻译按钮,十秒内即可阅读母语内容——这样的场景早已融入日...

发布日期: 2025-06-04 15:06:01
每当大促来临,京东商品页面的价格波动总让人眼花缭乱。某个程序员在熬夜抢购显卡...

发布日期: 2025-05-06 12:03:01
网络环境中端口安全策略的合规性直接关系着企业核心资产防护能力。当交换机端口出...
发布日期: 2025-07-17 12:42:02
深度学习领域存在一个普遍现象:超过60%的研究人员在模型调试阶段遭遇过结构理解障...
发布日期: 2025-07-01 11:30:01
一台服务器凌晨三点突发硬件故障,值班工程师通过系统自动推送的异常报告,五分钟...

发布日期: 2025-06-22 13:12:01
互联网时代的数据采集离不开网络爬虫技术。对于中小型数据抓取需求,基于深度优先...

发布日期: 2025-03-30 14:21:18
在复杂的网络环境中,QoS(服务质量)策略的配置与生效状态直接影响业务传输的稳定...

发布日期: 2025-04-11 17:24:22
在互联网数据采集场景中,网络爬虫的运行状态直接影响着数据获取效率。针对日志文...

发布日期: 2025-03-25 12:25:53
在信息爆炸的全球化时代,跨语言文本处理成为刚需。无论是开发者查阅技术文档、学...

发布日期: 2025-05-09 19:52:36
在数字经济蓬勃发展的今天,数据抓取工具正在重塑信息获取方式。网络爬虫数据抓取...
发布日期: 2025-07-18 11:12:01
在视频会议频繁卡顿、在线游戏突发延迟的日常场景中,普通用户和运维人员都迫切需...

发布日期: 2025-06-02 12:00:01
互联网信息爆炸式增长背景下,数据工程师每天需要处理百万级原始爬虫数据。某电商...
发布日期: 2025-05-11 10:48:01
厨房常成为跨文化交流的尴尬现场。某位德国主妇对照中文菜谱时,曾误将"茶匙"认作...

发布日期: 2025-05-17 15:47:44
教育行业的数字化转型催生了大量线上运营需求。针对机构在微博、微信公众号、抖音...

发布日期: 2025-04-09 18:15:37
互联网数据采集需求近年持续升温,掌握基础爬虫技术已成为从业者核心技能。本文重...

发布日期: 2025-05-14 09:42:41
企业机房内,运维主管老张盯着屏幕上的折线图皱起眉头。某核心业务系统的入站流量...
发布日期: 2025-04-17 09:27:59
在全球化协作日益频繁的背景下,企业级应用对多语言实时翻译的需求呈现爆发式增长...

发布日期: 2025-04-16 09:57:55
在局域网管理与网络安全维护领域,掌握网络流量可视化技术已成为IT从业者的必备技...

发布日期: 2025-06-18 13:12:02
端口扫描器作为网络安全检测的基础工具,其核心功能是通过向目标主机的特定端口发...

发布日期: 2025-04-27 11:59:40
互联网时代的数据获取方式早已从传统网页解析转向更高效的API接口调用。对于普通开...

发布日期: 2025-06-19 13:06:02
午后两点,电脑右下角突然弹出"网络异常"的红色警示。正在视频会议的财务总监握着...

发布日期: 2025-05-17 10:46:34
在互联网信息爆炸的时代,如何快速获取指定网页的公开数据?这里推荐三款适合新手...
发布日期: 2025-07-08 18:06:02
打开视频会议卡成PPT,下载文件进度条原地踏步,在线游戏突然变成"瞬移大赛"——每...

发布日期: 2025-04-07 16:39:21
在数字化转型加速的今天,某跨国企业IT部门曾因未及时检测分支节点断线,导致业务...

发布日期: 2025-04-06 12:23:50
网络爬虫技术早已渗透到大众生活场景中。无论是电商价格监控还是新闻聚合平台,背...
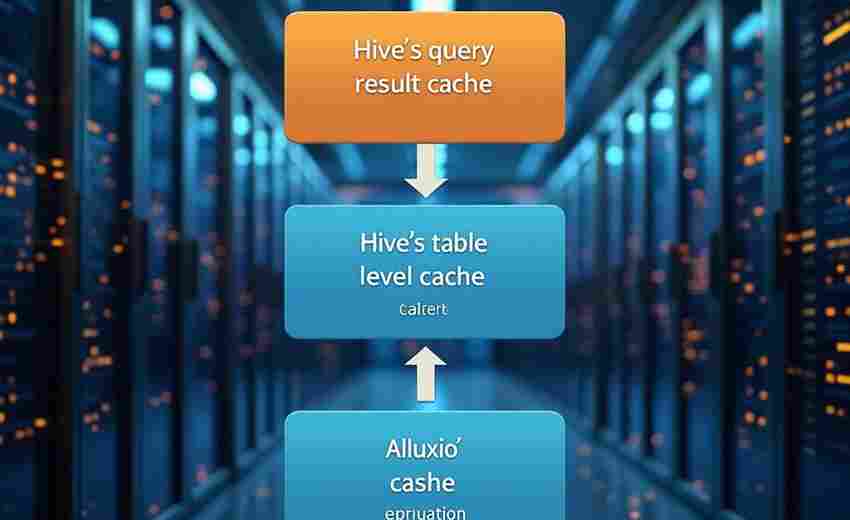
发布日期: 2025-04-07 13:26:14
网络通信开发领域存在一个经典练手项目:基于Socket和多线程的TCP聊天室。这个不足...
发布日期: 2025-03-29 16:29:25
航空出行日益普及,航班延误却成为困扰旅客与航司的痛点。如何快速获取准确的延误...
发布日期: 2025-04-25 10:03:01
在全球协作日益频繁的背景下,处理多语言Excel数据成为许多职场人面临的挑战。例如...

发布日期: 2025-05-05 11:00:56
面对多语言项目开发时,翻译文件常因功能迭代变成臃肿的"文本仓库"。某跨国团队最...
发布日期: 2025-05-05 09:09:01
网络运维工程师的日常工作中,频繁需要验证设备在线状态。传统单机ping测试效率低下...
发布日期: 2025-07-15 17:12:02
互联网时代每天产生超过2.5万亿字节数据,企业级爬虫系统渗透率达83%。但普通用户面...

发布日期: 2025-05-28 09:11:17
网络请求处理能力直接影响着现代应用的响应速度。传统同步阻塞模型在应对高并发场...

发布日期: 2025-03-23 09:11:32
网络端口扫描器如同数字世界的听诊器,能够快速探测主机开放端口及潜在风险。传统...

发布日期: 2025-05-31 14:15:01
网络请求日志分析是网络安全运维中的基础工作,日常处理千兆字节级的日志文件时,...

发布日期: 2025-06-18 09:06:01
互联网上海量图片资源的高效采集,始终是数据处理领域的痛点需求。传统单线程爬虫...

发布日期: 2025-04-13 16:22:11
互联网世界中,一个失效的链接如同路面的坑洞,随时可能让用户失去信任。某技术团...