
发布日期: 2025-06-18 16:54:02
网络服务探测作为网络安全评估与运维的核心环节,常面临效率瓶颈。传统单线程探测...

发布日期: 2025-07-20 09:06:01
当前电商市场存在商品价格波动频繁的现象,部分消费者反馈某品牌智能手表在京东平...

发布日期: 2025-05-03 13:09:21
网络数据捕获后的解析工作常令工程师头疼。当Wireshark抓取到加密流量或非常见协议数...
发布日期: 2025-04-30 14:28:49
开发者的工作台上,总少不了一款趁手的接口调试工具。这类工具如同程序员与服务器...
发布日期: 2025-03-23 12:47:55
桌面计算器作为数字工具中的经典品类,始终保持着不可替代的实用价值。某款新近推...
发布日期: 2025-05-18 09:34:47
互联网时代,文件下载需求呈现爆发式增长。传统单线程下载工具在面对高清影视资源...

发布日期: 2025-06-15 10:36:01
网页标题作为网页内容的"门面",直接影响着用户对页面的第一印象。针对特定信息采...

发布日期: 2025-04-26 18:34:34
网络设备日志如同设备发出的"心电图",交换机流量波动、防火墙策略拦截、服务器负...

发布日期: 2025-06-10 11:36:02
办公室空调吹得人手指发凉,第三次掏出数据线连接手机和电脑时,王工突然发现键盘...
发布日期: 2025-06-27 11:48:02
盛夏午后,某游戏公司运维部传来键盘敲击声。张工盯着屏幕上忽高忽低的延迟曲线,...
发布日期: 2025-05-24 11:36:01
在家庭宽带升级到千兆时代后,某互联网公司员工发现视频会议频繁卡顿。通过某款测...
发布日期: 2025-03-30 10:26:14
网络服务器每天产生海量请求日志,运维工程师打开日志文件时,常被密密麻麻的文字...

发布日期: 2025-05-19 13:21:01
在数据中心巡检时,工程师老张盯着监控大屏直皱眉——带宽使用率连续三天飘红,但...
发布日期: 2025-04-29 14:00:01
在数据采集场景中,代理池的稳定性直接影响爬虫效率。针对中小规模需求,一款轻量...

发布日期: 2025-03-23 12:20:01
随着企业网络架构复杂度提升,交换机、路由器等设备的配置文件合规性问题逐渐成为...

发布日期: 2025-05-10 12:35:41
网络卡顿的瞬间,多数人习惯打开测速软件。市面上工具种类繁多,但基于下载测试的...

发布日期: 2025-05-02 11:08:45
在数字化时代,网络连接的稳定性直接影响着工作效率与生活质量。当网页加载缓慢、...

发布日期: 2025-03-28 11:45:34
机房的红色警报灯突然闪烁,值班工程师的手机弹出三条告警信息:核心交换机端口丢...

发布日期: 2025-04-01 13:13:29
互联网时代的数据安全如同悬在头顶的达摩克利斯之剑。当云端存储成为主流,移动办...
发布日期: 2025-07-15 13:06:01
深夜赶项目时突然卡顿的在线会议,周末追剧时反复转圈的加载图标——网络波动总在...

发布日期: 2025-04-30 09:16:44
互联网时代,海量网页数据蕴藏着大量价值。如何快速定位目标链接并实现批量提取?...
发布日期: 2025-04-28 12:46:46
网络延迟就像数字世界的隐形路障,游戏卡顿、视频会议掉帧、文件传输中断等场景中...
发布日期: 2025-07-30 19:24:01
互联网数据以每秒数万次的速度更新,如何从海量网页中精准获取目标信息成为技术焦...

发布日期: 2025-05-06 13:28:41
俄罗斯方块作为风靡全球的经典游戏,其核心机制看似简单却蕴含精妙设计。借助PyG...

发布日期: 2025-04-12 15:56:34
网络端口扫描工具nmap作为开源安全领域的瑞士军刀,其功能覆盖网络探测、漏洞评估、...
发布日期: 2025-04-16 16:21:30
互联网数据指数级增长的今天,传统单机爬虫常面临IP封禁、效率瓶颈等问题。某电商...
发布日期: 2025-07-11 14:30:01
数据洪流时代,网络爬虫的效率直接影响着企业的决策速度。传统同步爬虫在应对千万...
发布日期: 2025-07-06 11:00:02
网络流量异常检测是网络安全运维的重要环节。面对日益复杂的攻击手段,传统阈值告...

发布日期: 2025-05-19 19:45:22
对于需要快速完成基础运算的用户而言,系统自带的计算器往往存在界面复杂、功能冗...

发布日期: 2025-04-26 19:17:14
网络流量监控领域近期迎来一款突破性工具——TrafficVision。这款软件以分屏显示为核心...
发布日期: 2025-07-01 09:18:01
爬虫开发者常陷入这样的困境:凌晨三点调试完代码,第二天却发现代理IP集体失效。...

发布日期: 2025-04-13 09:26:04
打开某个精心设计的网页时突然跳出的"404 Not Found",这种体验就像新买的衬衫发现掉了...
发布日期: 2025-07-15 19:06:02
网络防火墙作为企业安全防护的第一道闸门,规则配置的合理性直接影响着内网设备的...

