
发布日期: 2025-05-11 13:04:16
本地数据库管理领域,SQLite凭借其轻量化和零配置特性,成为嵌入式系统和中小型项目...
发布日期: 2025-05-04 18:14:12
在数据处理需求日益增长的今天,轻量级数据库SQLite凭借其零配置、单文件存储的特性...

发布日期: 2025-05-20 17:13:26
数据安全已成为企业运营的生命线。面对频繁的系统升级、硬件故障及网络攻击风险,...
发布日期: 2025-06-06 14:06:01
在移动端应用和嵌入式开发领域,SQLite作为轻量级数据库的扛鼎之作,其性能优化始终...

发布日期: 2025-06-17 11:42:02
在气象信息需求日益增长的当下,天气预报语音播报系统凭借其高效的信息传递能力与...

发布日期: 2025-04-04 12:19:36
随着智能化管理需求增长,二维码门禁系统逐渐取代传统钥匙与IC卡。某科技团队近期...
发布日期: 2025-05-13 11:33:45
在互联网数据抓取领域,Python语言凭借其丰富的生态库占据重要地位。requests作为第三...

发布日期: 2025-06-16 11:12:02
在大数据时代,企业常面临跨数据库查询的难题。例如,财务数据存储在MySQL,用户行...

发布日期: 2025-05-22 12:57:01
在数据安全领域,数据库备份文件的完整性和真实性验证是核心环节。针对SQLite这类轻...
发布日期: 2025-06-13 17:24:01
在数据处理与可视化的日常工作中,Excel始终是不可替代的工具之一。但对于需要批量...

发布日期: 2025-03-30 17:12:18
教室的投影幕布上,一只红色小龟缓缓爬行,身后拖曳出笔直的蓝色线段。当第三个正...

发布日期: 2025-05-01 09:00:02
作为开源多媒体处理领域的核心工具,FFmpeg在音频处理领域展现出的技术深度常令从业...

发布日期: 2025-06-10 14:36:01
凌晨三点,某电商平台服务器突然宕机。值班工程师发现数据库主节点出现物理损坏,...

发布日期: 2025-04-14 14:30:48
在数字化浪潮中,一款名为"墨韵接龙"的本地化工具悄然流行。这个不足200MB的绿色软件...

发布日期: 2025-03-29 16:04:34
在数据量激增的数字化时代,数据库备份的效率与可靠性成为企业运维的核心需求。传...

发布日期: 2025-04-16 17:29:44
在运维工程师的日常工作中,数据库备份环节常面临工具笨重、配置复杂的问题。CLI...

发布日期: 2025-04-12 15:31:25
数独作为一款经典的数字逻辑游戏,长期吸引着全球爱好者。当人工解题遇到瓶颈时,...

发布日期: 2025-05-12 15:11:33
在数据库开发过程中,存储过程的调试长期困扰着开发者。传统的手动调试方式不仅效...
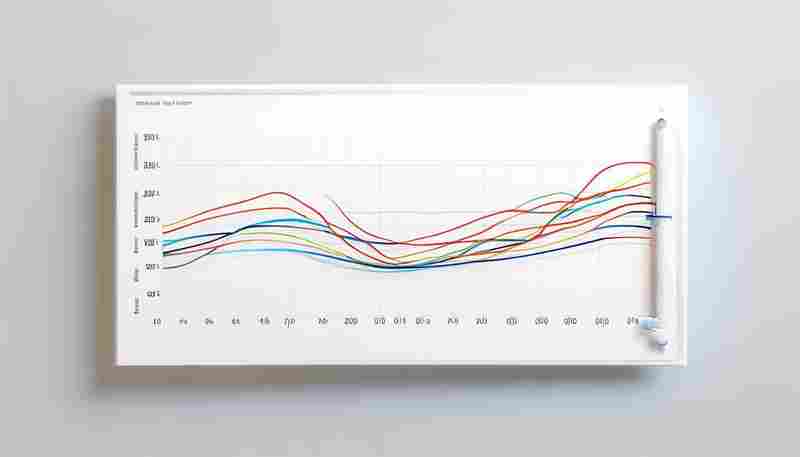
发布日期: 2025-05-23 17:58:28
折线图作为数据可视化领域的经典工具,其应用场景覆盖商业分析到科研领域。在Pyt...
发布日期: 2025-06-11 19:27:01
在信息化办公场景中,开发人员常面临传统表格工具难以满足动态数据管理的困境。某...

发布日期: 2025-04-23 11:36:24
在数字化转型加速的当下,数据已成为企业核心资产。据行业统计,超过60%的中小企业...

发布日期: 2025-05-05 14:10:07
在数据处理需求日益增长的今天,开发者们经常需要寻找既能快速上手又具备足够灵活...

发布日期: 2025-03-25 13:15:23
开发团队常遇到这样的场景:测试环境的表结构更新未同步至生产环境,某次紧急修复...
发布日期: 2025-05-23 19:20:53
在数据库开发过程中,字段命名规范的统一性直接影响着项目的可维护性。某互联网公...

发布日期: 2025-04-16 18:05:26
2023年春季,某电商企业的市场分析团队在周例会上展示了令人惊讶的成果——原本需要...
发布日期: 2025-05-02 11:33:33
在数据管理领域,SQLite凭借其嵌入式、零配置的特性成为开发者首选工具。作为一款无...