发布日期: 2025-04-26 09:16:46
——基于Scrapy框架的新闻爬虫系统解析 新闻资讯的实时采集需求催生了多种网络爬虫解...
发布日期: 2025-06-13 12:48:01
本地硬盘堆满手动保存的网络图片?网页右键另存为效率太低?开源社区近期兴起一款...
发布日期: 2025-04-01 09:10:28
互联网时代,网络质量直接影响着工作娱乐体验。打开在线视频频繁缓冲、多人游戏频...
发布日期: 2025-07-13 16:48:03
随着网络文学内容分散在不同平台,许多读者面临跨平台追更、章节错乱或格式混乱的...

发布日期: 2025-04-25 16:17:14
工具简介 网络爬虫作为数据采集的核心工具,广泛应用于内容聚合、舆情分析、市场调...

发布日期: 2025-04-05 13:55:36
当我们需要快速获取特定网站公开数据时,基于Python的Requests+BeautifulSoup组合已成为技术...

发布日期: 2025-05-13 15:37:41
在网络游戏开发领域,传输协议的选择往往直接影响用户体验。传统基于TCP的猜数字游...
发布日期: 2025-06-02 16:09:01
网页爬虫技术在数据采集领域的应用日益广泛,但海量数据的存储路径管理问题常被忽...

发布日期: 2025-05-26 14:47:23
互联网时代,海量网页数据蕴藏着巨大价值。针对特定页面标题与链接的采集需求,技...
发布日期: 2025-05-06 18:57:30
网络运维领域近年来面临着一个显著痛点:海量数据流经复杂网络架构时,数据包丢失...
发布日期: 2025-07-03 11:54:02
在全球化信息交互场景下,跨语言数据采集成为企业市场研究的重要环节。某技术团队...

发布日期: 2025-06-05 15:06:02
网络带宽管理已成为现代企业及个人用户日常运维的关键环节。随着视频会议、云计算...

发布日期: 2025-04-28 16:03:36
在数据驱动的互联网时代,图片抓取成为许多开发者、数据分析师和内容创作者的基础...

发布日期: 2025-06-11 11:21:02
在信息爆炸的时代,网络数据采集逐渐成为许多从业者的刚需。传统爬虫工具往往需要...

发布日期: 2025-04-02 10:11:52
对于动漫爱好者来说,追番最头疼的问题莫过于错过更新。传统的手动刷新不仅效率低...

发布日期: 2025-05-17 10:46:34
在互联网信息爆炸的时代,如何快速获取指定网页的公开数据?这里推荐三款适合新手...
发布日期: 2025-06-06 12:48:03
互联网环境中每台设备每秒都在产生海量数据流,不同协议类型的数据包如同血管中的...
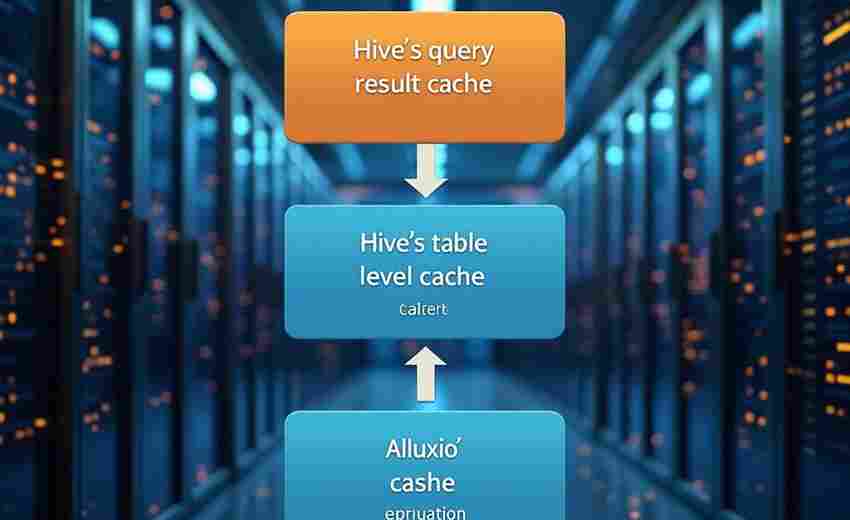
发布日期: 2025-04-07 13:26:14
网络通信开发领域存在一个经典练手项目:基于Socket和多线程的TCP聊天室。这个不足...
发布日期: 2025-06-09 13:00:02
网络论坛沉淀着大量用户生成内容,从产品反馈到行业讨论都具备研究价值。手动复制...

发布日期: 2025-06-05 11:00:02
清晨八点的办公室,市场部总监第五次刷新竞品网站的价格页面。这个动作他重复了三...

发布日期: 2025-05-21 15:55:00
在网络运维和信息安全领域,端口扫描器始终扮演着基础设施的角色。基于TCP基础连接...

发布日期: 2025-05-20 13:44:56
网络设备突发故障导致业务中断时,传统现场维护模式存在明显滞后性。某数据中心曾...

发布日期: 2025-06-15 16:42:01
网络信号不稳定、网页加载卡顿、设备频繁掉线——这些场景几乎每个人都遇到过。...

发布日期: 2025-04-16 16:50:10
网络带宽作为企业IT架构的血脉,其使用效率直接影响业务连续性。传统的人工巡检或...

发布日期: 2025-04-18 15:41:19
烈日当头的午后,技术部老张的咖啡杯见了底。市场部同事又催着要竞品网站的数据分...

发布日期: 2025-04-15 14:31:16
数据抓取工具正成为企业及开发者获取公开信息的效率利器。针对静态页面的爬虫工具...
发布日期: 2025-05-04 17:45:49
全球有超过2.5亿人使用Speedtest测试网络性能,而speedtest-cli作为其命令行版本,在技术圈...