发布日期: 2025-06-13 10:42:01
二维码技术近年来渗透到生活的各个场景,从支付到信息传递,几乎无处不在。基于...

发布日期: 2025-06-02 19:39:02
工作邮箱、银行账户、社交平台……当代人手机里躺着近百组账号密码。纸质记录容易...

发布日期: 2025-03-22 11:46:41
当开发者完成Python程序的调试后,总会面临一个现实问题:如何让没有安装Python环境的...

发布日期: 2025-04-28 11:57:01
多数据库表关联合并工具在数据处理领域逐渐成为刚需。随着企业数据源的多样化,技...

发布日期: 2025-04-10 11:44:19
凌晨三点的办公室,屏幕上闪烁的SQL报错信息让张明揉了揉发酸的眼睛。这是他本周第...
发布日期: 2025-04-12 11:46:31
在数据管理领域,高效查看与操作数据库的需求催生了各类专业工具。针对SQLite这种轻...

发布日期: 2025-03-24 11:20:43
在数据密集型的现代办公场景中,PDF格式的标准化报告已成为企业日常运作的刚性需求...
发布日期: 2025-05-10 13:54:26
互联网服务的高并发场景日益普遍,如何准确评估服务器承载能力成为开发者必修课。...
发布日期: 2025-06-21 15:48:02
上世纪五十年代,美国史密森尼航空航天博物馆的档案管理员需要翻阅七层楼高的资料...

发布日期: 2025-05-18 15:33:14
日常工作中,人们常会遇到需要从海量文本中快速定位关键信息的场景。例如市场人员...

发布日期: 2025-05-02 10:00:55
全球化业务拓展过程中,企业常面临多语言数据库的管理难题。不同地区的产品说明、...
发布日期: 2025-05-10 09:33:01
数据安全始终是数据库管理的核心命题。对于SQLite这种轻量级嵌入式数据库,虽然具备...

发布日期: 2025-05-24 16:12:27
在软件开发与运维过程中,数据库表结构管理常因团队协作或环境差异导致版本混乱。...
发布日期: 2025-03-22 11:23:06
当两个数据库环境中的用户表突然出现字段类型冲突,当预发布环境的索引数量与生产...

发布日期: 2025-04-09 10:47:52
运行一段代码就能让屏幕出现一只缓慢爬行的海龟,随着它的移动轨迹留下彩色线条—...
发布日期: 2025-05-17 13:53:17
工作台前的显示器微微发烫,文件夹里躺着三千张待处理的商品图。电商部门的同事发...

发布日期: 2025-05-07 13:56:12
互联网时代的数据交互正以每秒百万次的频率发生,开发者对于API开发工具的要求早已...

发布日期: 2025-05-21 19:19:02
在微服务架构盛行的今天,数据库schema的版本管理已成为开发流程中不可忽视的环节。...
发布日期: 2025-06-11 10:39:01
对于需要本地存储或快速验证数据结构的开发者而言,SQLite命令行工具(CLI)是不可多...

发布日期: 2025-06-05 19:24:02
在移动应用和小型数据库开发领域,SQLite占据着不可替代的地位。当某个查询语句执行...
发布日期: 2025-05-30 12:42:02
作为嵌入式数据库领域的常青树,SQLite凭借其零配置、单文件存储的特性,在移动应用...
发布日期: 2025-06-06 11:00:02
操作界面由深灰与浅蓝双色构成,左侧导航栏的"新建投票"按钮总带着轻微的磨砂质感...

发布日期: 2025-05-20 11:56:32
在数据安全备受重视的今天,很多中小企业仍然依赖传统的手动备份方式。基于Python标...

发布日期: 2025-05-16 12:43:28
检索结果的整理效率直接影响专利分析工作质量。专业人员在处理大规模专利数据时,...

发布日期: 2025-04-05 18:40:33
在数据处理与软件开发中,SQLite以其轻量、嵌入式的特性成为本地数据库的热门选择。...

发布日期: 2025-03-29 10:47:48
在数字经济时代,数据已成为企业的核心资产。面对海量数据的高效管理和灵活应用,...

发布日期: 2025-04-09 18:22:34
音乐发烧友的抽屉里总藏着几盘绝版专辑,电脑硬盘里堆积着未整理的演出录像,手机...

发布日期: 2025-03-22 13:34:01
在数据库开发领域,超过68%的中小型项目选择SQLite作为存储方案。这个轻量级数据库虽...

发布日期: 2025-04-05 17:04:19
电子邮件的自动化发送在商务场景中逐渐成为基础需求。一套基于Python标准库SMTPLIB的轻...

发布日期: 2025-05-13 15:34:03
在异构数据库迁移场景中,SQLite到MySQL的数据同步始终存在技术痛点。本文将深入探讨...

发布日期: 2025-05-12 09:07:52
在开源数据库管理工具领域,SQLiteBrowser以其轻量化特性脱颖而出。这款绿色软件解压即...
发布日期: 2025-06-12 11:18:01
在数据管理领域,CSV格式凭借其通用性和易读性,成为许多开发者和企业常用的数据交...

发布日期: 2025-05-05 12:51:39
在数据驱动的互联网时代,网页爬虫技术已成为企业及开发者获取信息的重要手段。如...

发布日期: 2025-04-26 19:45:53
面对海量问卷调查数据,传统人工统计常伴随效率低、误差率高等痛点。某款基于CSV格...
